|
www.tlab.it
Comparaisons entre paires de Mots-Clés
 N.B.: Les images de cette section font référence à une version
précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre, le bouton
droit sur les tableaux avec les mots-clés rend disponibles
des options supplémentaires.Un nouveau diagramme radial est disponible qui permet de
vérifier rapidement les différences entre les associations de mots
est aussi disponible.Une galerie d'images à accès rapide qui
fonctionne comme un menu supplémentaire permet de basculer entre
les différentes sorties en un seul clic.
N.B.: Les images de cette section font référence à une version
précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre, le bouton
droit sur les tableaux avec les mots-clés rend disponibles
des options supplémentaires.Un nouveau diagramme radial est disponible qui permet de
vérifier rapidement les différences entre les associations de mots
est aussi disponible.Une galerie d'images à accès rapide qui
fonctionne comme un menu supplémentaire permet de basculer entre
les différentes sorties en un seul clic.
Certaines de ces nouvelles fonctionnalités sont mises en évidence
dans l'image ci-dessous.
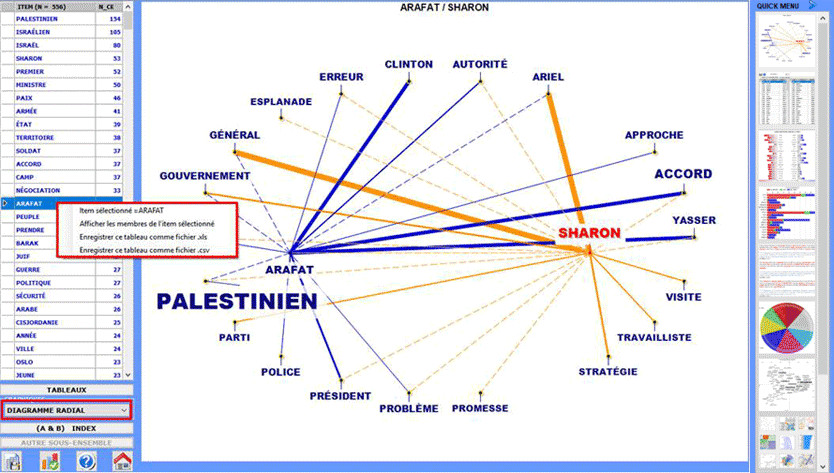
Cet outil T-LAB nous
permet de comparer des ensembles de contextes élémentaires (c.-à-d. contextes de
co-occurrence) dans lesquels sont présents les éléments d'une paire
de mots-clés.
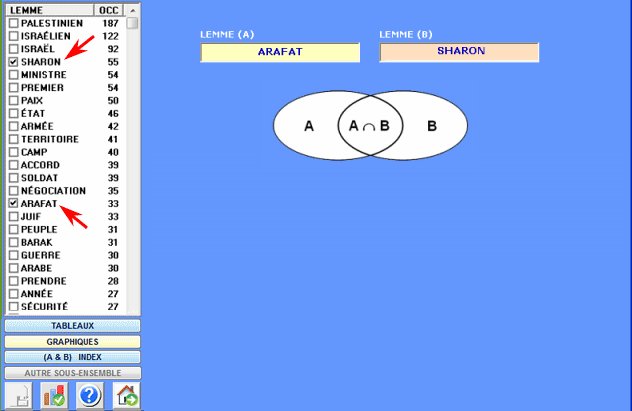
A gauche on trouve le tableau avec les lemmes sélectionnés et leur valeurs d'occurrence dans tout le corpus ou dans un de ses
sous-ensembles de lui.
L'utilisateur est invité à sélectionner l'un après l'autre, avec un
clic, deux d'entre eux (une "paire").
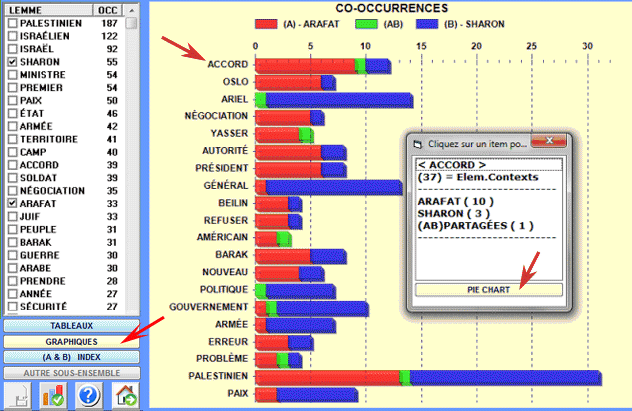
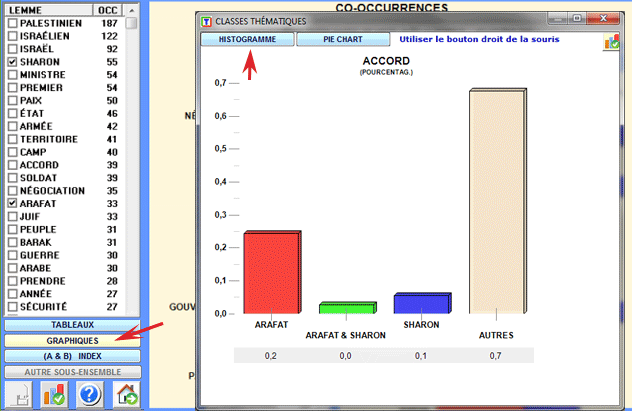
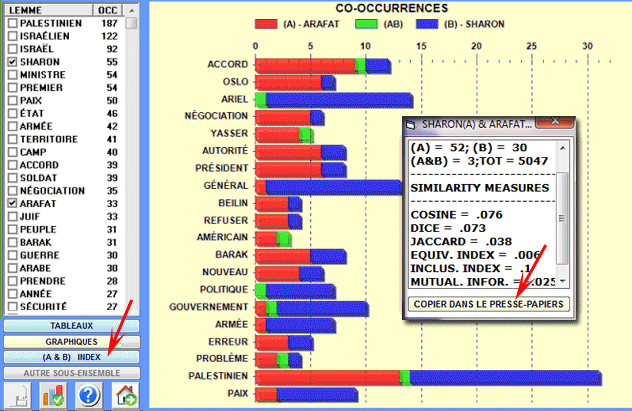
Un diagramme à barres (voir ci-dessous) nous
permet d'apprécier le nombre de contextes élémentaires dans
lesquels chaque lemme est en relation de co-occurrence avec le
mot-clé "A" (couleur rouge), avec le mot-clé "B" (couleur bleue) et
avec tous les deux (AB: couleur verte).
Avec un double-clic sur chaque étiquette du diagramme il est
également possible de vérifier les valeurs
correspondantes.
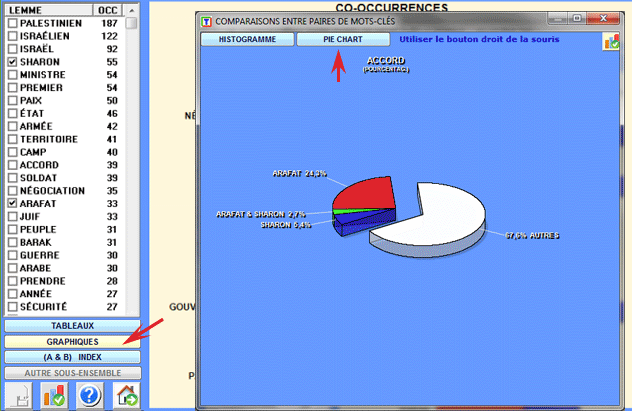
Les comparaisons proposées par T-LAB concernent les relations
entre les éléments de la "paire" et chacun des mots contenus dans
le tableau (voir ci-dessus).
Soit:
A = ensemble des contextes élémentaires
(TOT C.E. = 30) où le premier mot de la paire (par ex. "Arafat")
est présent;
B = ensemble des contextes élémentaires (TOT C.E. = 53)
où le deuxième mot de la paire (par ex. "Sharon") est
présent.
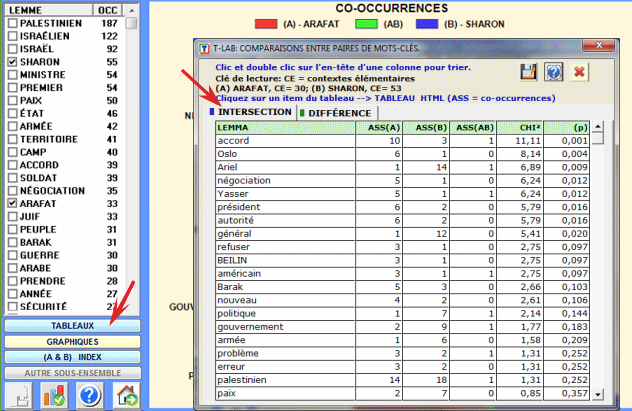
Le premier type de comparaison concerne les associations partagées (voir bouton intersection), c.-à-d. les mots qui sont présents
tant dans "A" que dans "B".
Dans le tableau (voir ci-dessus) chaque ligne montre les
valeurs correspondantes aux comparaisons de chaque lemme.
Les clés de lecture sont les suivantes:
- ASS (A) = nombre de contextes élémentaires dans lesquels
chaque lemme est en relation de co-occurrence avec (A);
- ASS (B) = nombre de contextes élémentaires dans lesquels
chaque lemme est en relation de co-occurrence avec (B);
- ASS (AB) = nombre de contextes élémentaires dans lesquels
chaque lemme est en relation de co-occurrence avec (A) et
(B);
- CHI2 = CHI-deux;
- (p) = probabilité associée à la valeur du
chi-deux (def=1).
Dans ce cas-ci, pour chaque mot-clé (par ex. "accord")
T-LAB construit un
tableau comme suit et il y applique le test du CHI Deux:
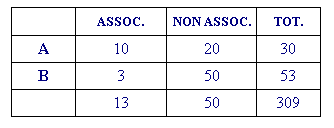
Dans la ligne (A) on indique le nombre de contextes
élémentaires dans lesquels le mot "accord" est présent (10) ou
absent (20) par rapport au total des contextes (30) propres du
premier mot de la paire ("Arafat").
Dans la ligne (B) on indique le nombre de contextes
élémentaires dans lesquels le mot "accord" est présent (3) ou
absent (50) par rapport au total des contextes (53) propres du
deuxième mot de la paire ("Sharon").
N.B.: dans ce cas, la valeur du CHI Deux correspond à
11,106.
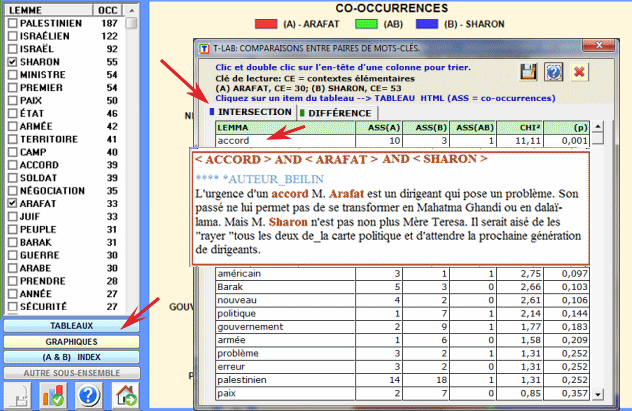
D'ailleurs un double-clic sur chaque item de la table
nous permet de sauver un dossier de HTML avec le nombre de
contextes élémentaires dans la colonne correspondante.
Le deuxième type de comparaison concerne les différences entre A et B (A - B e B - A).
Dans ce cas T-LAB propose deux tableaux avec
les Mots-Clés qui sont associés au premier terme de la paire ou au
deuxième de façon exclusive. Dans chacun des deux tableaux, la
colonne "TOT" indique le nombre de contextes élémentaires pour
lesquels chaque lemme n'est associé qu'avec un seul terme de la
paire.
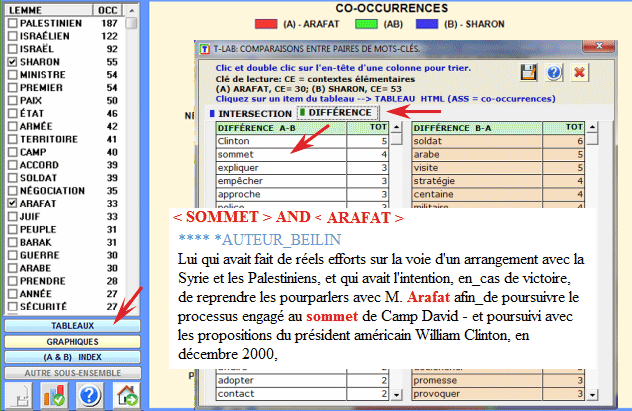
Enfin, en cliquant sur le bouton approprié, (voir l'image
suivante) il est possible de vérifier et d'exporter tous les index
de similarité qui concernent le couple de mots en examen.
|


