|
TF-IDF
Cette mesure, proposée par G. Salton (1989), permet
d'attribuer un score d'importance à un terme (unité lexicale) dans
un document (unité de contexte).
Sa formule est la suivante:
w i,j =
tf i,j x idf i (Term Frequency x Inverse
Document Frequency)
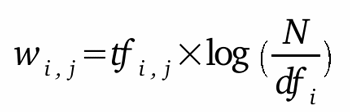
Avec:
tf i,j =
fréquence d'apparition de i
(terme) dans j (document)
df i = nombre de documents du
corpus contenant i
N = nombre de documents du
corpus
On peut normaliser la Fréquence du Terme
(tf
i,j ) dans la manière suivante:
tf i,j
= tf i,j / Max
(f i,j )
où Max (f i,j ) est la
fréquence maximale de i (un
terme quelconque) dans j
(document).
|


