|
www.tlab.it
Index d'association
Dans T-LAB les indices d'association (ou de
similarité) sont utilisés pour analyser les cooccurrences des unités
lexicales (LU, lexical units) à l'intérieur des contextes élémentaires (EC, elementary
contexts), c'est-à-dire des données binaires du type
présence/absence.
Par exemple, étant donnés deux LU et dix EC, nous pouvons
construire l'exemple suivant
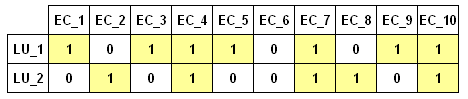
Les mêmes données peuvent être représentées de la
façon suivante:
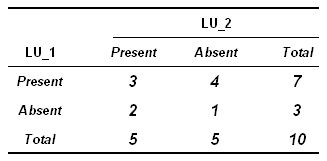
En généralisant et en utilisant les lettres de
l'alphabet:
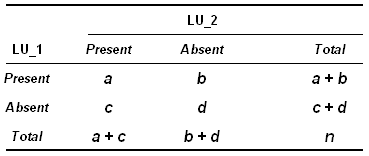
Les formules correspondantes aux trois indices
d'associations utilisés par T-LAB sont les suivantes:
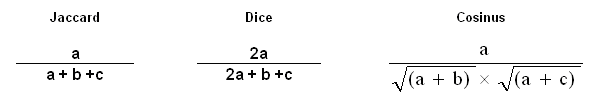
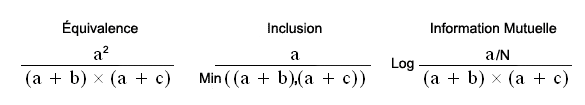
En faisant l'hypothèse d'avoir obtenu des indices
d'association des relations entre dix LU, nous pouvons construire
un tableau comme le suivant:
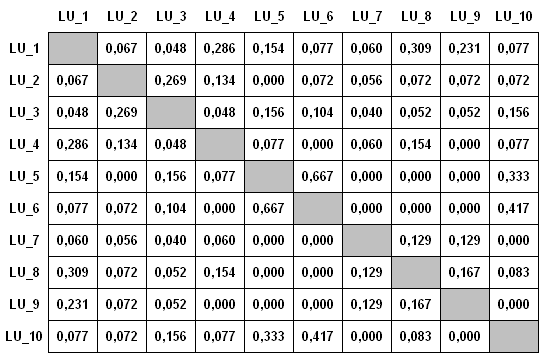
De fait, T-LAB construit et analyse des tableaux
analogues de dimensions N x N (où N peut correspondre à diverses
centaines de colonnes), aussi bien à travers Multidimensional Scaling qu'à travers Cluster Analysis.
Les mêmes tableaux sont, en outre, utilisés pour
calculer des index de similarité du deuxième
ordre entre couples de mots clés (voir l'instrument Associations de Mots).
|


