|
www.tlab.it
Text Screening /
Désambiguïsations des Mots
Cet outil T-LAB vous permet
d'éditer n'importe quel fichier corpus (jusqu'à 30 Mb en taille) et
d'effectuer rapidement une série
d'opérations utiles aussi bien pour une première exploration de ses contenus que pour la
désambiguïsation de ses unités
lexicales spécifiques.
En particulier, cet outil produit rapidement une
série de listes et permet des
opérations du genre recherche /
remplace.
Les listes qui peuvent être obtenues sont les
suivantes:
a- mots avec leurs occurrences;
b- n-grammes de mots avec leurs
occurrences;
c- environnements verbaux des mots sélectionnés.
Les images ci-dessous montrent les opérations
possibles dans les trois cas (a-b-c).
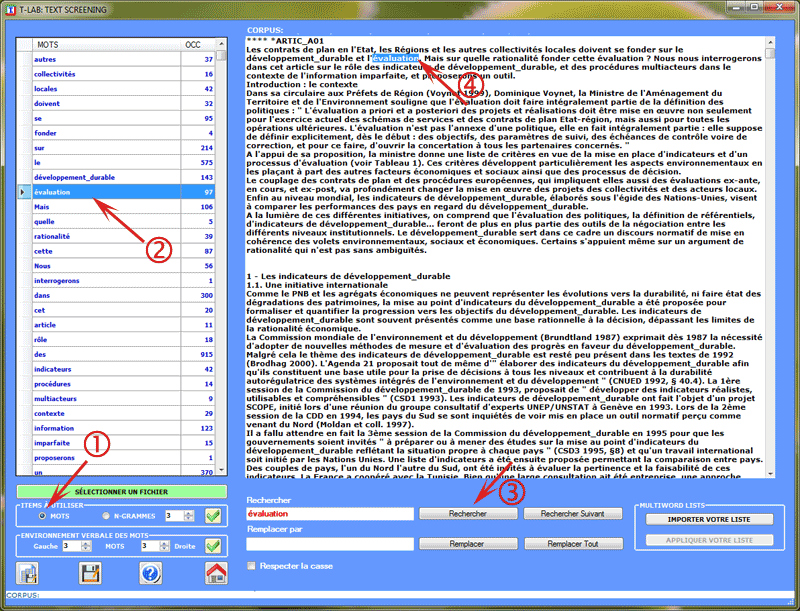
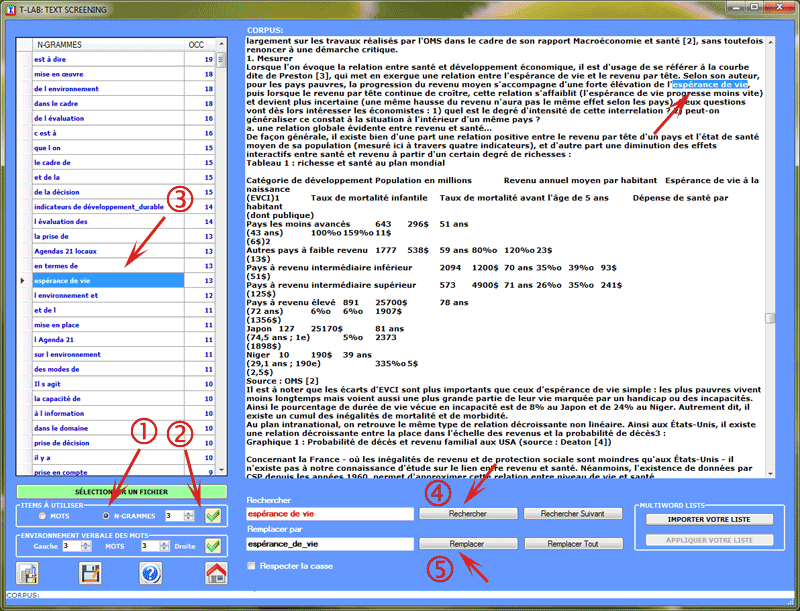
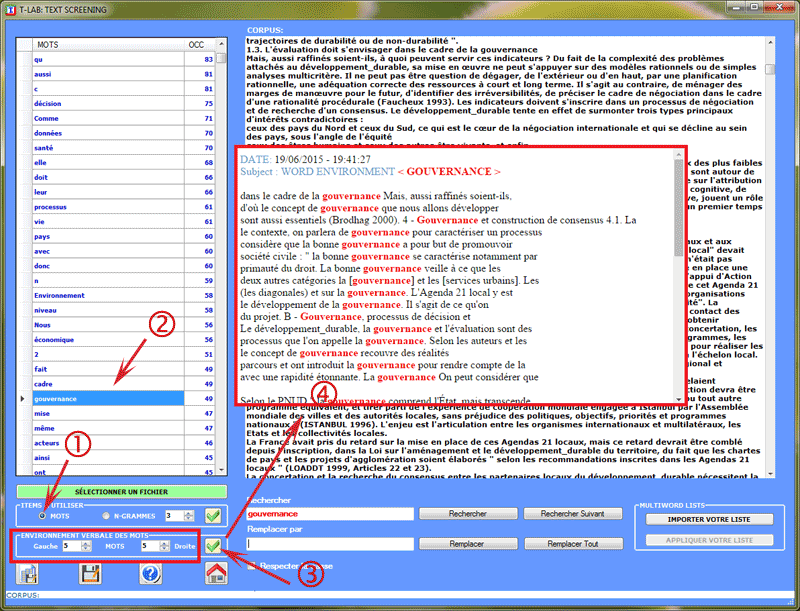
N.B.: Un clic sur le bouton en bas à gauche vous
permet d'exporter les listes a-b en tant que fichiers Excel.
Différemment, les listes 'c' sont automatiquement exportées en tant
que fichiers .html.
On peut également importer des listes personnalisées de
Multiwords et éventuellement les
appliquer au corpus affiché (voir images ci-dessous).
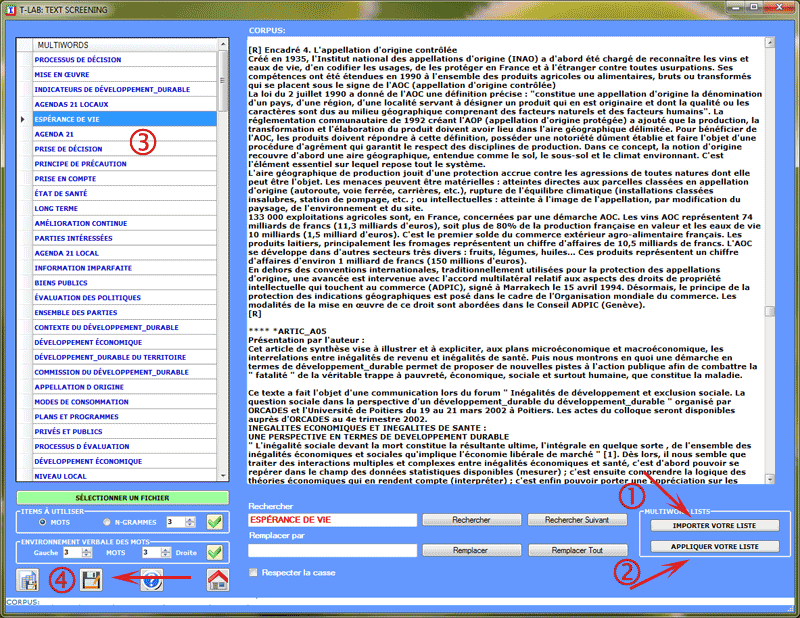
À la fin des opérations, si l'utilisateur a modifié le
texte et si il veut le sauver, T-LAB lui permet de créer un nouveau
fichier (corpus_dis.txt) qui, renommé de façon appropriée, peut
être importé et analysé (voir l'option 4 ci-dessous).
|


