|
www.tlab.it
Segmentation de
Mots
Cet outil T-LAB peut être utilisé avant d'importer
n'importe quel texte (*) chinois ou
japonais qui n'ait pas de délimiteurs,
c'est-à-dire des espaces et / ou bien des signes de ponctuation,
entre les mots.
(*) Le texte à traiter peut être constitué par un document unique
ou par une collection de documents qui incluent des variables
catégorielles.
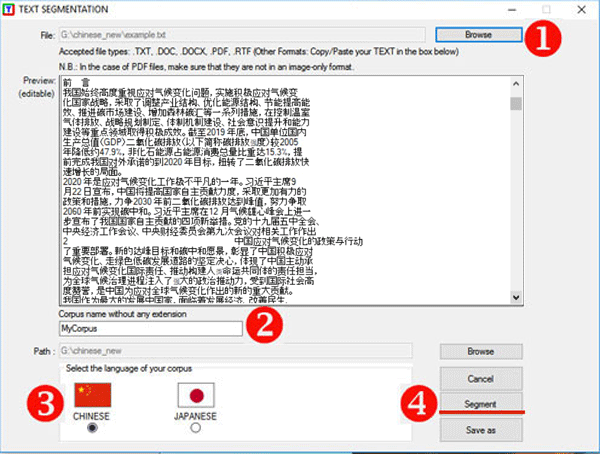
Son utilisation est très simple
(voir image ci-dessous):
(1) sélectionner un fichier quelconque;
(2) choisir le nom du projet;
(3) sélectionner la langue du texte;
(4) cliquer sur 'Segmenter'.
En résultat, des espaces vides seront ajoutés entre les
mots.
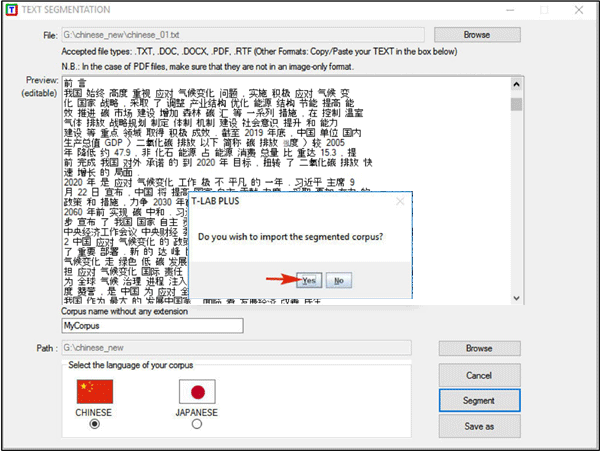
Successivement, si on veut procéder
à l' importation, il suffit de répondre 'OUI' à la question "
Veux-tu importer le corpus segmenté?" (voir image
ci-dessous).
N.B.: Lorsqu' on veut préparer un
corpus constitué par plusieurs textes qui comprennent les lignes de
codification (c'est-à-dire des variables catégorielles) on
conseille de procéder de la manière suivante:
1- 'Assembler' les textes non segmentés (*) au moyen de l' outil
Corpus Builder et 'Sauver' le fichier
corpus;
2 - Importer le corpus à peine créé au moyen de l' outil Text
Segmenter; ensuite procéder comme expliqué auparavant.
(*) Ceci signifie que ,quand on prépare le corpus , il n'est pas
nécessaire de segmenter chaque fichier à l' avance.
|


