|
|
T-LAB 10.2 - AIDE EN LIGNE |
|
|
www.tlab.it
Ce que T-LAB fait et ce qu' il vous permet de faire T-LAB est un logiciel composé par un ensemble d'outils linguistiques, statistiques et graphiques pour l'analyse des textes qui peuvent être utilisés dans les pratiques de recherche suivantes: Analyse du Contenu, Sentiment Analysis, Analyse Sémantique, Analyse Thématique,Text Mining, Perceptual Mapping, Analyse du Discours, Network Text Analysis.
En fait, au moyen des outils T-LAB les chercheurs peuvent facilement gérer
les activités d'analyse suivantes: L'interface utilisateur est très conviviale et les textes à analyser peuvent
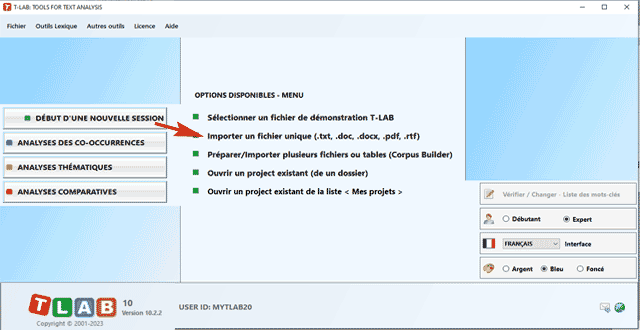
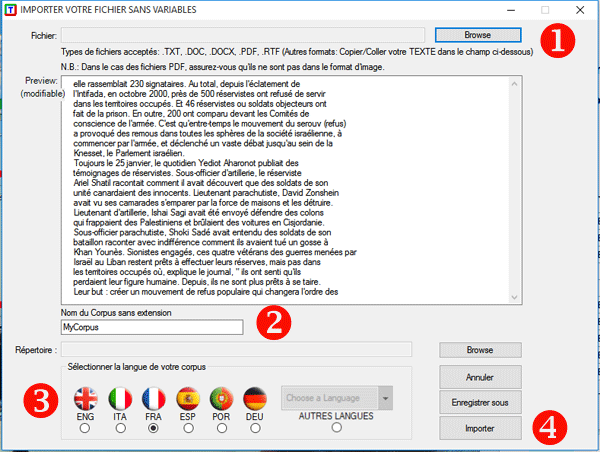
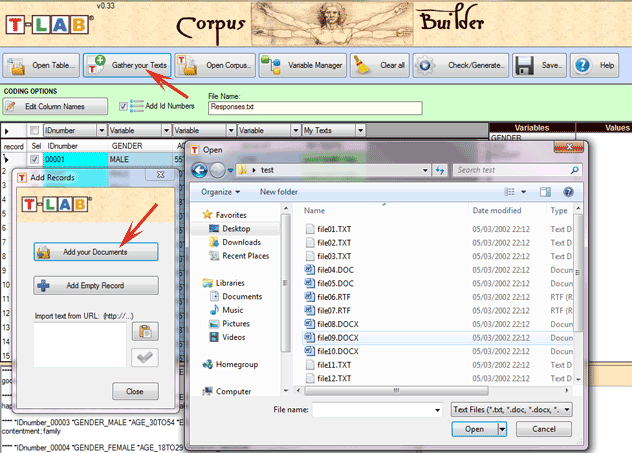
être des plus variés: Tous les textes peuvent être codifiés avec des variables catégorielles et peuvent inclure un identificateur (Unique Identifier) qui correspond à des unités de contexte ou à des cas (ex. réponses à des questions ouvertes). Dans le cas d'un seul document (ou un corpus considéré comme un texte unique) T-LAB ne nécessite pas de travail supplémentaire: il vous suffit de sélectionner l'option 'Importer un fichier unique ...' (voir ci-dessous).
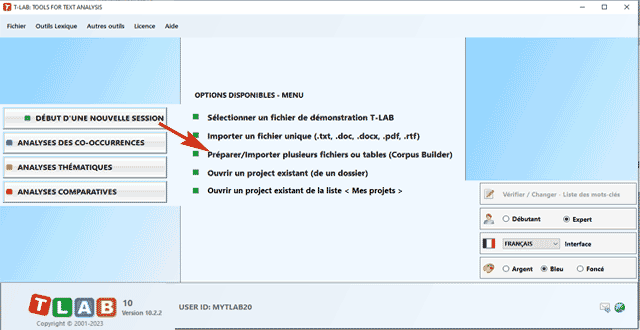
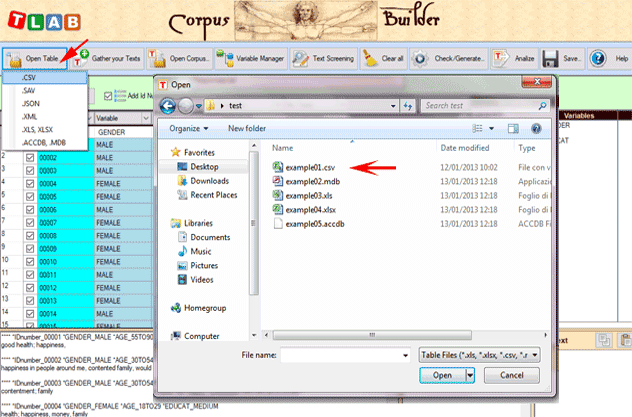
Différemment, dans les autres cas il faut utiliser le module Corpus Builder (voir ci-dessous) qui transforme automatiquement des documents textuels et différents types de fichiers (c'est-à-dire jusqu'à onze formats différents) dans un corpus prêt à être importé par T-LAB.
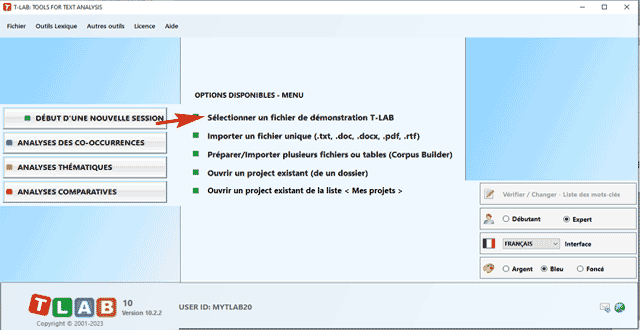
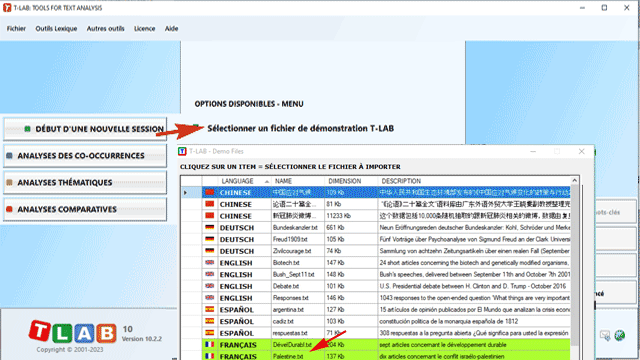
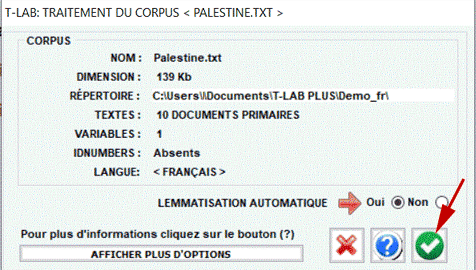
N.B.: En ce moment, afin d'assurer l'utilisation intégrée des différents outils, chaque fichier/corpus à analyser ne devrait pas dépasser 90 Mo (c' est-à-dire environ 55.000 pages au format .txt). Pour plus d'informations, voir la section Conditions requises et performances du Manuel Help. Six étapes suffisent pour explorer rapidement les fonctions du logiciel: 1 - Cliquer l'option "Sélectionner un fichier de démonstration...'
2 - Sélectionner un corpus à analyser
3 - Cliquer sur "ok" dans la première fenêtre de configuration
4 - Choisir un outil à l'intérieur d'un des sous-menus "Analyse"
5 - Examiner les résultats
6 - Utiliser l'aide contextuelle pour interpréter les graphiques et les tableaux.
Du point de vue externe, l'utilisation du logiciel est organisée par l'interface, c'est-à-dire par le menu principal, par les sous-menus et les fonctions qui les composent. D'un point de vue logique, en plus de l'interface usager, le système T-LAB est organisé par deux composantes principales:
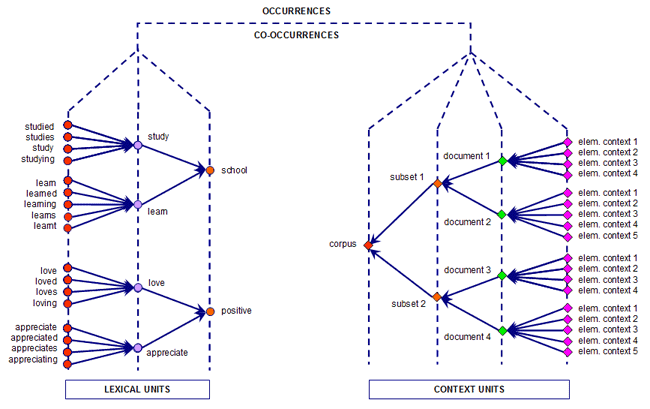
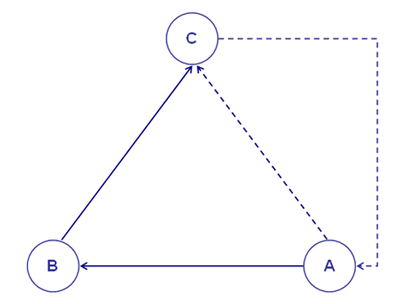
Pour comprendre comment T-LAB fonctionne et comment il peut être utilisé, il est fondamental de savoir clairement quelles unités d'analyse sont archivées dans son database et quels algorithmes statistiques sont utilisés dans les diverses analyses. En effet, les tableaux de données analysées sont toujours constitués de lignes et de colonnes dont les titres correspondent aux unités d'analyse archivées dans le database, alors que les algorithmes règlent les processus qui permettent de repérer des relations significatives entre les données et d'extraire des informations utiles. Les unités d'analyse de T-LAB sont de deux types: unités lexicales et unités de contexte. A - les unités lexicales sont des mots, simples ou multiples, archivés et classifiés sur la base d'un critère. Plus précisément, dans le database T-LAB chaque unité lexicale constitue un record classifié avec deux champs: mot et lemme. Dans le premier champ, appelé mot, sont listés les mots ainsi qu'ils apparaissent dans le corpus, alors que dans le second, appelé lemme, sont listés les labels attribués à des groupes d'unités lexicales classifiées selon des critères linguistiques (ex. lemmatisation) ou au moyen de dictionnaires et de grilles sémantiques définies par l'utilisateur. B - les unités de contexte sont des portions de texte dans lesquelles le corpus peut être subdivisé. Plus exactement, dans la logique T-LAB, les unités de contexte peuvent être de trois types: B.1 documents primaires,
correspondants à la subdivision "naturelle" du corpus (ex.
interviews, articles, réponses à des questions ouvertes, etc.), ou
bien aux contextes initiaux définis par l'utilisateur; Le diagramme suivant illustre les relations possibles entre les unités lexicales et les unités de contexte que T-LAB nous permet d'analyser.
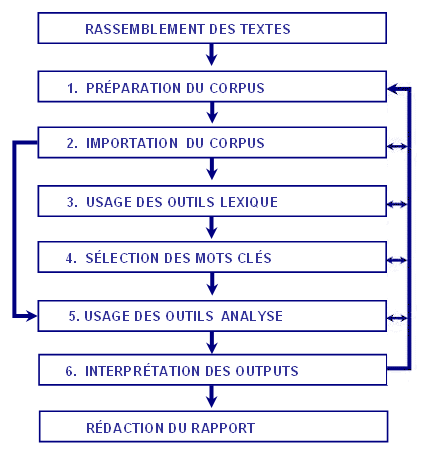
À partir de cette organisation du database, T-LAB permet - de façon automatique - d'explorer et d'analyser les relations entre les unités d'analyse de tout le corpus ou de ses sous-ensembles. Dans T-LAB, la sélection d'un quelconque instrument d'analyse (clic de la souris) active toujours un processus semi-automatique qui, grâce à quelques simples opérations, génère un tableau input, applique un algorithme de type statistique et produit quelques outputs. Un projet de travail "typique" dans lequel est utilisé T-LAB est constitué de l'ensemble des activités analytiques (opérations) qui ont pour objet le même corpus et est organisé par une stratégie et par un plan de l'utilisateur. Ainsi, il commence par le rassemblement des textes à analyser et s'achève par la rédaction d'un rapport. La succession des diverses phases est illustrée dans le diagramme suivant:
NB:
Dans le cas de textes uniques (ou corpus considéré comme texte unique) on n'a pas besoin d' autre travail. Autrement, si le corpus se compose de plusieurs documents primaires codifiés (variables et modalités), dans la phase de préparation on doit utiliser l'outil Corpus Builder, qui transforme automatiquement tout matériel textuel et divers types de fichiers (c.-à-d. jusqu'à dix formats différents) dans un fichier corpus prêt à être importé par T-LAB. N.B.:
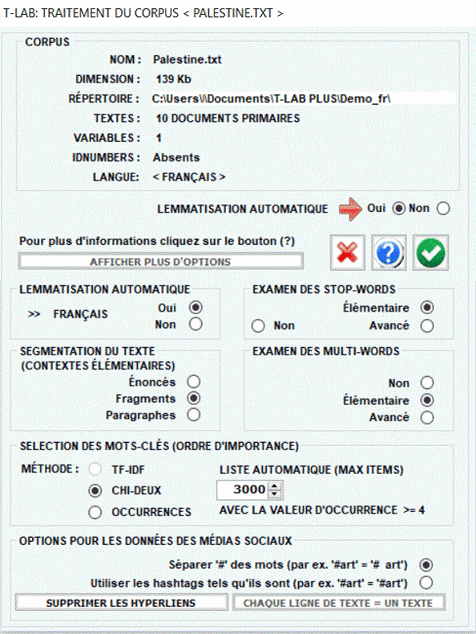
Pendant la phase d'importation du corpus, T-LAB effectue les traitements suivants:
De suite la liste complète des trente langues pour
lesquelles la lemmatisation automatique ou bien le processus de
stemming sont supportés par T-LAB. STEMMING: arabe, bengali, bulgare, danois, hollandais, finlandais, grec, hindi, hongrois, indonésien, marathi, norvégien, persan, tchèque, turc. En tout les cas, sans lemmatisation automatique et / ou en utilisant des dictionnaires personnalisés, l'utilisateur peut analyser textes dans toutes les langues, à condition que les mots soient séparés par des espaces et/ou des signes de ponctuation. À partir de la sélection de la langue, l'intervention de l'utilisateur (options avancées) est requise afin de définir les choix indiqués dans la fenêtre suivante.
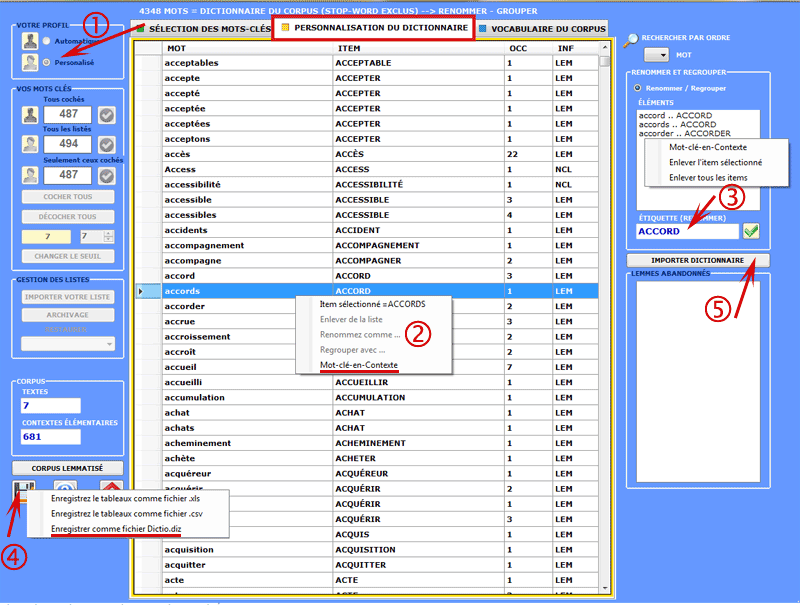
Les modalités des diverses interventions sont illustrées dans les rubriques de l'aide (et du manuel) correspondantes. En particulier on renvoie à la rubrique de l'aide (et du manuel) correspondante pour une description détaillée du processus Personnalisation du Dictionnaire.En effet, n'importe quel changement relatif aux voix du dictionnaire (par ex., le regroupement de deux ou plusieurs items) influe aussi bien sur le calcul des occurrences que sur celui des co-occurrences.
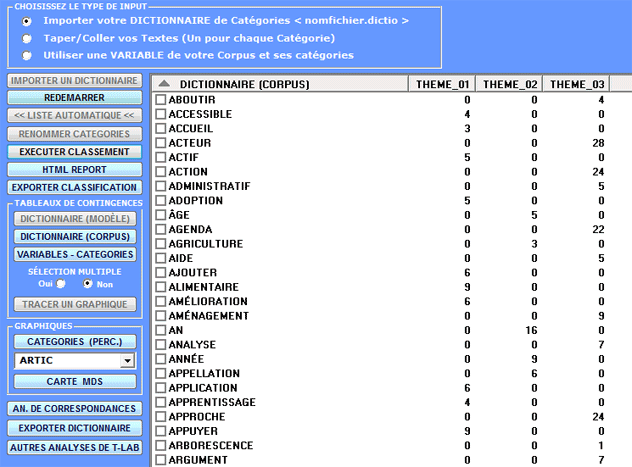
NB: Lorsque l'utilisateur, sans perdre aucune information lexicale, a l'intention d'appliquer des schémas de codage qui regroupent plusieurs mots ou lemmes dans peu de catégories (de 2 à 50), il est conseillé d'utiliser l'outil Classification Basée sur des Dictionnaires inclus dans le sous-menu Analyse Thématique(voir ci-dessous).
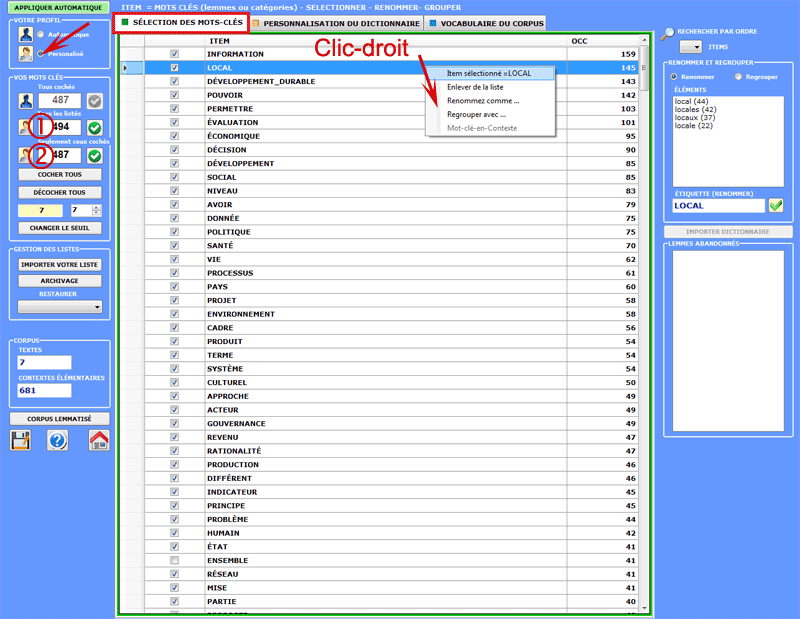
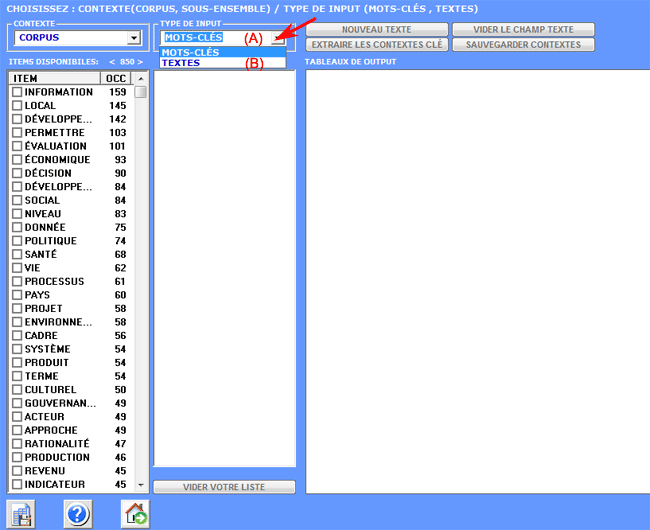
4 - LA SÉLECTION DES MOTS-CLÉS consiste en la prédisposition d'un ou de plusieurs listes d'unités lexicales (mots, lemmes ou catégories) à utiliser pour construire les tableaux données à analyser. L'option configurations automatiques rend disponible des listes de mots-clés sélectionnés par T-LAB; toutefois, puisque le choix des unités d'analyse est extrêmement important aux fins des élaborations successives, on conseille vivement l'utilisation des configurations personnalisées. De cette façon l'utilisateur pourra choisir de modifier la liste suggérée par T-LAB et/ou de construire des listes qui correspondent mieux à ses objectifs de recherche.
De toute façon, dans la construction de ces listes, valent les critères suivants: - vérifier l'importance
quantitative (total des occurrences) et qualitative (non banalité
du sens) des divers items; 5 - L'UTILISATION DES OUTILS D'ANALYSE est finalisée à la production d'outputs (tableaux et graphiques) qui représentent des relations significatives entre les unités d'analyse et qui permettent de faire des inférences. Au moment actuel T-LAB inclut vingt différents
outils d'analyse et chacun d'eux a sa propre logique; c'est-à-dire,
chacun d'eux emploie des algorithmes spécifiques et produit des
outputs spécifiques.
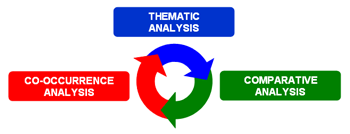
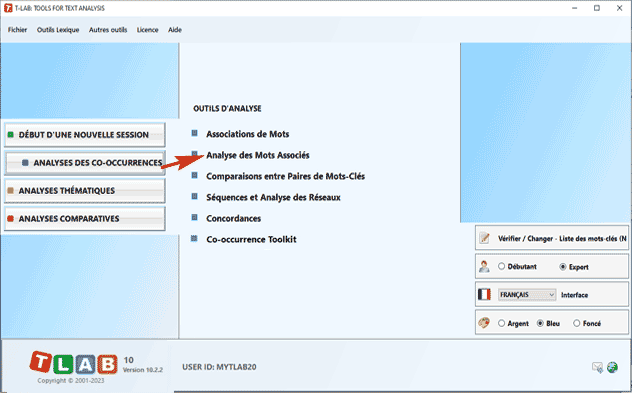
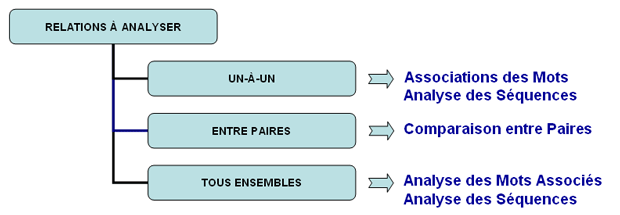
Toutefois, compte tenu du fait que l'utilisation des outils T-LAB peut être circulaire et réversible, nous pouvons identifier trois points de démarrage (start points) qui correspondent aux trois sous-menus ANALYSE:
Ces outils nous permettent d'analyser différentes typologies de relations entre les mots.
Voici quelques exemples (N.B. : pour plus d'informations
sur l'interprétation des outputs, veuillez vous référer aux
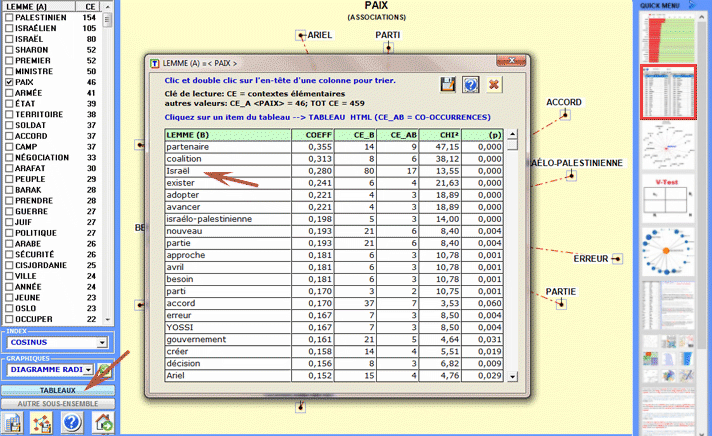
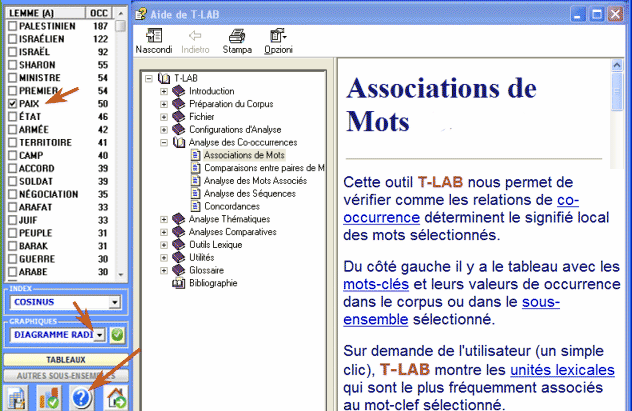
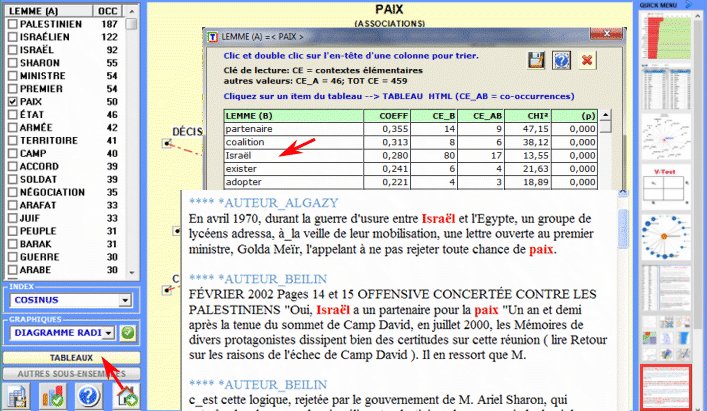
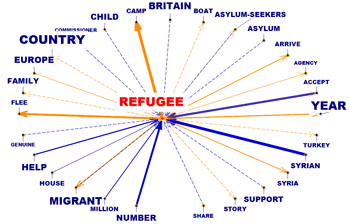
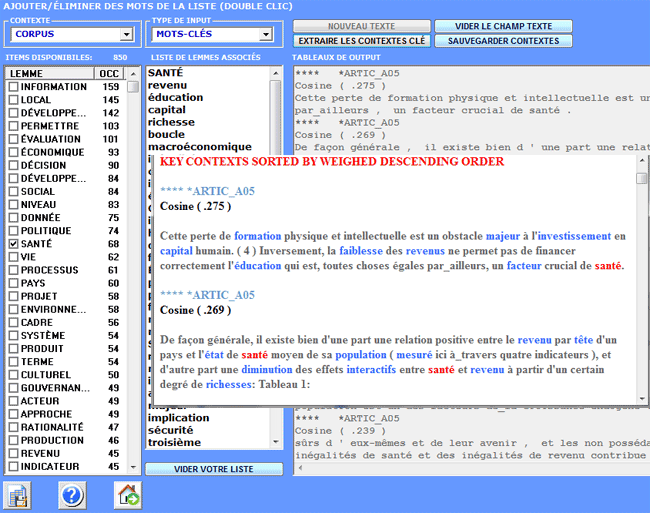
sections correspondantes du guide / manuel): Cet outil T-LAB nous permet de vérifier comment les relations de co-occurrence déterminent le signifié local des mots sélectionnés.
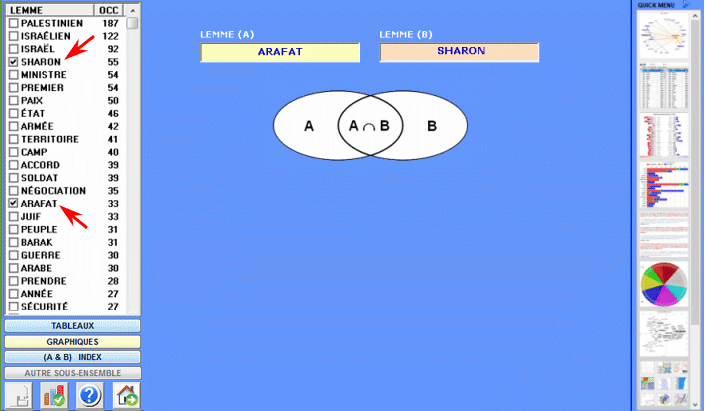
Cet outil T-LAB nous permet de comparer des ensembles de contextes élémentaires (c.-à-d. contextes de co-occurrence) dans lesquels sont présents les éléments d'une paire de mots-clés.
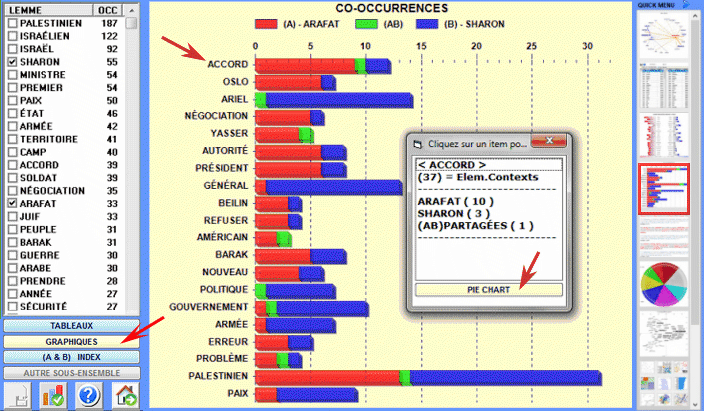
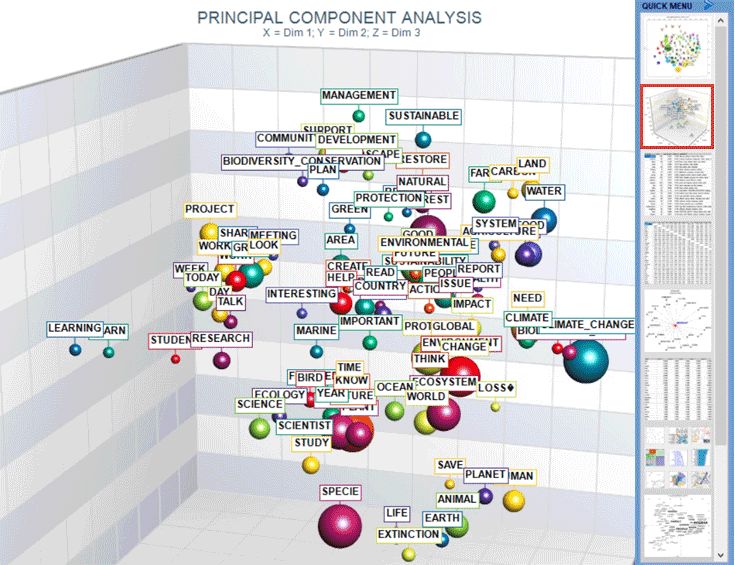
Cet outil T-LAB nous permet de cartographier les relations de co-occurrence entre les ensembles de mots-clés.
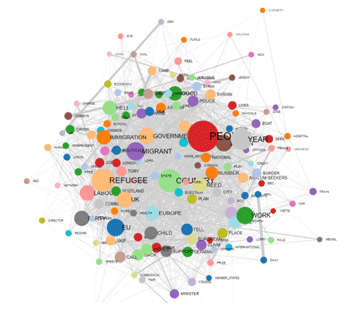
Cet outil T-LAB tient compte des positions des différentes unités lexicales à l'intérieur des phrases et il nous permet de représenter et d'explorer n' importe quel texte comme un réseau de relations. Ceci signifie, après avoir exécuté ce type d'analyse, que l'utilisateur peut vérifier les relations entre les nœuds du réseau (c'est-à-dire les mots-clés) à plusieurs niveaux: a) en relations du type un-à-un; b) à l'intérieur d' "ego network"; c) à l'intérieur des "communautés" auxquelles ils appartiennent; d) à l'intérieur du réseau entier constitué par le texte en analyse.
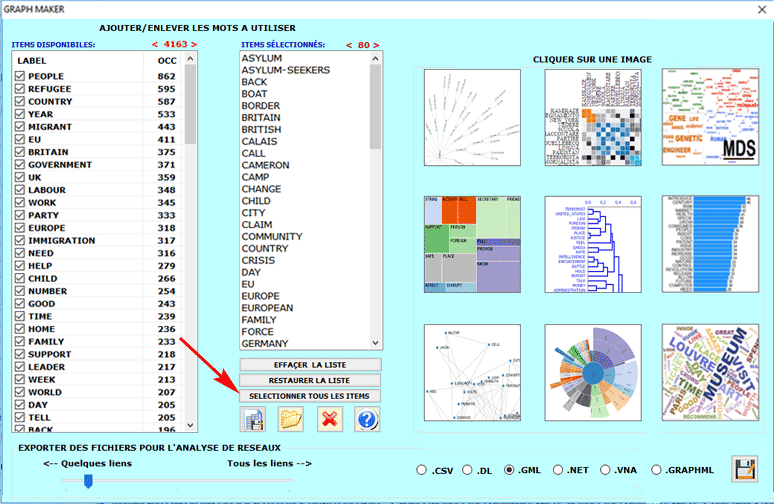
De plus, à n'importe quel moment, en faisant clic sur l'option GRAPH MAKER, l'utilisateur peut créer des différents types de graphiques en utilisant des listes personnalisées de mots-clés, (voir ci-dessous).
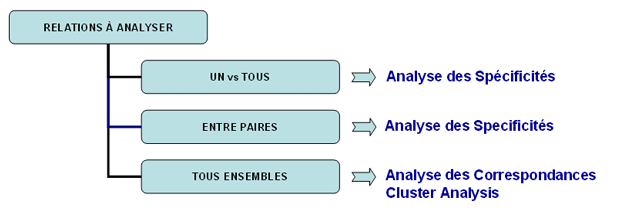
B : OUTILS POUR LES ANALYSES COMPARATIVES Ces outils nous permettent d'analyser différentes typologies de relations entre les unités de contexte.
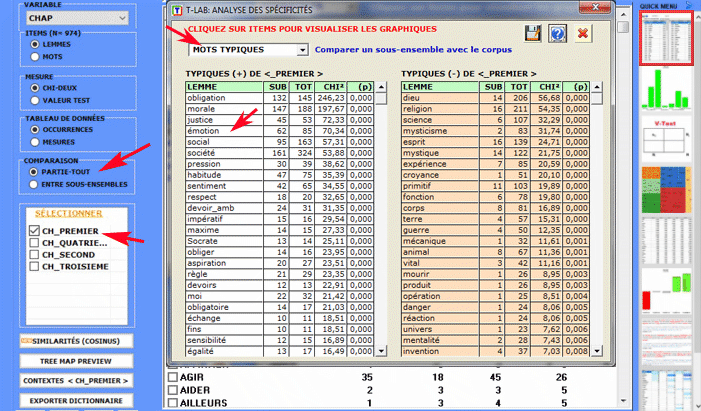
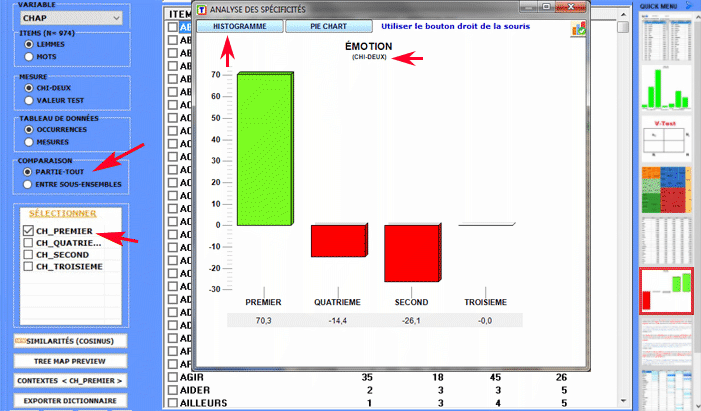
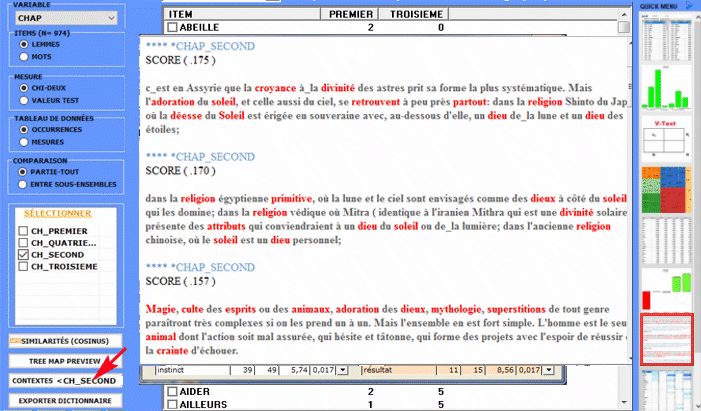
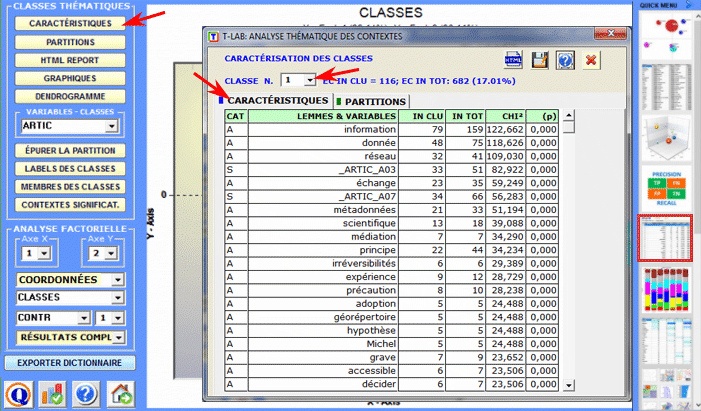
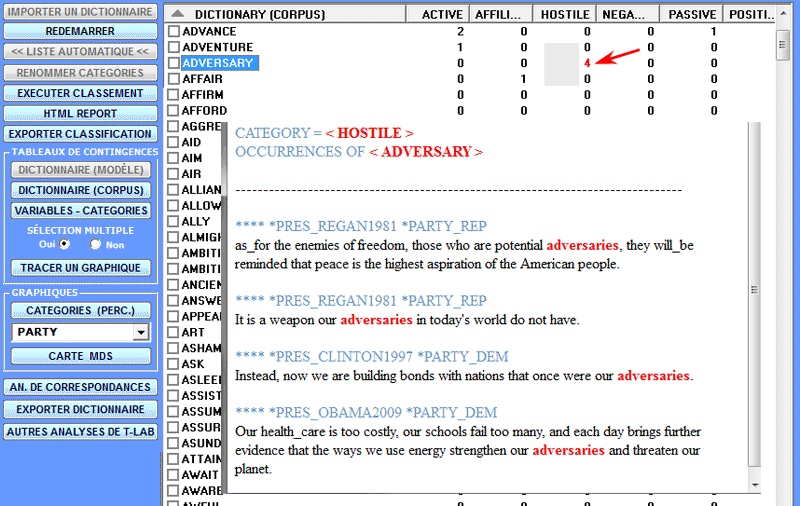
L'Analyse des Spécificités permet de vérifier quels mots sont "typiques" ou "exclusifs" de chaque sous-ensemble du corpus. En outre il nous permet d'extraire les contextes typiques, c'est-à-dire les contextes élémentaires caractéristiques, de chacun des sous-ensembles analysés (par exemple, les phrases "typiques" utilisées par certains leaders politiques).
L'Analyse des Correspondances permet d'explorer différentes typologies de relations (différences et ressemblances) entre les unités de contexte.
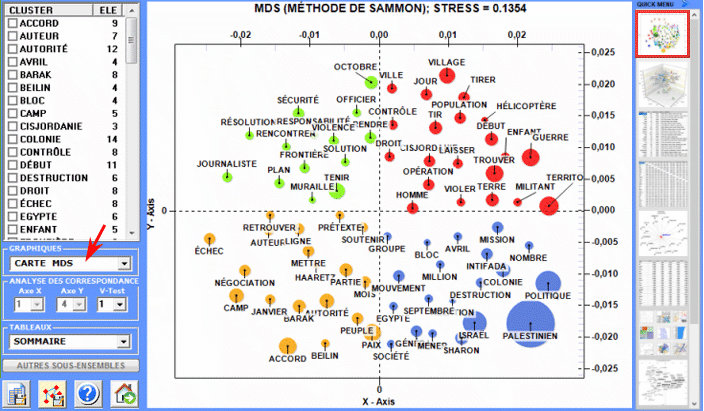
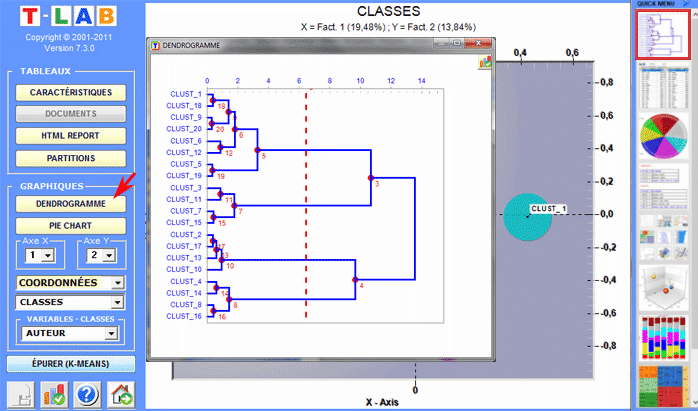
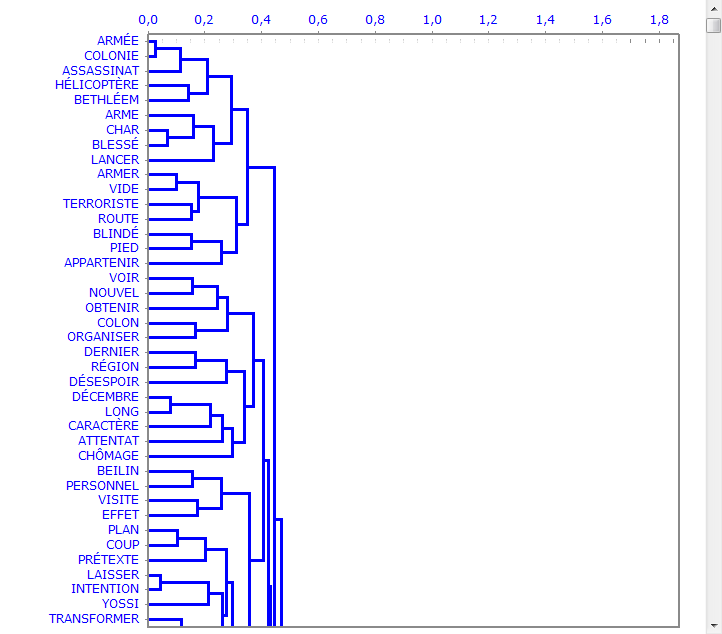
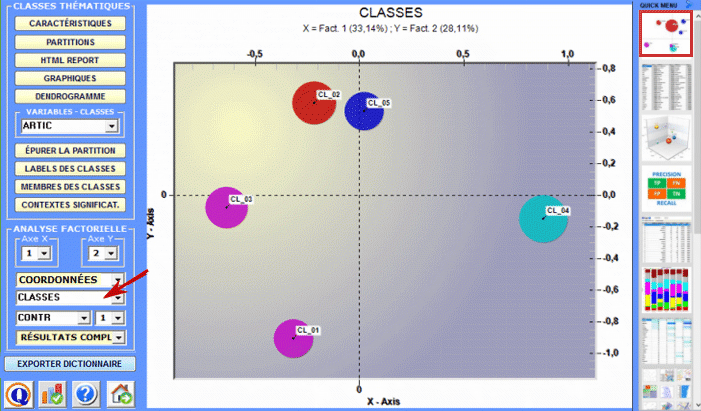
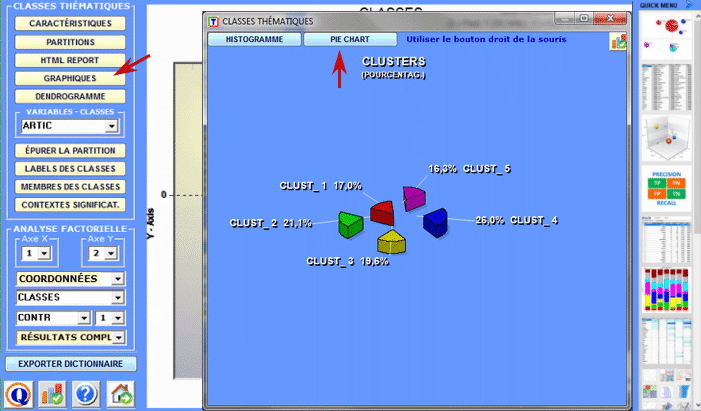
La Cluster Analysis, qui peut être réalisée avec différentes techniques, permet d'identifier des groupes d'unités textuelles qui aient deux caractéristiques complémentaires: maximum d'homogénéité dans leur interne et maximum d'hétérogénéité entre eux deux et les autres clusters.
C : OUTILS POUR LES ANALYSES THÉMATIQUES Ces outils permettent de
repérer, examiner et cartographer les "thèmes" présents dans les
textes analysés.
En détail, les façons dont T-LAB extrait les thèmes sont les suivantes: 1 - soit l'outil Analyse Thématiques des Contextes Elémentaires, soit l'outil Classification Thématique des Documents fonctionnent de manière suivante: a - ils réalisent une analyse des co-occurrences pour identifier les classes thématiques des unités de contexte;b - ils réalisent une analyse comparative pour confroner les profils des différentes classes; c - ils produisent différents types de graphiques et de tableaux (voir ci-après); d - ils permettent d'archiver les nouvelles variables obtenues (classes thématiques) et de les utiliser dans d'autres analyses.
2 - à l'aide de l'outil Classification Basée sur des Dictionnaires nous pouvons facilement construire / tester / appliquer des modèles (par ex. des dictionnaires de catégories) soit pour l'analyse classique du contenu soit pour la sentiment analysis. En effet cet outil nous permet d'effectuer une classification automatique de type top-down aussi bien des unités lexicales (c'est-à-dire mots et lemmes) que des unités de contexte (c'est-à-dire phrases, paragraphes et documents courts).
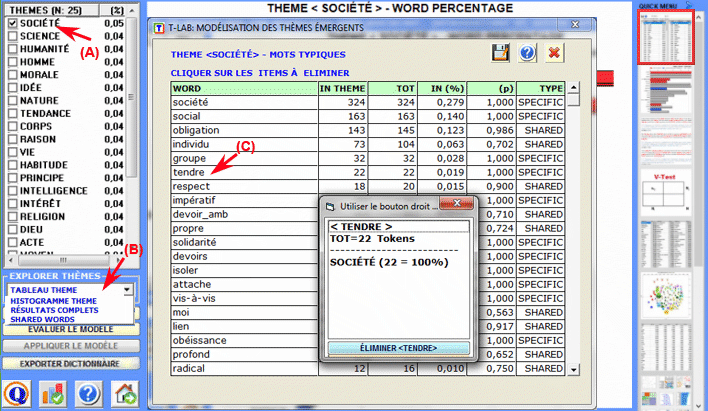
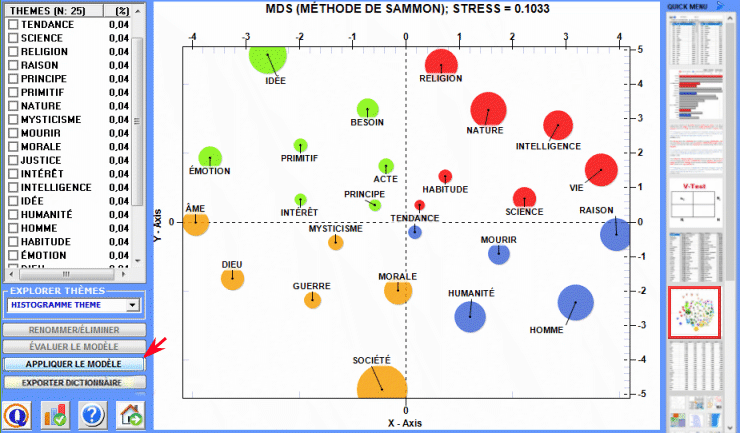
3 - grâce à l'outil Modélisation des Thèmes Émergents (voir ci-dessous) les composants du "mélange" thématique peuvent être décrits par leur vocabulaire caractéristique et peuvent être utilisés pour la construction de grilles pour l'analyse qualitative et / ou pour la classification automatique des unités de contexte (c'est-à-dire contextes élémentaires ou documents)..
4 - l'outil Contextes Clé des Mots Thématiques (voir ci-dessous) peut être utilisé pour deux buts différents: (a) extraire des listes d'unités de contexte (c'est-à-dire contextes élémentaires) qui permettent d'approfondir la valeur thématique de mots-clés spécifiques, (b) extraire des groupes d'unités de contexte qui sont semblables à n'importe quel texte "exemple" choisi par l'utilisateur.
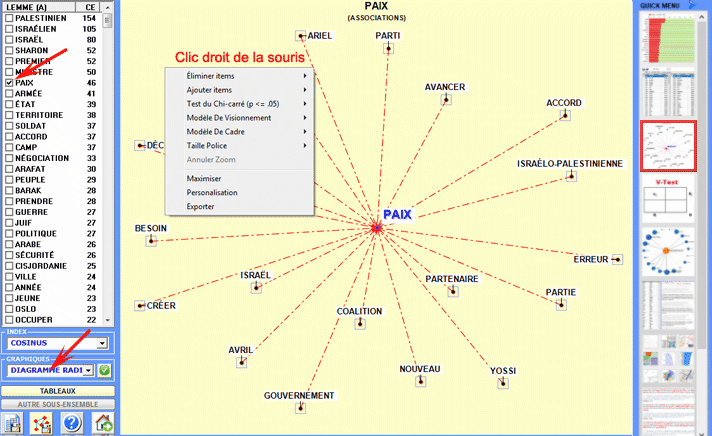
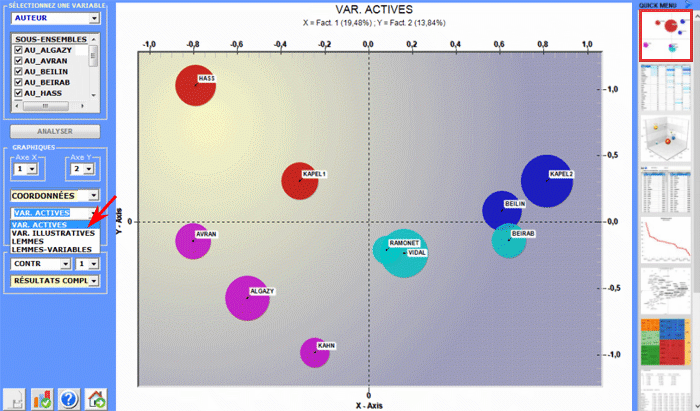
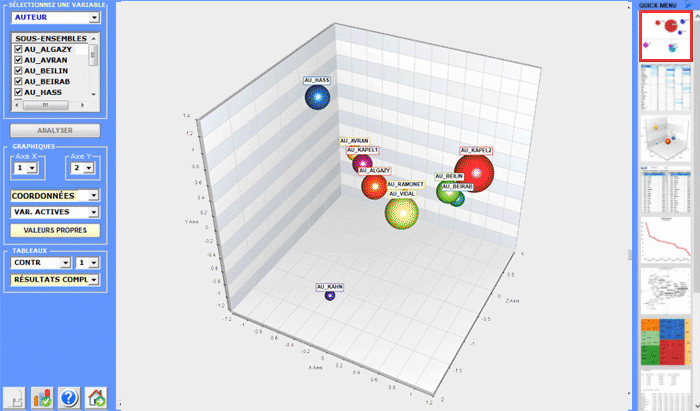
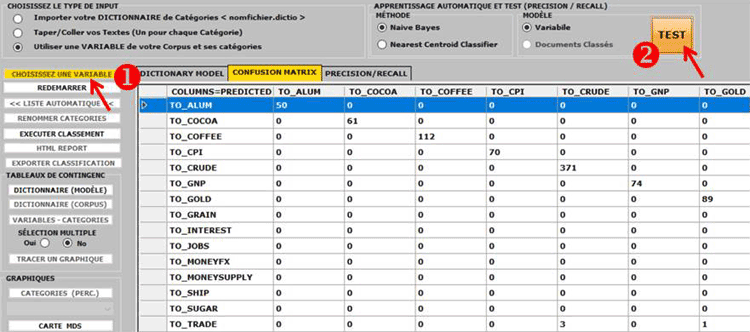
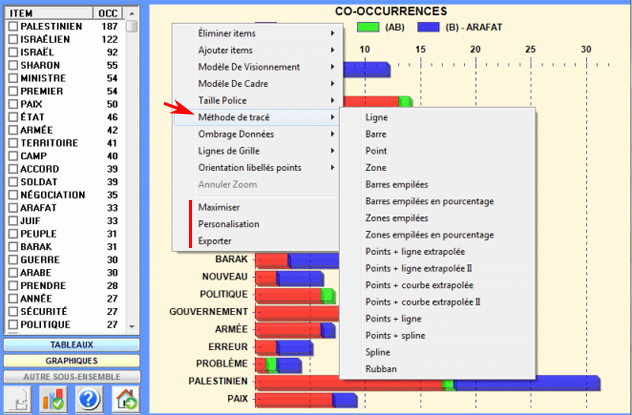
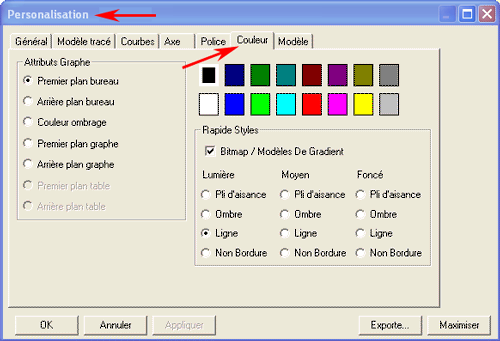
6 - L' INTERPRÉTATION DES OUTPUTS consiste en la consultation des tableaux et des graphiques produits par T-LAB, en l'éventuelle personnalisation de leur format et dans le fait de faire des inférences sur la signification des relations représentées. Dans le cas des tableaux, selon les cas, T-LAB permet de les exporter dans des fichiers avec les extensions suivantes: .DAT, .TXT, .CSV, .XLXS, .HTML. Ceci signifie que, en se servant de n'importe quel éditeur de textes et/ou d'un applicatif de la suite Microsoft Office, l'utilisateur peut facilement les importer et les réélaborer. Dans le cas des graphiques, les sous-menus appropriés activés avec le clic droit de la souris permettent d'effectuer plusieurs opérations: zoom (clic gauche et glisser), maximisation, personnalisation et exportation des outputs en plusieurs formats.
Certains critères généraux pour l'interprétation des outputs T-LAB sont illustrés dans un papier cité dans la Bibliographie (Lancia F.: 2007) et disponible sur le site www.tlab.it. Dans ce dernier on propose l'hypothèse que les outputs des élaborations statistiques (tableaux et graphiques) sont un type particulier de textes, c'est-à-dire des objets multi-sémiotiques caractérisés par le fait que les relations entre les signes et les symboles sont ordonnées par des mesures qui renvoient à des codes spécifiques. Dans d'autres termes, aussi bien dans le cas des textes écrits dans le langage naturel que dans ceux écrits dans le langage de la statistique, la possibilité de faire des inférences sur les relations qui organisent les formes du contenu est garantie par le fait que les relations entre les formes de l'expression ne sont pas casuelles (random); en effet, dans le premier cas (langage naturel) les unités signifiantes se succèdent ordonnées de façon linéaire (l'une après l'autre dans le chaîne du discours), alors que dans le second cas (tableaux et graphiques) les principes d'ordonnance sont constitués par les mesures qui déterminent l'organisation des espaces sémantiques multidimensionnels. Même si les espaces sémantiques représentés dans les cartes T-LAB sont très variés, et chacun d'eux requiert des procédures interprétatives spécifiques, nous pouvons faire l'hypothèse que - en général - la logique du processus inférentiel est la suivante: A - relever
une relation significative entre les unités "présentes" sur le plan
de l'expression (par ex. entre "données" des tableaux et/ou entre
"labels" des graphiques);
|