|
www.tlab.it
Décomposition en Valeurs
Singulières (SVD)
La Décomposition en Valeurs Singulières (SVD -
voir Wikipedia https://en.wikipedia.org/wiki/Singular-value_decomposition)
est une technique de réduction des dimensions des données qui, dans
le Text Mining, peut être utilisée pour découvrir les dimensions
latentes (ou composants) qui déterminent les similitudes
sémantiques entre les mots (c.-à-d. unités lexicales) ou entre
documents (c.-à-d. unités de contexte).
T-LAB nous permet
d'effectuer une SVD de trois types de tableaux de données.
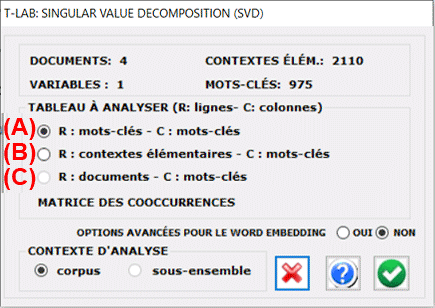
Dans le premier cas (voir 'A' ci-dessous), la table de données est
une matrice de cooccurrences avec - en ligne et en colonne - les
mots-clés sélectionnés. Dans le second cas (voir 'B' ci-dessous),
le tableau de données contextes élémentaires X mots-clés contiendra
des valeurs de présence / absence (c.-à-d. '1' et '0'). Dans le
troisième cas (voir 'C' ci-dessous), le tableau les données
documents x mots-clés contiendra des valeurs d'occurrence.
N.B.: Veuillez noter que, lorsque vous analysez une matrice de
cooccurrences dont les lignes et les colonnes sont des termes clés
(voir "A" ci-dessous), T-LAB
fournit des vecteurs denses de haute qualité (c'est-à-dire des word
embeddings).
La procédure d'analyse comprend les étapes suivantes:
1 - construction du tableau de données à analyser (jusqu'à 300 000
lignes x 5 000 colonnes);
2 - normalisation TF-IDF et mise à l'échelle des vecteurs de lignes
(norme euclidienne);
2 - extraction des 20 premières "dimensions latentes" à travers
l'algorithme de Lanczos.
N.B.:
- Dans le cas des matrices de cooccurrence (voir 'A' ci-dessus), la
normalisation des données est obtenue en utilisant la mesure du
cosinus;
- Lorsque les options avancées de word embedding sont
sélectionnées, T-LAB calcule les valeurs PPMI (Positive Pointwise
Mutual Information) et permet d'utiliser les 50 premières
dimensions du SVD.
Les résultats de l'analyse sont affichés dans des
tableaux et des graphiques.
En détail :
Deux tableaux - dont les lignes peuvent être des unités lexicales
ou des unités de contexte - ont autant de colonnes que les
dimensions extraites.
Dans le cas du tableau LEMMES (c'est-à-dire unités
lexicales), une autre colonne s'affiche, dans laquelle les scores
d'importance sont rapportés (voir ci-dessous).
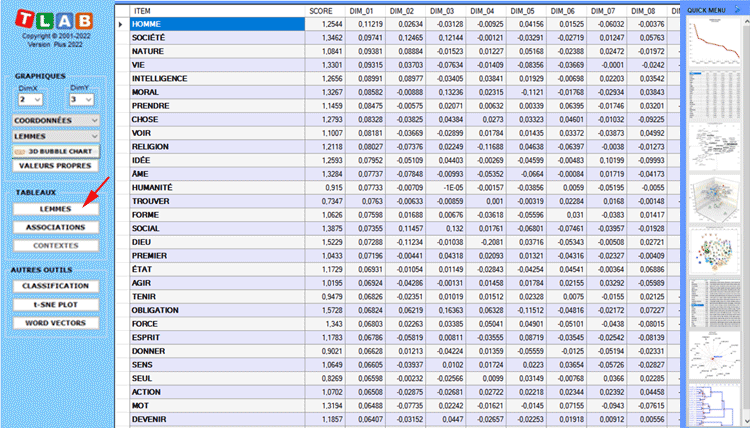
N.B.: Le score d'importance de chaque lemme est
calculé en additionnant les valeurs absolues de ses 20 premières
coordonnées (c.-à-d. les vecteurs propres), chacune étant
multipliée par la valeur propre correspondante.
Tous les tableaux peuvent être triés par ordre
croissant ou décroissant en cliquant sur un en-tête de colonne
quelconque.
Pour exporter n'importe quelle tableau, utilisez simplement
le clic droit de la souris lorsque les données sont affichées.
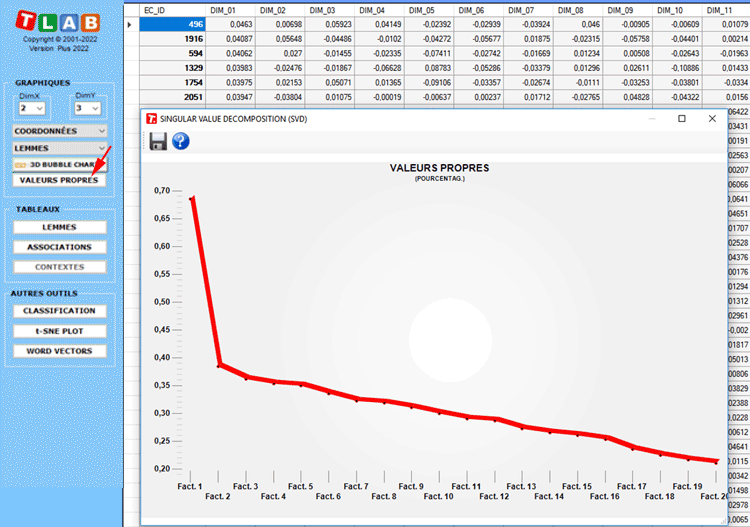
Veuillez noter que la première fois qu'un tableau est exporté, les
valeurs propres sont également exportées. De cette façon,
l'utilisateur peut évaluer le poids relatif de chaque dimension,
c'est-à-dire le pourcentage de variance expliqué.
En cliquant sur le bouton Associations, une autre
tableau s'affiche avec les mesures de similarité (c.-à-d. le
cosinus) de chaque mot-clé. De plus, lorsque vous cliquez sur une
ligne quelconque d'un tableau, un graphique s'affiche avec les
données correspondantes.
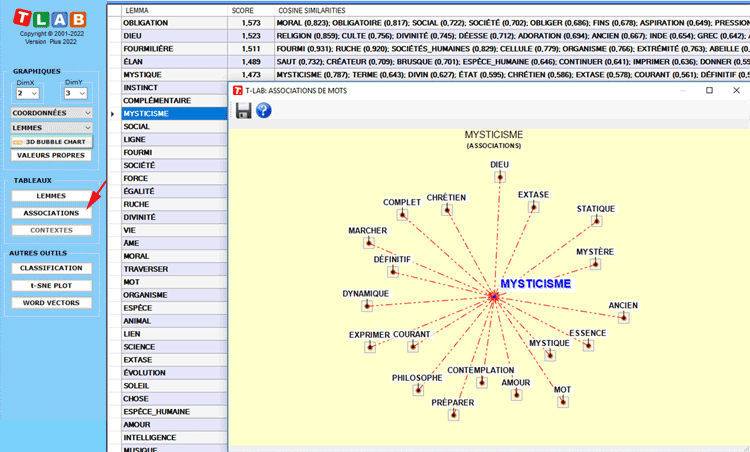
Le graphiques principal montre les relations entre
les mots-clés (c.-à-d. les lemmes) sur les dimensions sélectionnées
(voir ci-dessous).
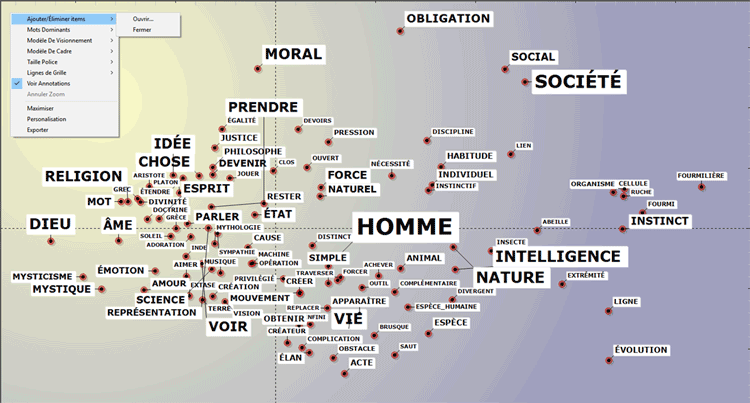
Par défaut, le tableau ci-dessus comprend les 100 lemmes
les plus importants. Cependant, l'utilisateur peut personnaliser le
nombre de lemmes et les caractéristiques du
graphique.
|


