|
www.tlab.it
Contextes Clé de Mots
Thématiques
Cet outil
T-LAB peut être
utilisé pour deux buts différents:
a) extraire des ensembles d'unités de contexte qui
permettent d'approfondir la valeur thématique de mots-clés spécifiques;
b) extraire les unités de contexte qui résultent les plus
semblables à des textes échantillons proposés
par l'utilisateur.
Étape par étape, les
procédures respectives sont les suivantes:
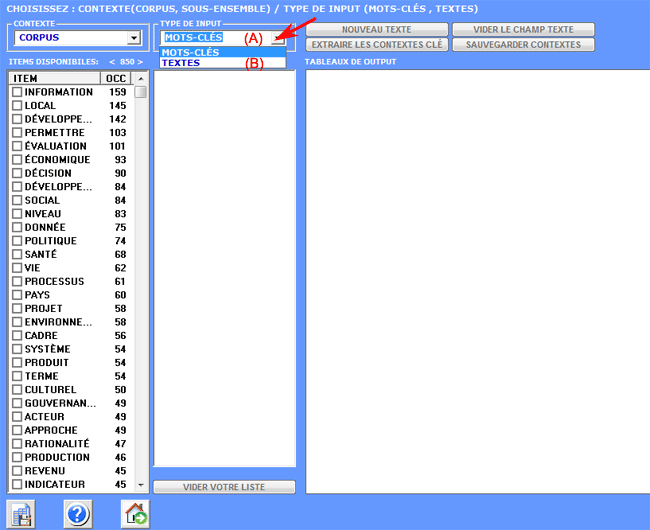
Case
(A)
1- l'utilisateur choisit
(double clic) un mot thématique "X" (voir ci-dessous);
2- T-LAB propose une liste de mots (maximum
50) dont les valeurs de co-occurrence avec "X" sont les plus
significatifs;
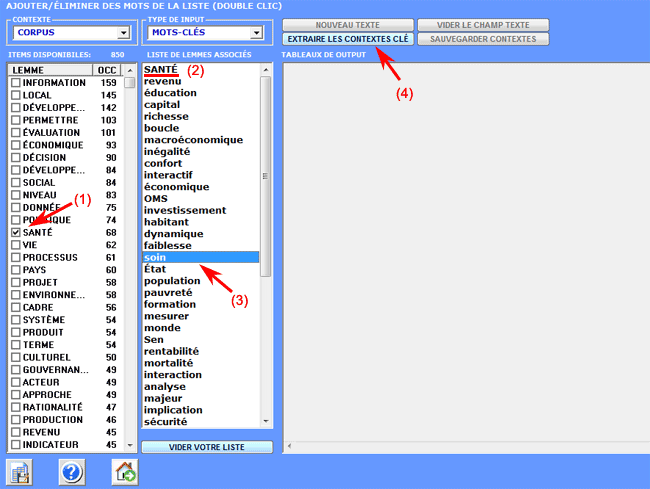
3- l'utilisateur peut enlever les items non pertinents de
la liste;
T-LAB assume que la liste sélectionnée est
un "query vector" et calcule ses index d'association (c.-à-d. les
coefficients de cosinus) avec tous les contextes élémentaires du
corpus ou du sous-ensemble
sélectionné;
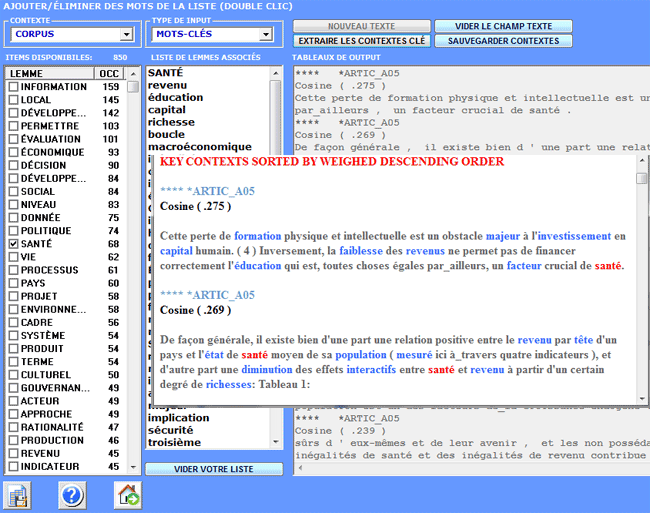
4- l'output est un fichier
HTML qui contient une liste des
contextes clé les plus significatifs de "X", énumérés par l'ordre
décroissant de leurs index d'association.
À la différence de Concordances, qui
permet l'extraction de tous les contextes élémentaires dans
lesquels les mots clés sélectionnés sont présents (occurrences), et
à la différence de Associations des Mots, qui permet l'extraction
de tous les contextes élémentaires dans lesquels les mots clés
sélectionnés sont accouplés (co-occurrences), cet outil nous permet
d'extraire les contextes élémentaires dans lesquels chaque mot clé
est associé à d'autres mots (co-occurrences multiples) définissant son champ
thématique.
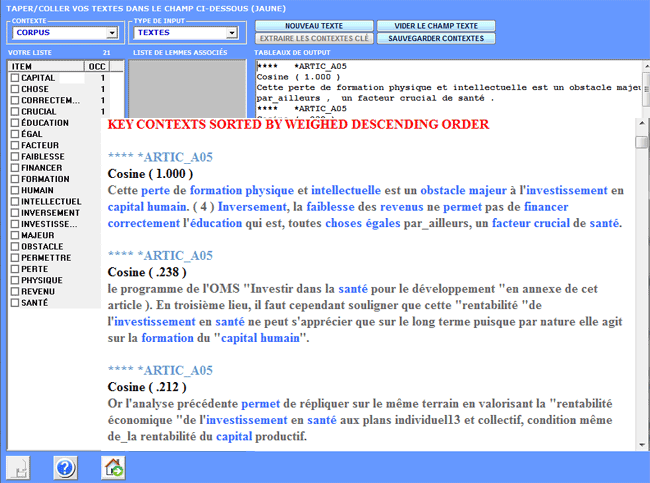
Les outputs, soit en format HTML que TXT contiennent une liste
des contextes clé de " X " les plus significatifs, énumérés dans
l'ordre décroissant de leurs indices d'association.
Les étapes 1-4 peuvent être réitérées pour "n" mots
thématiques.
Case (B)
Il fonctionne comme suit:
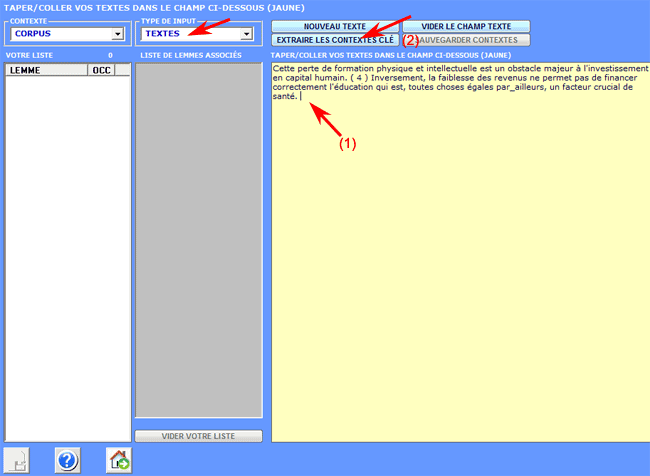
1 - l'utilisateur copie / colle
un texte "modèle" (max 5000 caractères) dans la case
correspondante;
2 - après avoir cliqué l'option
"extrait contextes clé ", T-LAB
transforme le texte introduit en un vecteur (query vector) et
calcule les indices d'association relatifs (c'est-à-dire les
coefficients cosinus) avec tous les contextes élémentaires du
corpus ou du sous-ensemble sélectionné
.
Les outputs, soit en format HTML qu'en format TXT
contiennent une liste des contextes clé qui sont les plus proches
au texte en input.
NB: Dans ce cas la mesure de similarité ne tient pas compte des
mots multiples dont les chaînes, avec ou sans le trait underscore
(" _ "), ne correspondent pas au texte analysé.
Les étapes 1-2 peuvent être réitérées pour "n" textes
"modèle".
|


