|
www.tlab.it
Vocabulaire du
Corpus
Cet outil T-LAB nous permet de vérifier le
vocabulaire du corpus de ses
sous-ensembles (voir option "1" ci-dessous).;en outre, il
nous fournit quelques mesures de la richesse
lexicale.
Le tableau Vocabulaire est une liste
comprenant tous les mots distincts (c.-à-d. "word types"), la
quantité de leurs occurrences (c.-à-d. "word tokens"), leur
lemmes correspondants et quelques
catégories employées par T-LAB (voir le Glossaire/Lemmatisation).
L'utilisateur peut choisir (voir
option "2" ci-dessous) les unités lexicales qui appartiennent à
chaque catégorie, consulter le tableau correspondant et l'exporter
comme fichier.xls (voir option "3" ci-dessous).
En outre, en utilisant le bouton droit de la souris, il
est possible de vérifier les concordances (Key-Word-in-Context) de
chaque mot (voir option "4" ci-dessous).
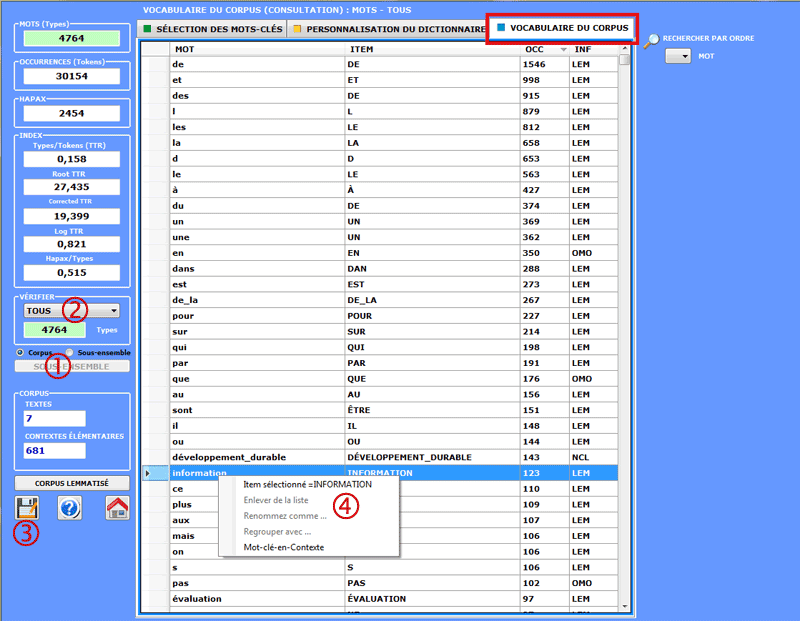
Les mesures de richesse lexicale sont
cinq:
Type/Token ratio (TTR) ;
Root TTR (Guiraud, 1960), obtenue en divisant le nombre des "types"
par la racine carrée du nombre des "tokens";
Corrected TTR (Carroll, 1964), obtenue en divisant le nombre des
"types" par la racine carrée de deux fois le nombre des
"tokens";
Log TTR (Herdan, 1960), obtenue en divisant le logarithme du nombre
des "types" par le logarithme du nombre des "tokens";
Hapax/Types ratio.
N.B.:
- Hapax (c.-à-d. Hapax Legomena) sont les mots utilisés une seule
fois dans le corpus;
- quand on analyse un sous-ensemble de corpus, toutes les mesures
de richesse lexicale n'incluent pas les mots
vides (c.-à-d. articles, prépositions,
etc.).
|


