|
www.tlab.it
Modélisation des Thèmes
Émergents
Cet outil T-LAB
vous permet de repérer, examiner et modeler
les principaux thèmes qui émergent des textes, aussi pour
ensuite les utiliser dans des analyses qualitatives (ex. faire des
grilles pour l'analyse de contenu) et quantitatives
ultérieures.
Les thèmes émergents, qui sont décrits à travers leur vocabulaire
caractéristique, c'est-à-dire à travers des ensembles de mots-clés
(lemmes ou catégories) co-occurrents dans les unités de texte
analysées, peuvent être en fait utilisés pour classifier ces dernières (ex. des documents ou des
contextes élémentaires) et obtenir de
nouvelles variables qui peuvent être utilisées dans des
analyses ultérieures.

Un boîte de dialogue T-LAB
(voir ci-dessus) vous permet de définir deux paramètres
d'analyse.
En particulier:
- le paramètre (A) permet de définir le nombre de thèmes à obtenir.
(Il convient de noter que plus ce nombre sera élevé plus cohérentes
seront les relations de co-occurrence dans chaque theme; en outre,
si nécessaire, certains themes - par exemple, ceux qui sont
redondants ou difficiles à interpreter - peuvent être éliminés plus
tard);
- le paramètre (B) vous permet d'exclure de l'analyse tous les
unités de contexte qui ne contient pas un nombre minimum de
mots-clés inclus dans la liste utilisée.
Seulement lorsque vous choisissez de personnaliser
tous les paramètres d'analyse (voir l'option "Oui" ci-dessus), la fenêtre suivante sera affichée
et plus d'options seront disponibles. (Notez que dans l'image
suivante, le nombre d'unités de contexte est déterminé par le
paramètre "B" dejà mentionné).

La procédure automatique
d'analyse consiste en les étapes
suivantes:
a - construction d'une matrice documents pour mots-clés, où les
documents sont toujours des contextes élémentaires correspondant
aux unités de contexte ( c.-à-d. fragments, phrases, paragraphes)
dans lesquelles le corpus a été subdivisé;
b - analyse des données avec un modèle probabiliste qui utilise la
"Latent Dirichlet Allocation" et le "Gibbs Sampling" (pour plus
d'informations consulter les articles correspondants sur Wikipedia:
http://en.wikipedia.org/wiki/Latent_Dirichlet_allocation;
http://en.wikipedia.org/wiki/Gibbs_sampling;
c - description de chaque thème à travers les valeurs de
probabilité associées à leur mots caractéristiques, que ce soit
spécifiques ou partagés par deux ou plusieurs thèmes.
A la fin du processus d'analyse, l'utilisateur pourra
aisément effectuer les opérations suivantes :
1 - explorer les caractéristiques de chaque thème
2 - explorer les relations entre les différents thèmes
3 - renommer ou éliminer des thèmes spécifiques
4- vérifier la cohérence sémantique des différents thèmes;
5 - tester le modèle et assigner les thèmes aux unités de contexte,
que ce soient documents ou contextes élémentaires.
6 - appliquer le modèle et créer une nouvelle variable
thématique;
7 - exporter un dictionnaire des catégories.
Dans le détail:
1 - Explorer les caractéristiques de
chaque thème
La première sortie à être visualisée (et qui vous pouvez
enregistrer) est un tableau avec un aperçu de tous les thèmes. Et,
quand vous le souhaitez, le même tableau peut être affiché en
utilisant le bouton "Aperçu" (voir
ci-dessous).
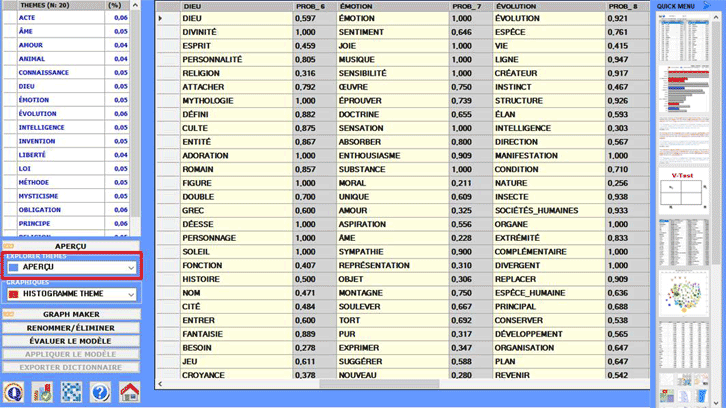
D'autres types de sortie sont accessibles en
sélectionnant l'une des options mises en surbrillance dans l'image
suivante.
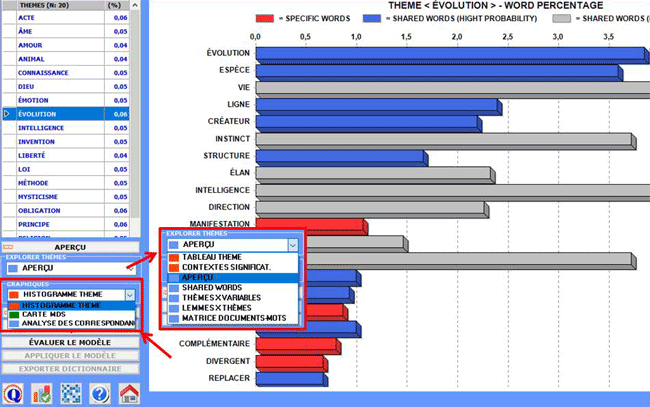
N.B.: Dans ce graphique "hight probability" indique une
probabilité >=.75.
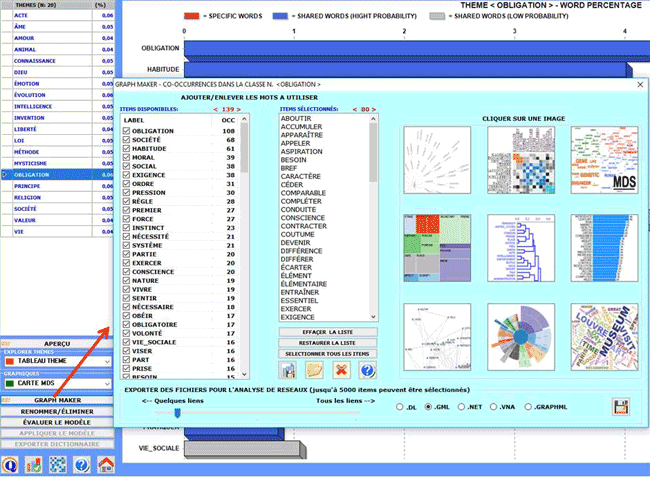
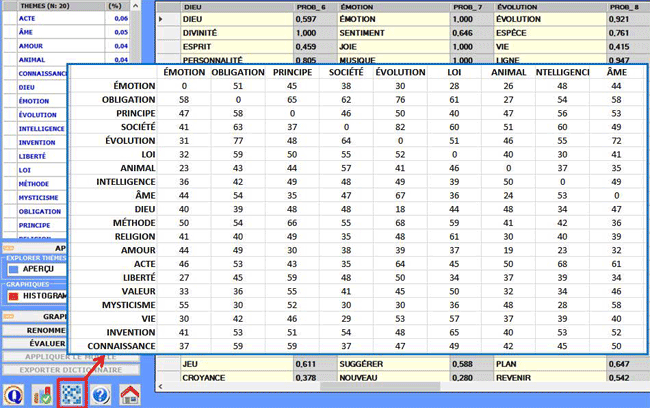
Lorsqu'un thème est sélectionné, en cliquant sur l'option
"Tableau Thème", vous pouvez vérifier ses caractéristiques. Aussi -
en cliquant sur un mot du tableau - une autre option devient
disponible qui vous permet de "supprimer" l'élément sélectionné (voir l'image
ci-dessous).
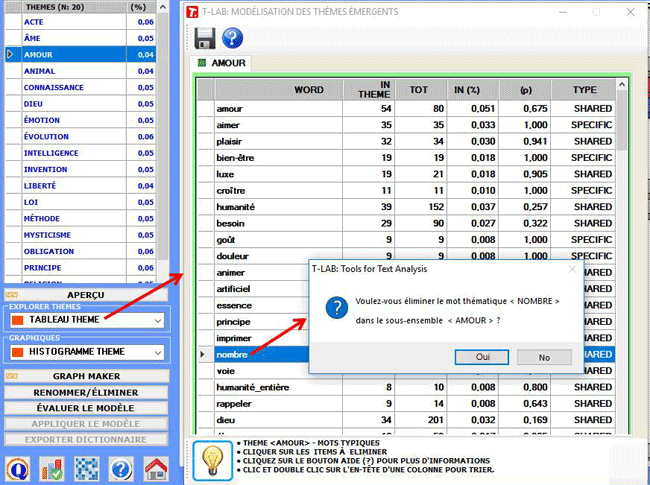
Les abréviations de ce tableau sont les suivantes:
IN THEME = occurrence (tokens) de chaque mot à l'intérieur du thème
sélectionné
TOT = occurrence (tokens) de chaque mot à l'intérieur du corpus ou
sous-ensemble analysé
IN (%) = poids en pourcentage de chaque mot à l'intérieur du thème
sélectionné
(p)= valeur de probabilité associée à chaque relation mot/thème
TYPE = est marqué specific quand le
mot (avec p=1) appartient seulement au thème sélectionné, et
devient shared dans les autres cas
(c'est-à-dire quand le mot est présent dans plus d'un
thème).
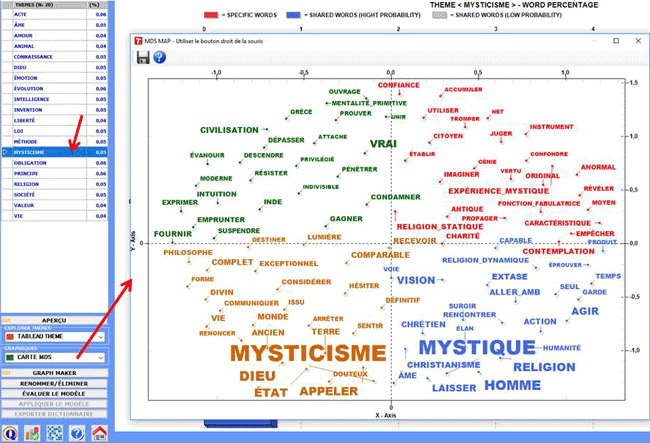
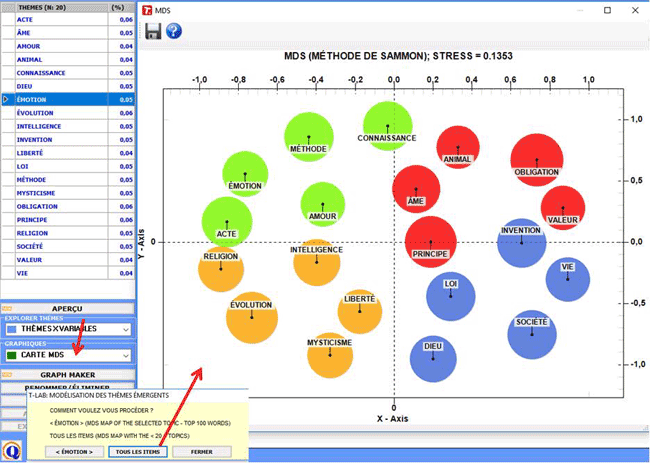
Lorsqu'un sujet est sélectionné, en cliquant sur l'option
"Carte MDS" vous pouvez facilement
explorer les relations sémantiques entre les mots qui sont plus
caractéristiques (voir image ci-dessous).
De plus, en utilisant l'outil 'Graph Maker', des options graphiques
supplémentaires deviennent disponibles (voir les images
suivantes).

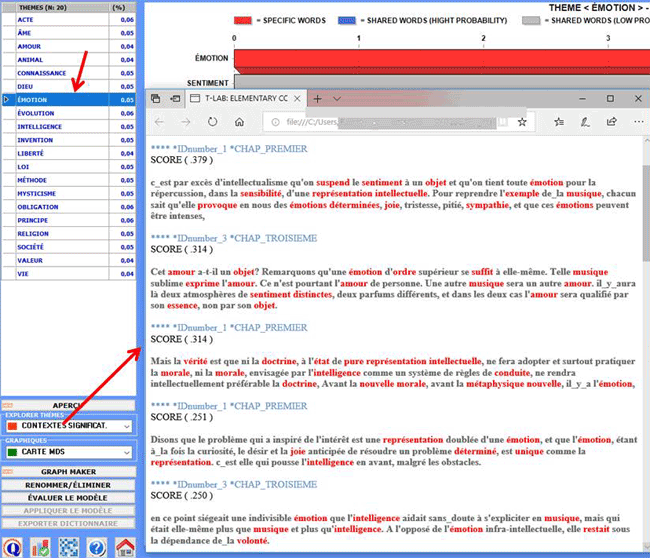
Lorsqu'un sujet est sélectionné, en cliquant sur l'option
"contextes significatifs", un fichier HTML est créé où les 20
principaux segments de texte (qui correspondent le mieux aux
caractéristiques du sujet) sont affichés (voir l'image
ci-dessous).
2 - Explorer les relations entre les
différents thèmes
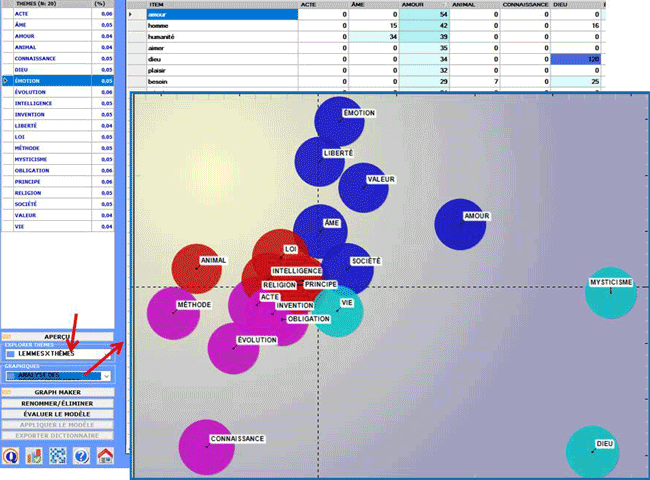
Avec l'outil Analyse de Correspondance,
vous pouvez créer et explorer deux types de tableaux de
contingence:
2.1) un tableau mots par thèmes (voir ci-dessous)
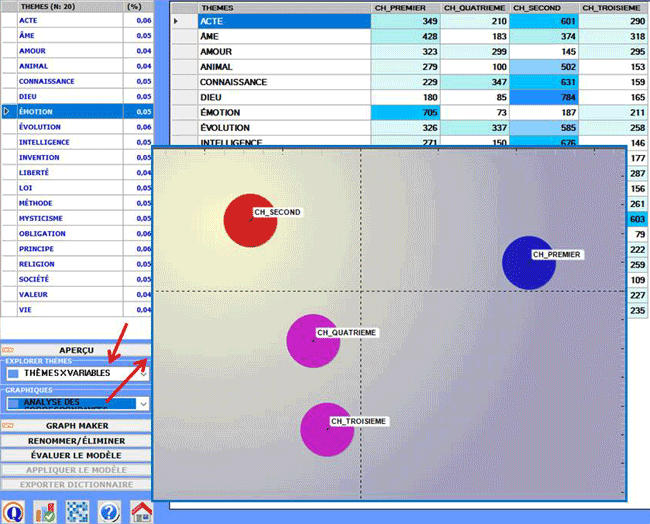
2.2) un tableau qui croise les thèmes avec les modalités
de la variable sélectionnée
Il y a également deux autres options graphiques
disponibles qui nous permettent de cartographier les relations
entre les différents thèmes / topics:
2.3) une carte MDS
2.4) certains diagrammes de réseau obtenu par
l'exportation / importation du tableau d'adjacence créé par
T-LAB (voir ci-dessous)
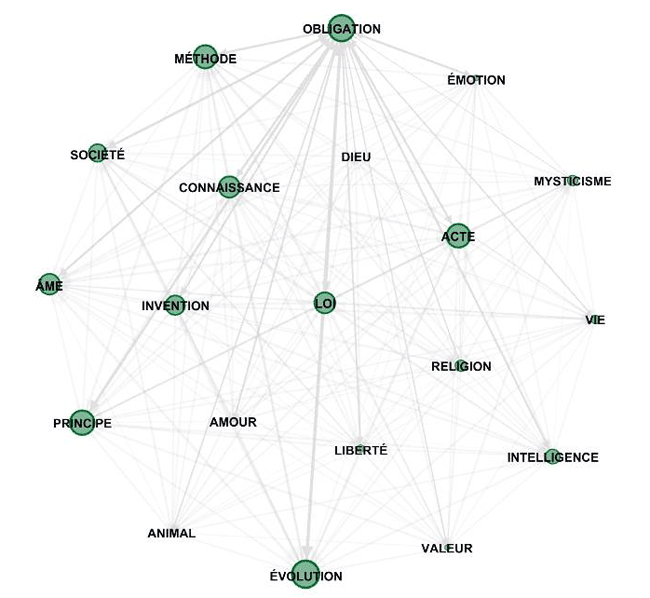
N.B.: le graphique précédent a été créé au moyen du
logiciel Gephi (https://gephi.org/ ), après avoir importé un
fichier T-LAB.
3 - Renommer ou éliminer des
thèmes spécifiques
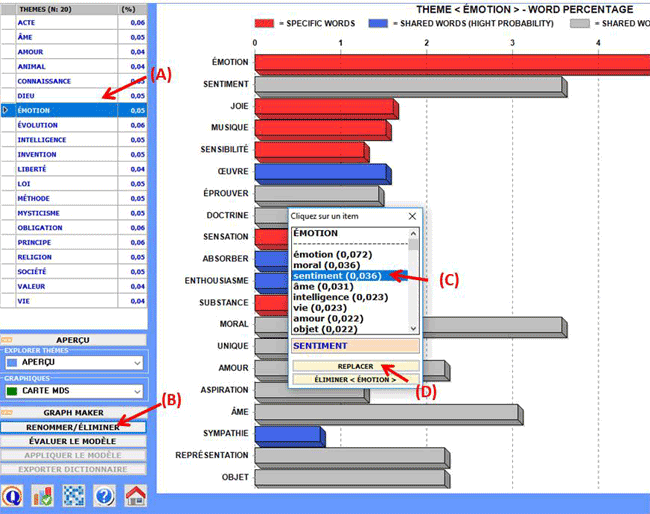
Pour renommer ou éliminer des thèmes spécifiques il suffit de
sélectionner les items correspondants (voir 'A' ci-dessous) et
cliquer sur le bouton "renommer/éliminer" (voir 'B'
ci-dessous).
Quand la boîte à options apparaît (voir ci-dessous), selon son
propre objectif, l'utilisateur peut changer la désignation du thème
(cela en choisissant parmi les mots disponibles ou en prenant un
nouveau, voir 'C' ci-dessus) ou bien éliminer le thème sélectionné
avec un clic sur le bouton correspondant (voir 'D'
ci-dessous).
4 - Vérifier la cohérence sémantique des
différents thèmes

Lorsqu' on clique sur le bouton 'Index de Qualité', T-LAB calcule les similarités entre les dix
premiers mots (top 10) caractéristiques de chaque thème. Plus
précisément:
- les 10 premiers mots sont ceux qui ont la plus grande valeur de
probabilité;
- les mesures de similarité sont calculées en utilisant le
coefficient du cosinus;
- comme dans le cas de l' outil Associations de Mots, le coefficient du cosinus
est calculé en vérifiant les cooccurrences de chaque paire de mots
à l' intérieur des segments de texte définis en tant que contextes
élémentaires.
En résultat, T-LAB crée un
fichier HTML où les 'k' thèmes sont énumérés avec leur index
correspondant de 'cohérence sémantique'.
N.B.: étant donné que les mesures de similitude varient suivant le
changement des mots sélectionnés, il est recommandé de répéter la
procédure chaque fois que l'un des dix premiers mots d' un thème
est supprimé par l'utilisateur.
5 - Tester le
modèle
A la fin de l'analyse des données (voir ci-dessus les points "A" et
"B"), chaque unité de contexte (ex. un document ou un contexte
élémentaire) est constituée d'un mélange de thèmes (ou sujets). Par
ailleurs le procès de classification utilisé pour tester/appliquer
le modèle assigne chaque unité de contexte au thème qui le
caractérise le plus. Il en résulte que, à ce point, chaque thème
devient de fait un cluster d'unités de contexte.
Pour cette raison quand l'option "Tester le Modèle" est sélectionnée,
T-LAB
crée deux fichiers XLS (voir ci-dessus) qui permettent à
l'utilisateur de vérifier l'appartenance de chaque unité de
contexte à un thème spécifique.

N.B.: dans le tableau ci-dessus, chaque document a une
valeur de probabilité associée à chaque theme.
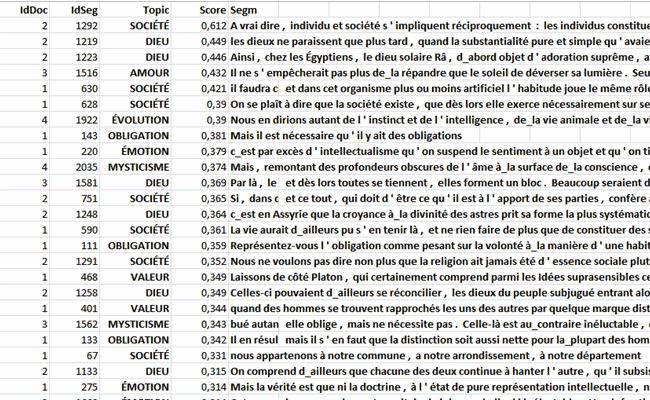
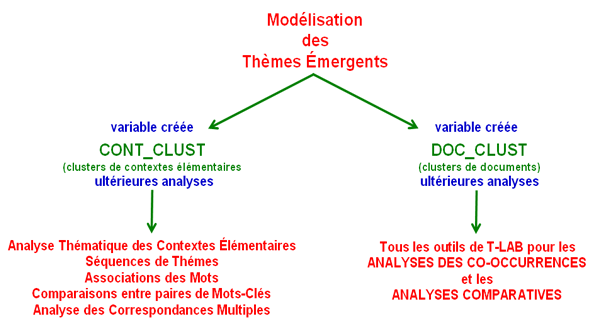
6 - Appliquer le modèle
Après avoir appliqué et
sauvegardé le modèle, tenant compte du fait que les thèmes sont
archivés par T-LAB
sous deux nouvelles variables qui se réfèrent à clusters de
contextes élémentaires ( CONT_CLUST)
et/ou à clusters de documents (DOC_CLUST), les relations entre ces mêmes thèmes
et/ou entre leurs caractéristiques pourront être ultérieurement
explorées avec divers instruments d'analyse (voir
ci-dessus).
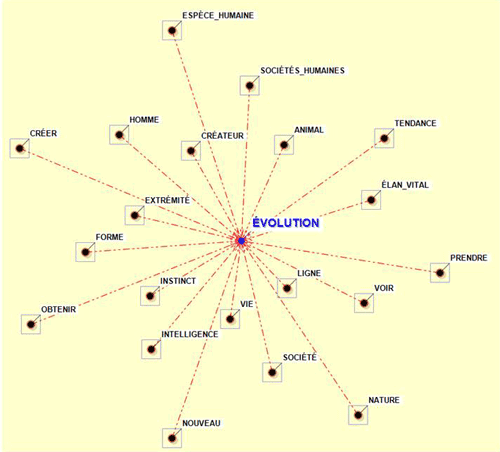
Par exemple, en utilisant l'outil Associations de Mots et en sélectionnant le
sous-ensemble (c.-à-d. le thème) "Evolution", vous pouvez créer le
graphique ci-dessous.
7 - Exporter un dictionnaire des
catégories
Lorsque cette option est sélectionnée, T-LAB crée un fichier dictionnaire avec
l'extension .dictio prêt à être
importé par l'intermédiaire d'un des outils pour l'analyse
thématique. Dans ce dictionnaire chaque catégorie est décrite à
travers ses mots caractéristiques.
|


