|
www.tlab.it
Corpus et
Sous-ensembles
Le corpus est un
ensemble des textes (un ou plus) rassemblés pour être
analysés.
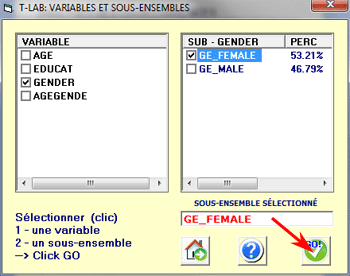
Chaque sous-ensemble
du corpus est défini au moyen d'une modalité de quelque variable.
T-LAB permet
d'explorer et d'analyser les relations entre les unités d'analyse
de tout le corpus ou de ses
sous-ensembles.
Quelques exemples de corpus:
- un texte
ou un document qui traite un sujet quelconque;
- un ensemble d'articles de journaux qui traitent le même
sujet;
- un ou plus entretiens effectués pour le même projet de
recherche;
- un ensemble de réponses à une ou plusieurs questions ouvertes
d'un questionnaire;
- une ou plusieurs transcriptions de focus-group.
Quelques exemples de sous-ensemble:
- un ou plusieurs chapitres d'un livre;
- un ou plusieurs articles de journal édités dans la même
année;
- une ou plusieurs entrevues avec la même catégorie de
personnes;
- un sous-ensemble de réponses à une question
ouverte.
N.B.: D'autres
sous-ensembles du corpus sont les "classes
thématiques" des documents ou des contextes élémentaires
obtenus en utilisant les outils correspondants de T-LAB.
Dans le cas d'un corpus composé de plus d'un texte,
afin d'en faire un ensemble correctement analysable, il faut que
toutes ses pièces aient deux caractéristiques qui les rendent
comparables:
a) une certaine homogénéité de leurs thèmes et/ou
du contexte dans laquel ils ont été produits, ceci dans le but
d'obtenir des données comparables entre elles;
b) un rapport équilibré entre leurs dimensions, en
termes d'occurrences ou en termes de K bytes, ceci dans le but de
ne pas encourir dans des anomalies statistiques.
Dans la logique de T-LAB, le corpus est une base de données
organisées en entrées (anglais : records) et en champs.
Avec plus de précision, les entrées se composent des entités
enregistrées (textes, segments de texte, mots) et les champs se
composent des étiquettes employées pour classifier les différentes
entités (les auteurs des textes, les contextes de référence,
etc.).
Voir La Préparation du
Corpus
|


