|
www.tlab.it
Exporter des Tables
Personnalisées
 N.B.: Les images de cette section font référence à une
version précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent, mais les fonctions sont les mêmes. N.B.: Les images de cette section font référence à une
version précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent, mais les fonctions sont les mêmes.
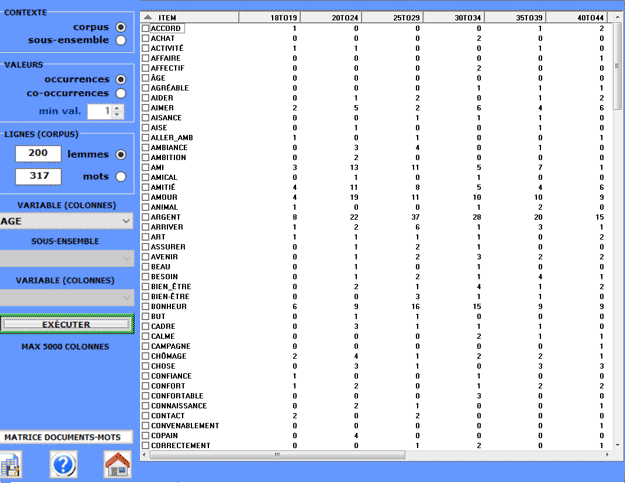
Cette option nous permet de créer, d'explorer et
d'exporter deux types de tableaux:
a) ceux avec les valeurs d'occurrences des unités lexicales dans les
sous-ensembles du corpus définis au moyen de quelque variable
(matrices rectangulaires);
b) ceux avec les valeurs de co-occurrences des unités lexicales (matrices
carrées) dans le corpus ou dans ses sous-ensembles;
c) ceux avec les occurrences des différentes
unités lexicales à l'intérieur de tous les documents (matrices
dispersées avec les index des éléments différents).
Les dimensions maximum de tels tableaux sont
respectivement: a) 10.000 lignes pour 150 colonnes; b) 5.000 lignes
de 5.000 colonnes; c) 30.000 documents pour 10.000 unités
lexicales.
Les dimensions maximales de ces tableaux sont
respectivement: a) 10.000 lignes par 150 colonnes, b) 1.500 lignes
par 1.500 colonnes..
L'utilisation de cette fonction est très
intuitive.
Dans les cas plus simples, l'utilisateur doit
choisir une variable dont les modalités constitueront les colonnes
du tableau.
Dans les cas plus
complexes, il doit choisir une variable et un sous-ensemble.
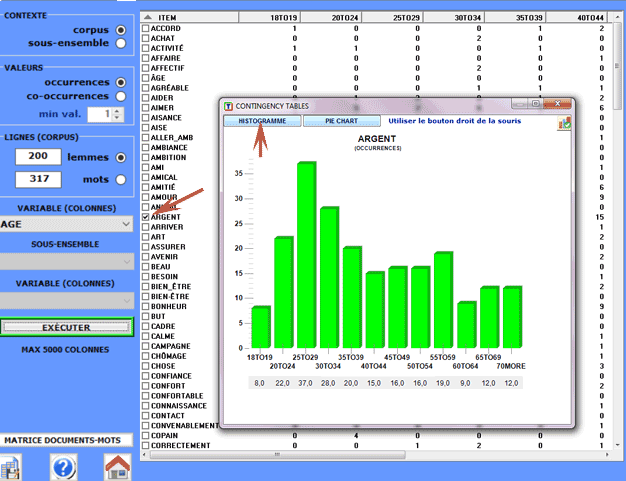
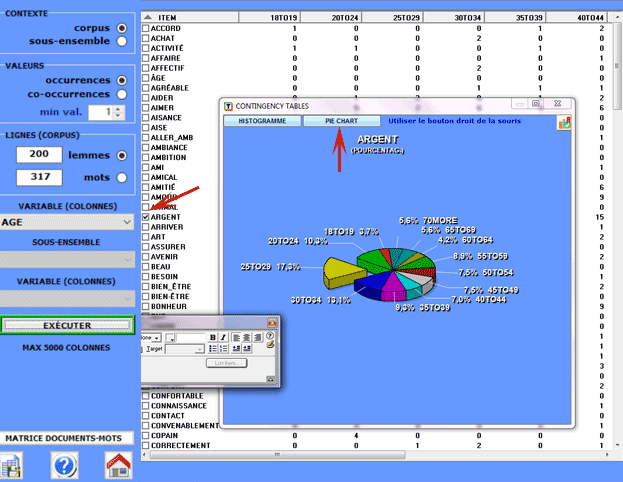
Tous les tableaux nous
permettent de créer différents types des graphiques.
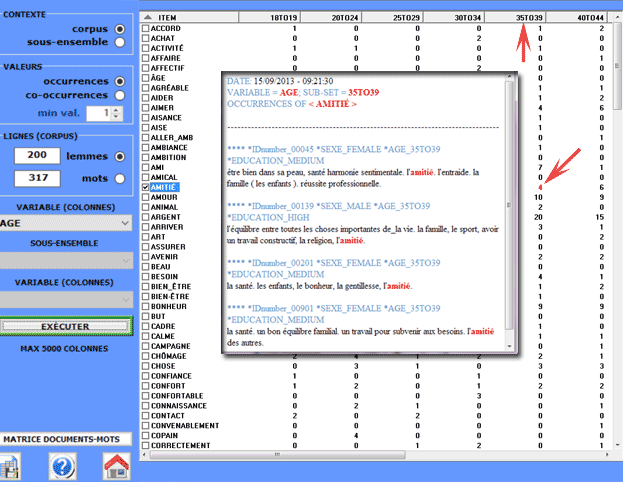
De plus, en cliquant sur cellules spécifiques d'un
tableau, il est possible de créer un fichier HTML montrant tous les contextes
élémentaires où le mot en ligne est présent dans le sous-ensemble
correspondant (voir ci-dessous).
Pour exporter des matrices dispersées de type
documents pour mots, il suffit d'appuyer sur le bouton Matrice Documents-Mots (voir ci-dessus).
Dans ce cas, les types d'output sont deux:
Le premier (Sparse_Matrix.csv) a le format suivant:
Doc_Index;Word_Index;Word_Occ
00001; 1; 12
00001; 2; 5
Le second (Word_Indexes.csv) a le format suivant :
Word_Index;Word_Label
1; abolir
2; accepter
…
|


