|
www.tlab.it
Classification basée sur des
Dictionnaires
 N.B.: Les images de cette section font référence à une version
précédente de T-LAB 9. En
T-LAB 10, l'aspect est
légèrement différent mais les fonctions sont les mêmes. En
particulier, à partir de la version 2021, une nouvelle
fonctionnalité permet de tester facilement n'importe quel modèle
sur des données étiquetées (par exemple des données qui incluent
des thèmes obtenus à partir d'une analyse qualitative précédente)
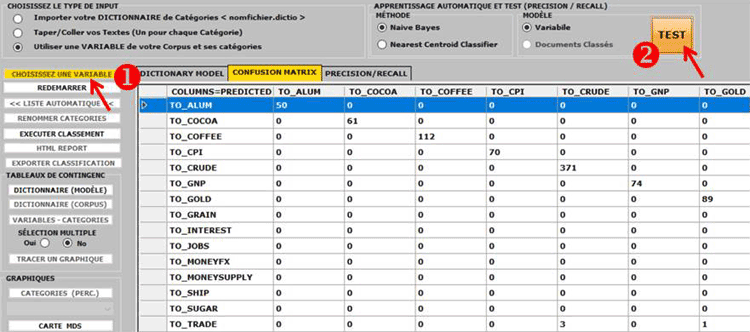
et d'obtenir des résultats comme des matrices de confusion et des
métriques de précision / rappel (voir image ci-dessous).
N.B.: Les images de cette section font référence à une version
précédente de T-LAB 9. En
T-LAB 10, l'aspect est
légèrement différent mais les fonctions sont les mêmes. En
particulier, à partir de la version 2021, une nouvelle
fonctionnalité permet de tester facilement n'importe quel modèle
sur des données étiquetées (par exemple des données qui incluent
des thèmes obtenus à partir d'une analyse qualitative précédente)
et d'obtenir des résultats comme des matrices de confusion et des
métriques de précision / rappel (voir image ci-dessous).
Cet outil T-LAB vous
permet d'effectuer un classement
automatique des unités
lexicales (c' est-à-dire des mots et des lemmes, multiwords
compris) ou des unités de contexte (c'
est-à-dire des phrases, des paragraphes ou des documents courts)
qui se trouvent dans un corpus en appliquant un ensemble de
catégories prédéfinies ou bien choisies par l' utilisateur.
Selon le type de catégories utilisées, lesquelles peuvent
être contenues dans un dictionnaire opportunément importé ou
produites par T-LAB, ce
classement peut être considéré un type d'analyse du contenu ou bien un type de sentiment analysis.
Puisque le processus d'analyse permet de créer de
nouvelles variables et d' autres dictionnaires qui peuvent être
exportés et importés dans d' autres projets d'analyse, cet outil
peut aussi être utilisé soit pour explorer le même corpus à partir
de points de vue différents, soit pour analyser deux ou plusieurs
ensembles de textes en appliquant les mêmes modèles.
Parmi les utilisations
possibles de cet outil, nous signalons les suivantes:
- Codage automatique de réponses à questions
ouvertes;
- Analyse top-down des discours politique ;
- Sentiment Analysis de commentaires concernant des produits
spécifiques;
- Vérification du processus psychothérapeutique;
- Validation de méthodes pour l' analyse qualitative.
De suite on trouve une brève description des quatre
étapes principales du processus d'analyse, lesquelles - cependant -
doivent être considérées indépendantes les unes des autres. En
effet, le chercheur peut utiliser cet outil seulement pour
personnaliser ses dictionnaires ou pour explorer son set de
données.
A) - PHASE DE PRÉ-PROCESSING
Les points de départ et les
types correspondants de l'input de la phase de pré-processing
peuvent être trois:
points and the corresponding input
types of the pre-processing phase can be three:
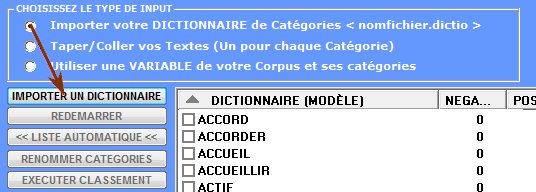
1 - un dictionnaire des
catégories dans le format approprié est déjà disponible (voir les
informations correspondantes dans la section 'E' de ce document).
Dans ce cas, il suffit de cliquer l'option 'Importer un
dictionnaire' (voir ci-dessous);
2 - un dictionnaire des catégories doit dériver
d'exemples de texte ou des
listes de mots fournies par
l'utilisateur. Dans ce cas, il suffit de taper ou copier / coller
les textes dans la case appropriée (un exemple pour chaque
catégorie, un après l'autre, maximum 100.000 caractères
chacun);

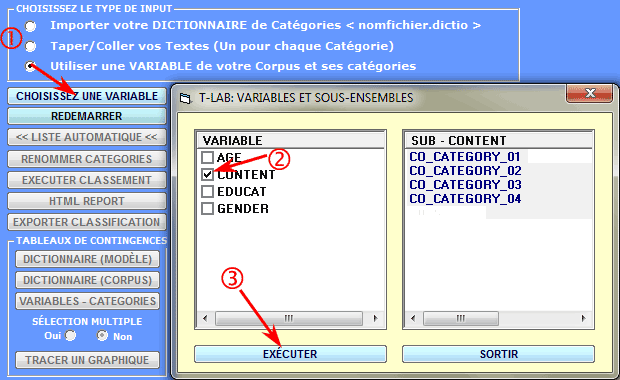
3 - un dictionnaire des catégories doit dériver d'une
variable dérivant d' une d'analyse du
contenu préalable. Dans ce cas, il suffit de cliquer sur l' option
'Choisissez une Variable' et effectuer les choix appropriés (voir
ci-dessous).
Selon un des trois cas énumérés ci-dessus, avant d'activer l'option
'Exécuter Classement', T-LAB
fonctionne comme suit:
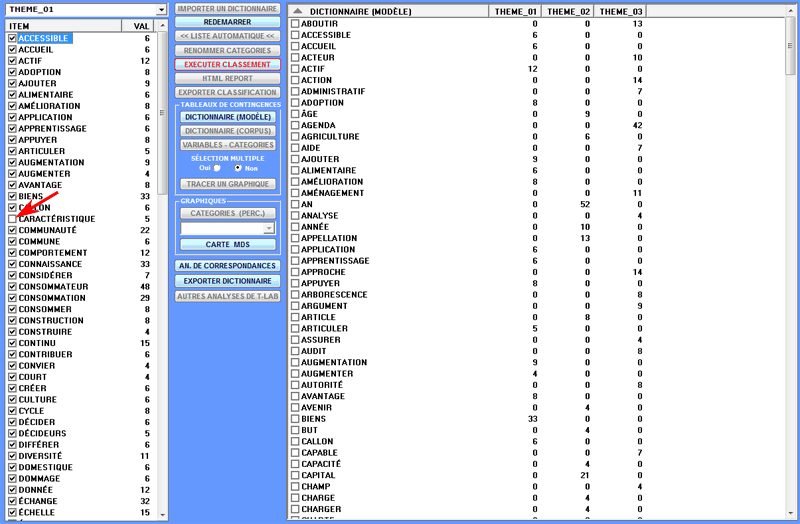
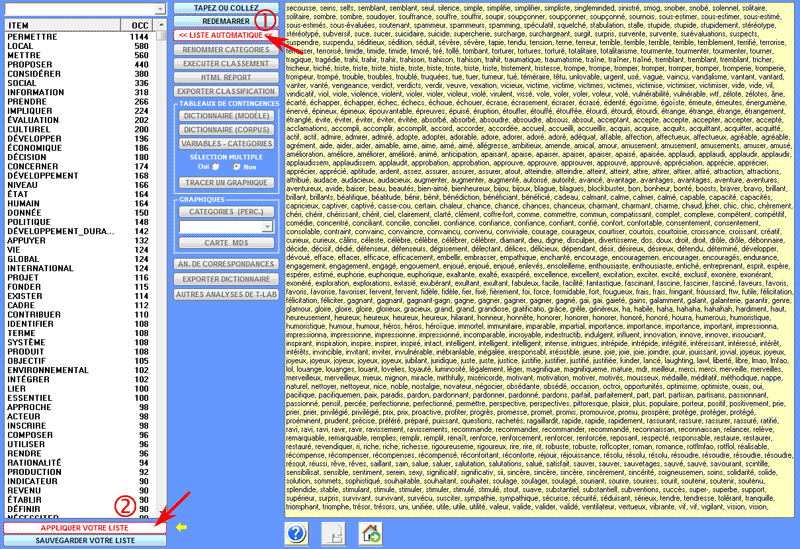
1 - le dictionnaire importé est transformé en un tableau
de contingence que l'utilisateur peut explorer de diverses façons
(voir la section 'C' du présent document) ; en outre, en
sélectionnant chaque catégorie, un ou plusieurs des éléments
correspondants peuvent être éliminés (voir image
ci-dessous).
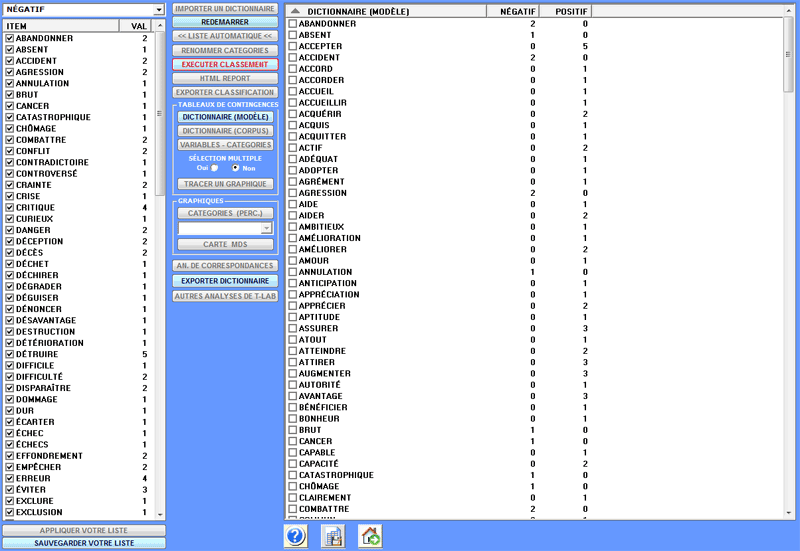
2 - lorsque les textes de l' exemple sont insérés dans la
case correspondante, après avoir cliqué sur le bouton 'Liste
Automatique' (voir ci-dessous), T-LAB effectue un type spécifique de
lemmatisation qui utilise seulement le vocabulaire du corpus
sélectionné (voir la liste des mots dans la zone gauche de l'image
suivante), puis, convertit chaque texte dans une liste dont les
éléments peuvent être sélectionnés et désélectionnés. Ensuite, pour
valider chaque liste de mots (c'est-à-dire chaque catégorie du
dictionnaire), il faut cliquer sur l' option 'Appliquer votre
liste' (voir ci-dessous). Toutes les opérations mentionnées doivent
être répétées pour chaque catégorie du dictionnaire, ensuite
l'utilisateur est autorisé à effectuer les opérations décrites dans
la section 'C' de ce document.
3 - lorsque vous sélectionnez une variable résultant
d'une précédente analyse du contenu, T-LAB visualise le tableau relatif de
contingence des mots par catégories et l'utilisateur peut effectuer
toutes les opérations d' exploration des données (voir la section
'C' du document présent).
B) - PROCESSUS DE CLASSIFICATION
Après avoir cliqué sur l' option 'Exécuter classement'
(voir ci-dessus), selon le type de l' analyse de corpus , l'
utilisateur peut effectuer les choix suivants:
À ce stade, si l'utilisateur décide de classer les mots, d'autres choix ne sont pas
disponibles ; en effet, dans ce cas, les occurrences de chaque mot
(c'est-à-dire les words tokens) sont tout simplement comptées comme
les occurrences de la catégorie correspondante. Par exemple, si une
catégorie de notre dictionnaire est 'religion' et celle-ci inclut
des mots comme 'foi' et 'prière', lorsque l' on analyse un document
qui contient les deux mots en question, T-LAB se limite à regrouper leurs occurrences.
Par exemple, 2 occurrences de 'foi' et 3 occurrences de 'prière'
deviennent 5 occurrences de 'religion'.
Sinon, si l'utilisateur décide de classer les unités de contexte (c' est-à-dire
'contextes élémentaires' comme des phrases et des paragraphes ou
des 'documents '), T-LAB
considère aussi bien les catégories dictionnaire que les unités de
contexte à classer comme des profils de co-occurrences
(c'est-à-dire term vectors) et calcule leurs mesures de similarité.
A cet effet, les profils de co-occurrences peuvent être filtrés à
travers une 'Liste de T-LAB' (c' est-à-dire à partir d'une liste
qui comprend tous les mots-clés avec les valeurs d'occurrence
supérieures ou égales au seuil minimum de 4) ou à travers une liste
personnalisée (c' est-à-dire une liste qui comprend tous les
mots-clés dérivant d' un choix de la part de l'utilisateur), listes
qui , toutefois, peuvent même parfois résulter égales. En outre ,
dans ces cas , T-LAB permet
d'exclure de l'analyse des unités de contexte qui ne contiennent
pas un nombre minimum de mots-clés en leur intérieur (voir
ci-dessus le paramètre 'co-occurrences dans les unités de
contexte').
Lorsque, comme dans le cas que l' on vient de décrire,
les 'objets' à classer sont les unités de contexte, T-LAB se déroule comme suit:
a) il normalise les vecteurs correspondant aux
catégories 'k' du dictionnaire utilisé, c' est-à-dire les profilés
de colonne relatifs ;
b) il normalise les vecteurs correspondant aux unités de contexte à
analyser;
c) il calcule des mesures de similarité (cosinus) et de différence
(distance euclidienne) entre chaque vecteur 'i' correspondant à une
unité de contexte et chaque vecteur 'k'
correspondant à une catégorie du dictionnaire utilisé ;
d) il attribue chaque unité de contexte ('i') à la classe ou à la
catégorie ('k') avec laquelle il a une relation de similitude plus
élevée. (Note: dans tous les cas, pour chaque paire 'unités de
contexte / 'catégorie' il doit y avoir une correspondance entre la
valeur maximale du cosinus et la valeur minimale de la distance
euclidienne, sinon T-LAB
considère l' unité de contexte 'i' comme 'non
classifiée'.
Autrement dit, dans le cas que l' on vient de décrire,
T-LAB utilise une sorte de
méthode K-means où les centroïdes 'K' sont définis a priori et ils
ne sont pas mis à jour pendant le processus d' analyse.
Étant donné que dans ce cas, la classification est de
genre top-down , la qualité des résultats obtenus dépend
essentiellement de deux facteurs :
1 - la 'pertinence' du dictionnaire utilisé (voir la relation entre
le lexique du corpus et le dictionnaire des catégories ) ;
2 - la capacité 'discriminante' de chacune des catégories (voir la
relation entre les différentes catégories du dictionnaire).
En effet, lorsque ces deux facteurs sont optimaux, les deux
paramètres de 'précision' et 'recall' (voir
http://en.wikipedia.org/wiki/Precision_and_recall) ont des valeurs
comprises entre 80% et 95%.
On rappelle qu' en ce moment T-LAB ne tient pas compte des formules de la
négation, par conséquent, en effectuant une sentiment analysis, une
phrase comme 'N' hais pas ton ennemi' peut être classée comme une
tonalité 'négative' . Les utilisateurs experts peuvent gérer ce
problème durant l'importation corpus (voir l'utilisation de listes
pour les stop-words et multi-words). Par exemple, l'expression "N'
hais pas" peut être transformée en "N_hais_pas" et, si on le
retient approprié, elle peut être incluse dans la catégorie
'positif'.
.
C) - EXPLORATION DES DONNÉES
Dans l'utilisation de cet instrument toute activité
d'exploration se réfère à des tableaux de
contingence dans lesquels, selon les cas, peuvent être
représentées soit les données en input (par exemple un dictionnaire
de catégories) que les données en output (par exemple les résultats
du processus de classification).
En particulier, en ce qui concerne les résultats de
l'analyse, en fonction des unités textuelles classées -
respectivement (a) 'mots', (b) 'contextes élémentaires' ou (c)
'documents' - les cellules des tableaux affichés contiennent les
valeurs suivantes:
a) total des occurrences de chaque mot qui, dans le corpus analysé
ou d' un de son sous-ensemble, a été classé comme appartenant à une
catégorie prédéfinie (c' est-à-dire à la colonne ' j ' du tableau
de contingence respectif). À noter que dans ce type de
classification les mots appartenant simultanément à deux ou
plusieurs catégories ont les mêmes valeurs répétées dans les
colonnes correspondantes ;
b) total des contextes élémentaires affectés à une catégorie
particulière (soit la colonne ' j ' dans laquelle est présent le
mot dans la ligne (' i ') correspondante ;
c) total des occurrences de chaque mot (voir les lignes du tableau
de contingence relatif) dans les documents attribués à chaque
catégorie (voir les colonnes du tableau de contingence.
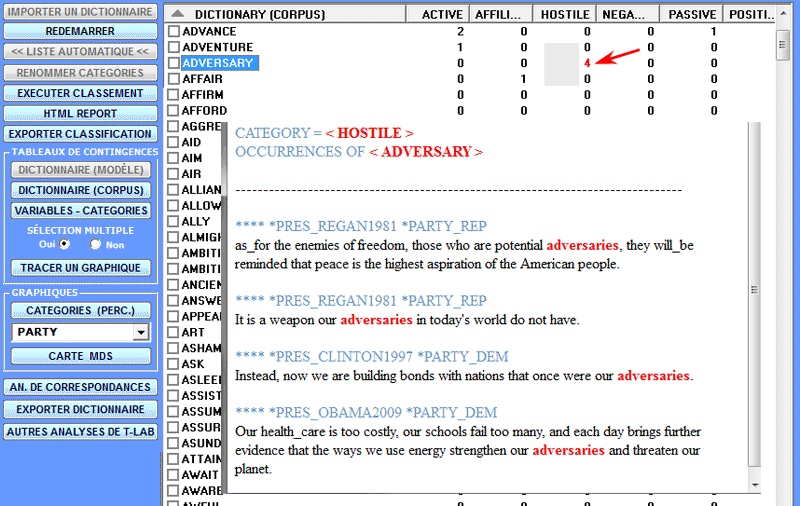
En cliquant sur les check-box correspondant aux
différents items en ligne on peut obtenir des graphiques qui
peuvent être personnalisés de différentes manières ; en outre, mais
seulement en cas de classification de type 'b' (voir ci-dessus), en
cliquant sur les valeurs contenues dans les cellules il est
possible de visualiser les contextes d'occurrence de chaque
mot.
Ci-dessous on trouve quelques outputs résultant d'un processus
d'analyse dans lequel certaines catégories d'un dictionnaire
'classique' pour l'analyse du contenu (Harvard IV-4) ont été
appliquées aux discours inauguraux des présidents des
États-Unis.
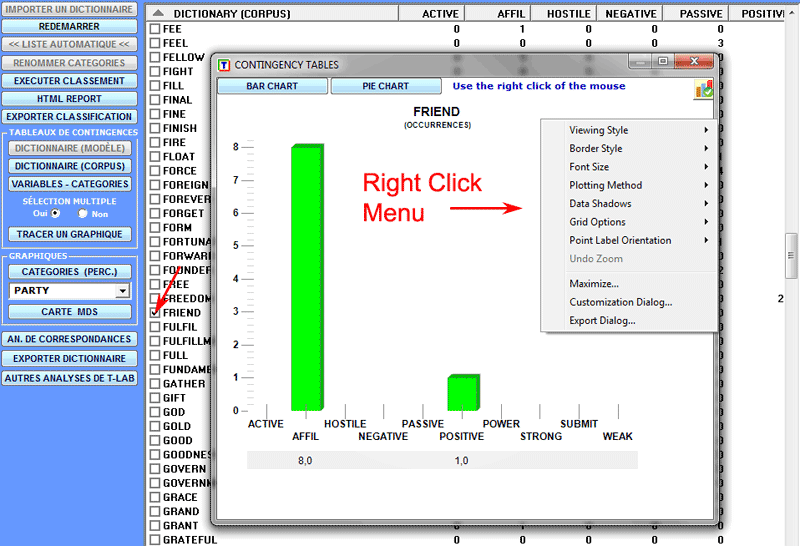
Pour créer des graphiques avec plus d' ensembles de
données correspondant à plusieurs lignes des tableaux de
contingence, il suffit de choisir 'Sélection multiple' (option
'Oui'), de sélectionner jusqu'à 20 éléments et de cliquer sur
'Tracer le Graphique' (voir ci-dessous).
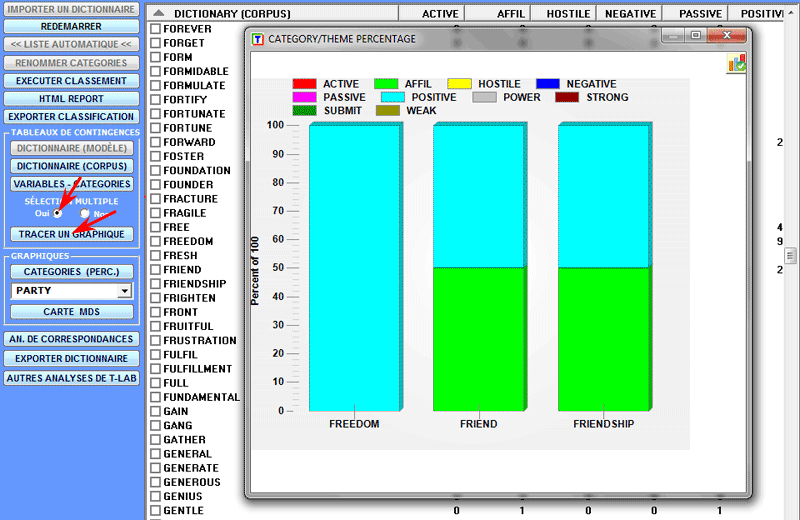
Les deux options ci-dessus sont également disponibles
pour les tableaux avec les valeurs des variables.
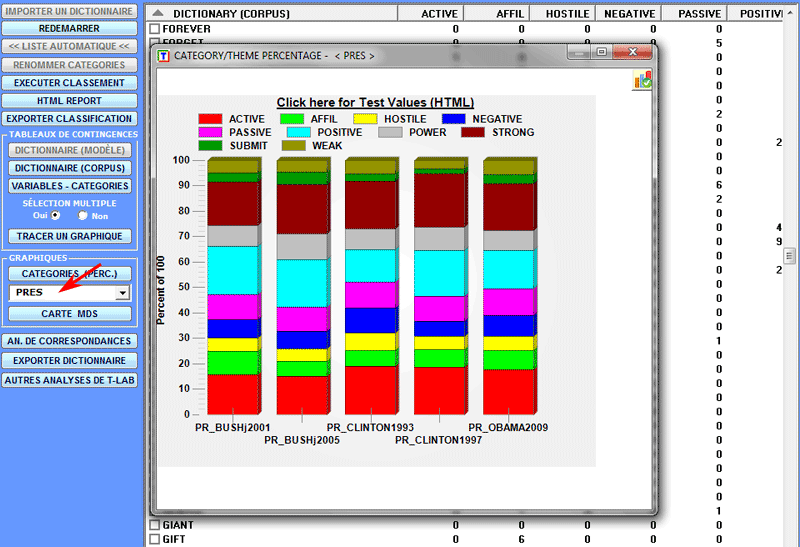
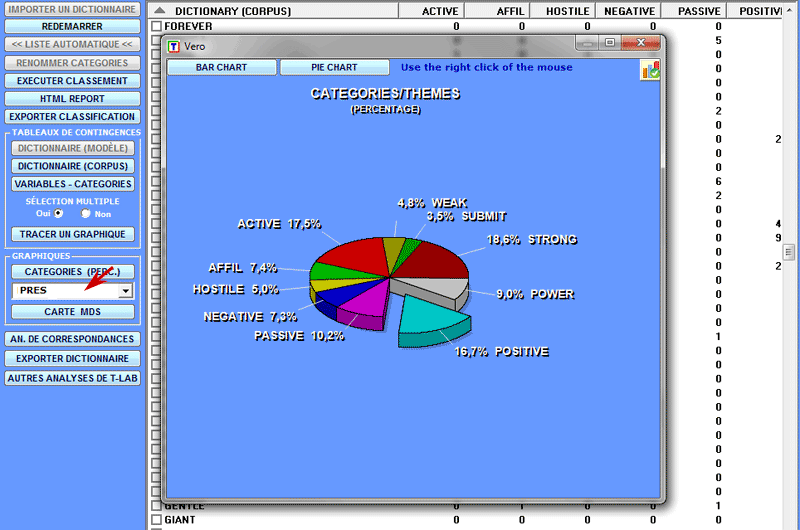
Les pourcentages des catégories peuvent être vérifiés de diverses
façons (voir ci-dessous)
Pour explorer la structure totale des données contenues
dans les tableaux de contingence, vous pouvez utiliser soit l'
option 'MDS' que l' option 'Analyse des Correspondances' (voir
ci-dessous).
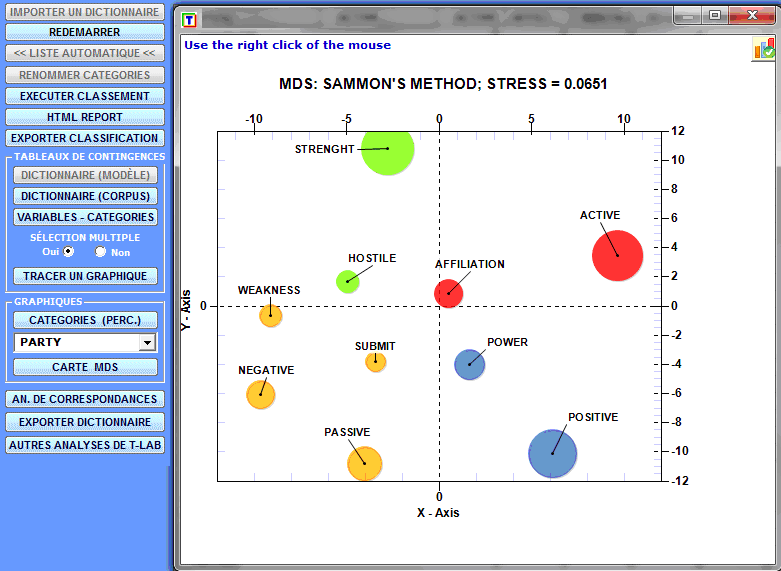
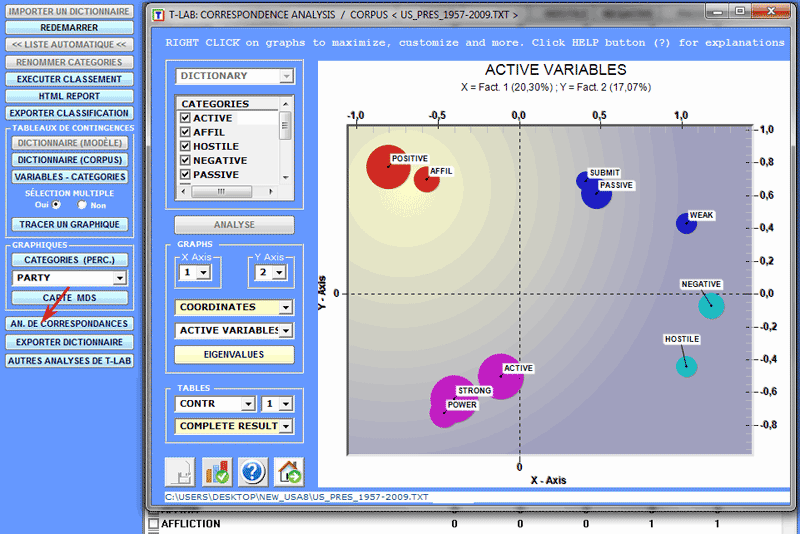
Seulement dans le cas que des unités de contexte ont été
classées il est possible d' afficher et d' exporter d' autres
outputs avec les données correspondantes ; en outre, en ce cas
aussi, il est possible d' enregistrer les résultats de l' analyse
dans une nouvelle variable et continuer l' exploration avec d'
autres outils du menu T-LAB.
En détail, en cliquant sur le bouton 'HTML Report' vous pouvez voir
certains résultats du processus de classification où un score de
similarité (cosinus) est attribué à tous les 'contextes
élémentaires' ou 'documents' appartenant aux différentes catégories
(NB: les images qui suivent sont relatives à un corpus de documents
contenant des brèves descriptions de sociétés).
 . .
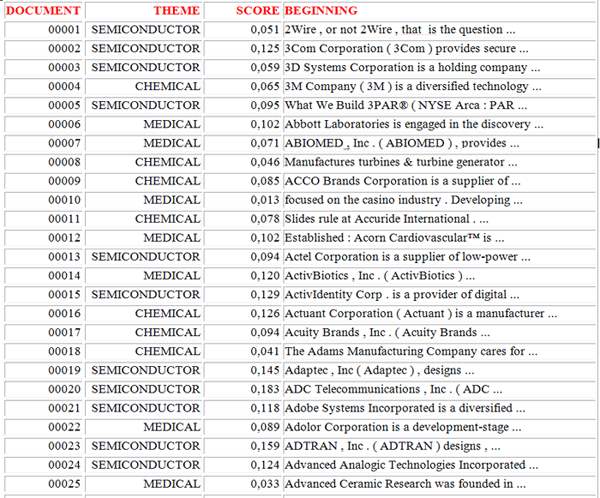
Des données similaires peuvent être exportées dans des
fichiers XLS (voir ci-dessous) qui contiennent toutes les
informations concernant les contextes élémentaires
('Context_Classification.xls') ou bien des documents
('Document_Classification.xls') correctement classés;
(1) - Context_Classification.xls
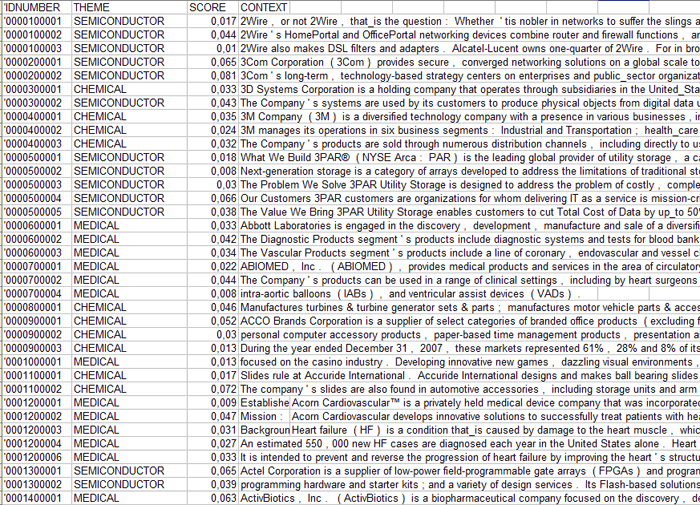
(2) - Document_Classification.xls
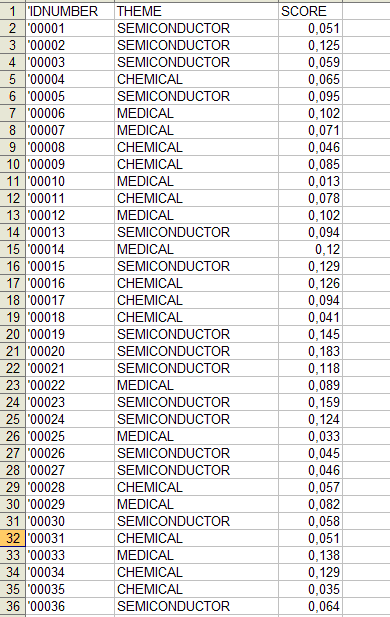
D) - AUTRES PHASES DU PROCESSUS D' ANALYSE
Lorsque le processus de classification a produit ses
outputs, deux autres options sont disponibles:
- 'Exporter Dictionnaire', qui crée un dictionnaire prêt
à être importé et utilisé avec d' autres outils T-LAB pour les
analyses thématiques ;
- 'Autres analyses T-LAB', qui, en fonction de la structure du
corpus analysé, du type de classement effectué et du nombre de
catégories appliquées, génère une nouvelle variable qui peut être
utilisée par d' autres outils T-LAB (voir ci-dessous).
.
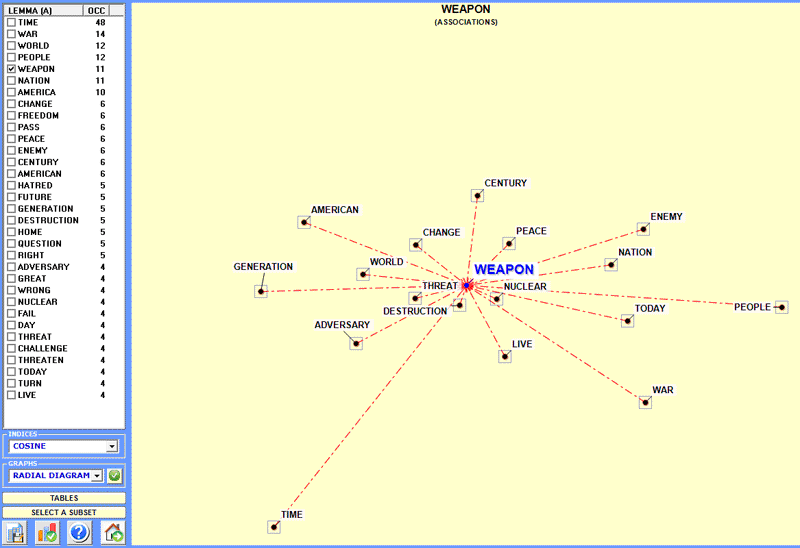
Ci-dessous vous trouvez un exemple obtenu par l'analyse d'un
'sous-ensemble' des contextes classés à l'aide de l' outil Associations de Mots (voir le menu principal de
T-LAB).
E) - FORMAT INPUT/OUTPUT DES DICTIONNAIRES T-LAB
Ci-dessous sont rapportées toutes les informations sur le
format des dictionnaires qui peuvent
être importés par cet outil de T-LAB:
- tous les dictionnaires doivent être des fichiers texte (ASCII /
ANSI) avec l' extension 'dictio' (ex. Mycategories.dictio) ;
- tous les dictionnaires créés par des outils T-LAB pour les analyses thématiques, y compris
ceux créés par l'outil 'Classification Basée sur des
Dictionnaires', sont prêts à être importés sans autres
interventions de la part de l' utilisateur ;
- d' autres dictionnaires, aussi bien 'standard' que personnalisés
, doivent être produits en suivant les indications rapportées
ci-dessous :
1 - chaque dictionnaire se compose de 'n' lignes et ne
peut pas dépasser la limite de 100.000 records ;
2 - chaque ligne du dictionnaire comprend deux ou trois
'chaînes' séparées par un point-virgule (ex. : économique;crédit)
;
3 - pour chaque ligne, la première chaîne doit être une
'catégorie', la seconde un 'mot' (ou lemme), la troisième - si
présente - doit être un nombre réel positif (c' est-à-dire un
numéro entier) de '1' à '999' qui représente le 'poids' de chaque
mot dans la catégorie correspondante ;
4 - la longueur maximale d'une chaîne (mot, lemme ou
catégorie) est de 50 caractères et ne doit pas contenir ni espaces
vides ni apostrophes ;
5 - lorsque le dictionnaire contient des multi-words (ex.
Gouvernement Fédéral), les espaces vides doivent être remplacés par
le caractère '_ ' (ex. Gouvernement _Fédéral);
6 - dans chaque dictionnaire, le numéro des catégories
utilisées peut varier entre un minimum de deux à un maximum de 50.
Lorsque le nombre de catégories est supérieur à 50 il est
recommandé d'utiliser un dictionnaire en un format différent et de
l' importer en utilisant l'outil Personnalisation du Dictionnaire. Dans ce cas,
on vous rappelle que chaque mot doit être en correspondance
univoque avec une (seule) catégorie.
De suite vous trouvez deux extraits de fichiers .dictio,
respectivement avec deux et trois chaînes par ligne:
a) cas avec deux chaînes (c' est-à-dire 'paires' de
catégories et de mots)
...
négatif;catastrophique
négatif;nuisible
...
positif;fantastique
positif;satisfait
...
b) cas avec trois chaînes (c'est-à-dire des catégories,
des mots et des numéros)
...
négatif;catastrophique;10
négatif;nuisible;8
...
positif;fantastique;9
positif;satisfait;7
|


