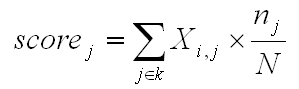|
|
T-LAB 10.2 - AIDE EN LIGNE |
|
|
www.tlab.it
Analyse Thématique des Contextes Élémentaires
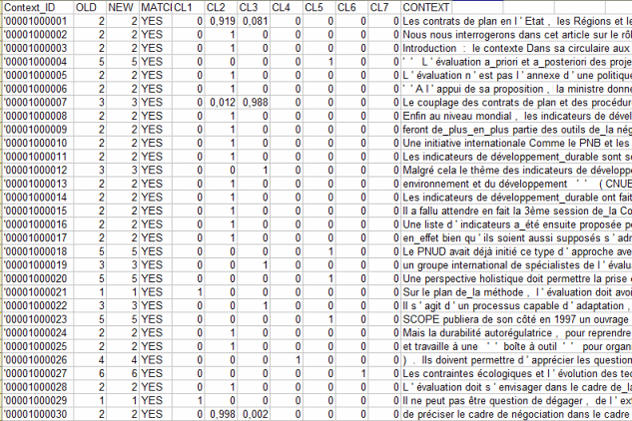
Cet outil T-LAB permet d'obtenir et d'explorer une représentation des contenus du corpus à travers un nombre restreint et significatif de classes thématiques (de 3 à 50), dont chacune: a) est formée par un ensemble de contextes élémentaires (phrases, paragraphes,
fragments de texte, réponses à des questions ouvertes) caractérisés
par les mêmes patterns de mots-clés; A plusieurs égards, on peut affirmer que le résultat de l'analyse propose une carte des isotopies (iso = égal; topoi = lieux), dont chacune correspond a un thème "générique" ou "spécifique" (Rastier, 2002: 204) caractérisé par la co-occurrence de traits sémantiques. Le processus d'analyse peut être effectué au moyen d'une méthode de clustering non supervisée (dans le cas particulier, un algorithme bisecting K-Means) ou bien à travers une classification supervisée (c'est-à-dire une approche top-down). Lorsqu'on choisit la deuxième (c'est-à-dire la classification supervisée), on vous demande d'importer un dictionnaire des catégories, qu'il soit aussi bien créé à travers une précédente analyse T-LAB que construit par l'utilisateur.
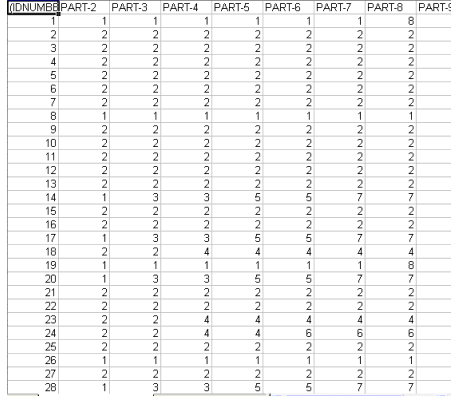
En particulier: - le paramètre (A) nous permet de fixer le nombre maximum
de classes à inclure dans les outputs T-LAB. N.B.: - Les deux paramètres ci-dessus produisent des
changements significatifs des résultats seulement quand le nombre
des unités de contexte est très grand et/ou quand il s'agit de
textes courts. Dans le cas de classification non supervisée (option de default), la procédure d'analyse est constituée par les étapes suivantes: a - construction d'un tableau unités de
contexte x unités lexicales (jusqu'à 300.000 lignes x 5.000
colonnes) avec valeurs du type présence/absence; N.B. : A partir de T-LAB Plus 2016, la clusterisation des
unités de contexte (voir l'étape "c" ci-dessus) peut être obtenue
soit en utilisant l'algorithme bisecting K-means algorithm (1),
soit en utilisant une version non centrée de l'algorithme PDDP
(Principal Direction Divisive Partitioning) proposé par D. Booley
(1998) pour sélectionner les centroïdes des de chaque bisection
K-means. Ainsi donc, cette procédure effectue un type
d'analyse des co-occurrences (étape
a-b-c) et ensuite un type d'analyse
comparative (e-f-g). En particulier, l'analyse comparative
utilise comme colonnes du tableau de contingence les modalités de
la "nouvelle variable" obtenue par l'analyse des co-occurrences
(modalités de la nouvelle variable = classes thématiques). N.B.: Lorsque l'utilisateur décide de répéter/appliquer les résultats d'une analyse précédente (c'est-à-dire Analyse Thématique des Contextes Élémentaires ou une Modélisation des Thèmes Émergents), T-LAB effectue uniquement une analyse comparative (étapes e-f-g). À la fin de l'analyse, l'utilisateur peut effectuer
aisément les opérations suivantes: Dans le détail: 1 - Explorer les
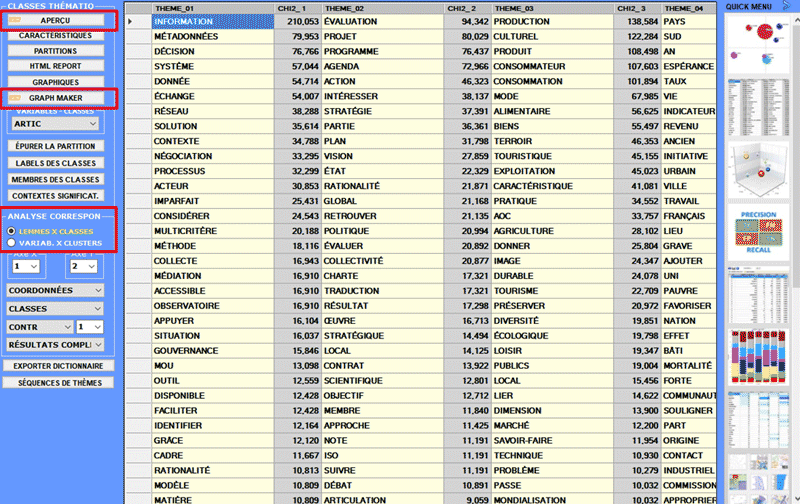
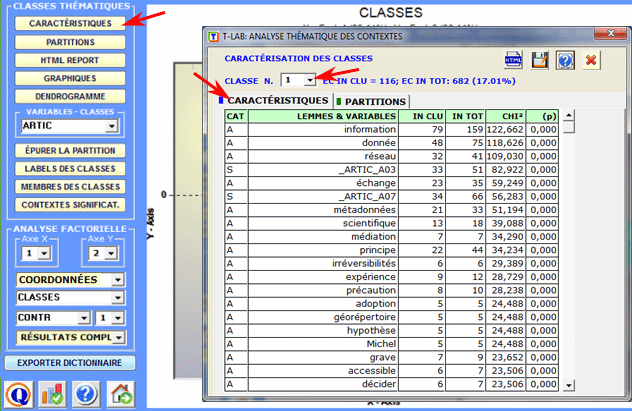
caractéristiques des classes
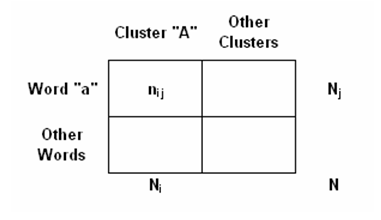
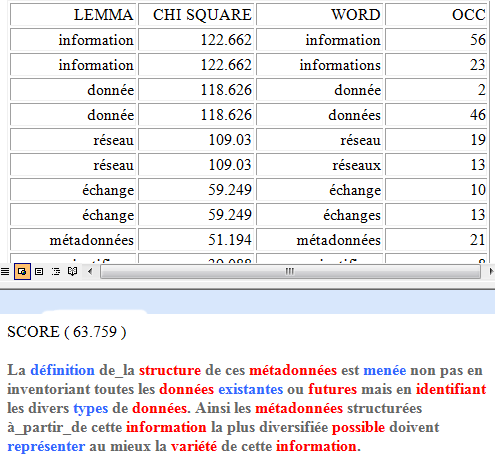
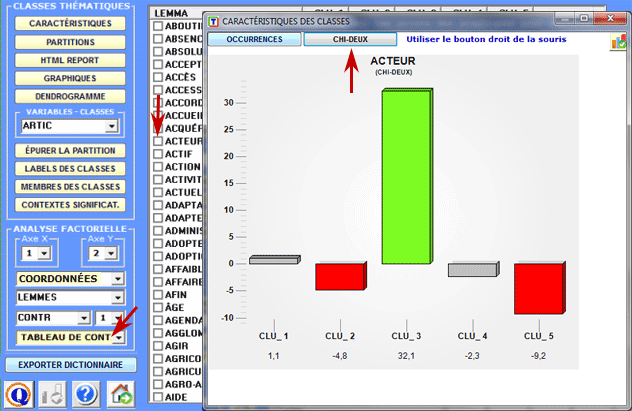
Dans le cas du chi-deux la structure de la table analysée est la suivante:
Un tableau HTML (voir
ci-après) permet de vérifier dans les détails les caractéristiques
des classes.
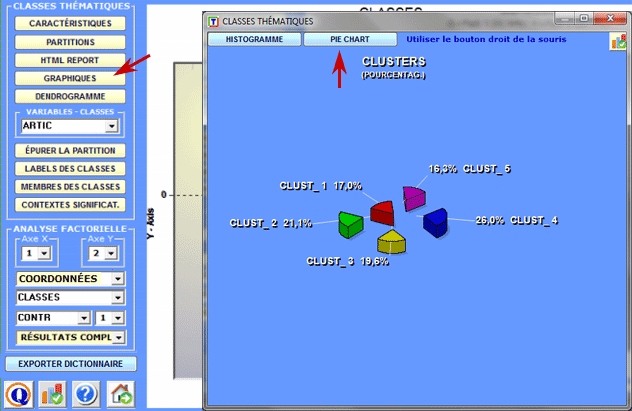
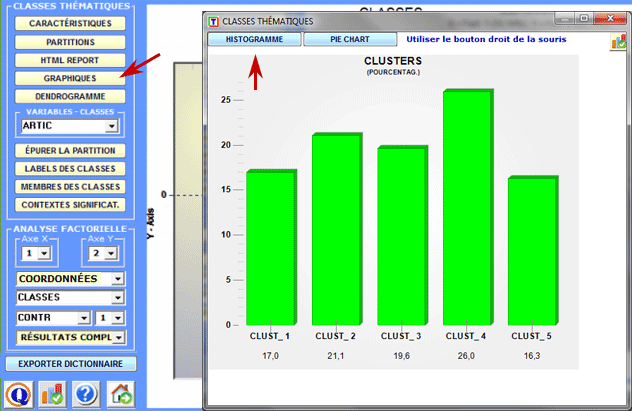
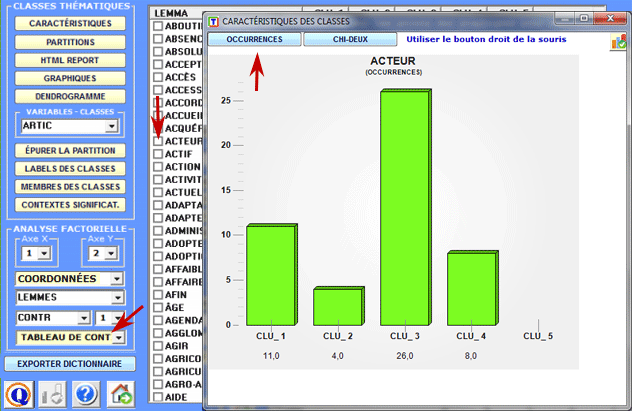
Des graphiques en secteurs (pie charts) et des histogrammes permettent de vérifier le pourcentage des unités de contextes appartenantes à chaque classe.
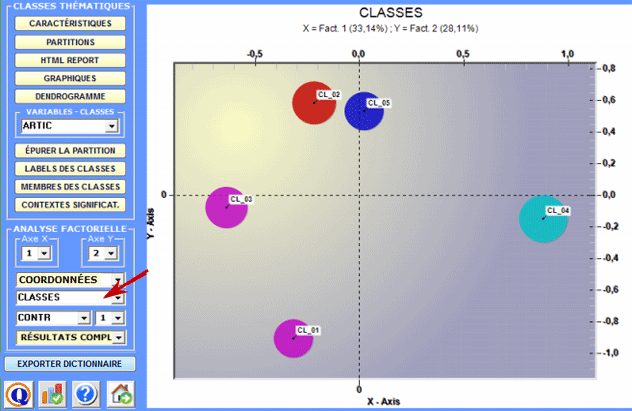
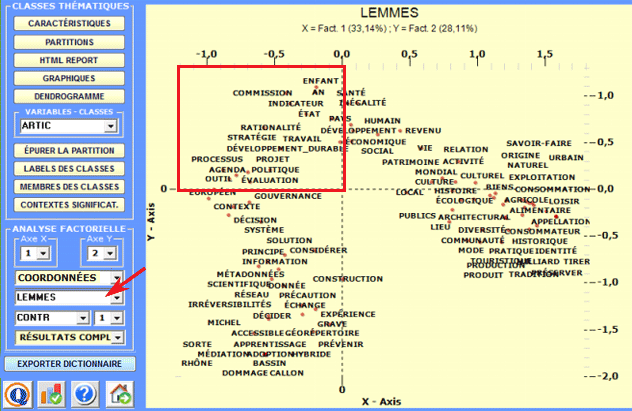
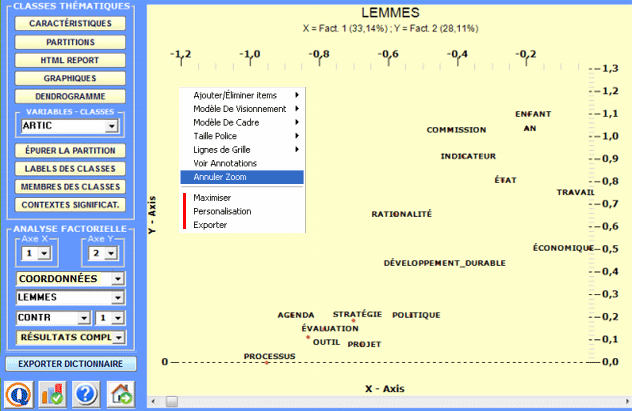
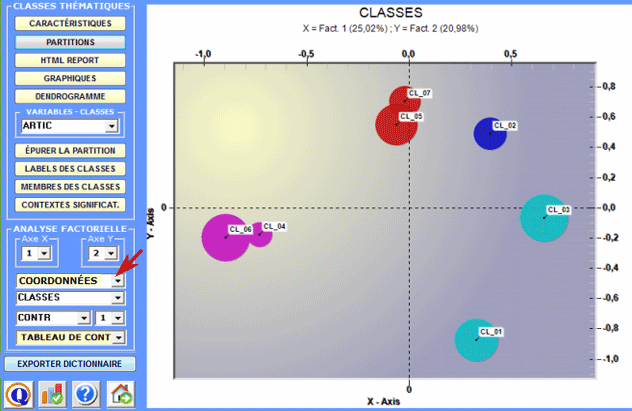
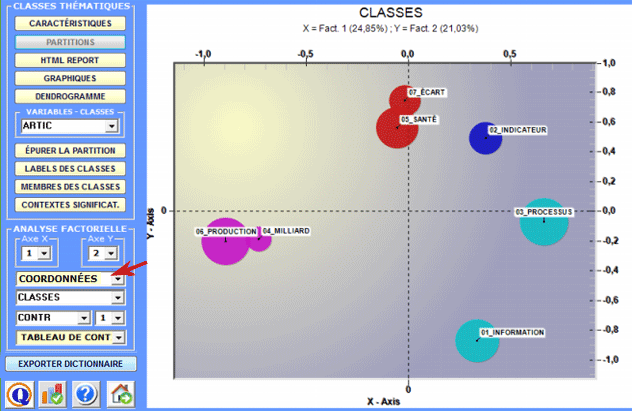
2 - Explorer les relations entre classes Certains graphiques, obtenus ou moyen de l'Analyse des Correspondances, permettent d'explorer les relations entre les classes à l'intérieur d'espaces bidimensionnels. Plus spécifiquement :
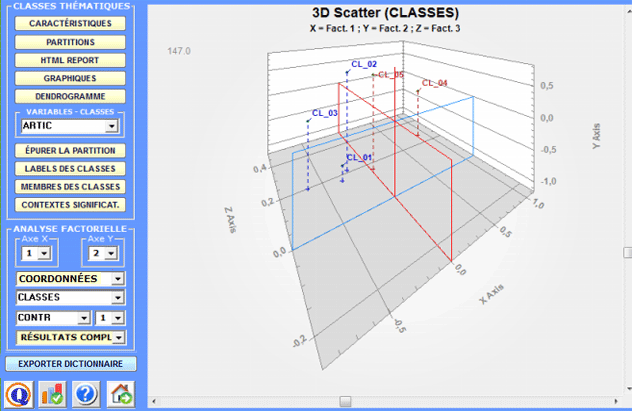
Tous les graphiques peuvent être personnalisés à travers l'utilisation de la fenêtre de dialogue appropriée (à l'aide du clic droit de la souris). De plus, lorsqu'il y a plus que trois clusters thématiques, leurs relations peuvent être explorées à travers les graphiques 3D (voir ci dessous).
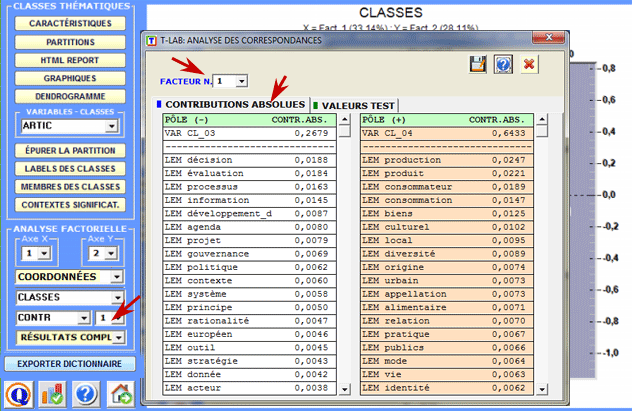
Pour chaque axe factoriel T-LAB fournit deux tableaux qui aident à l'interprétation.
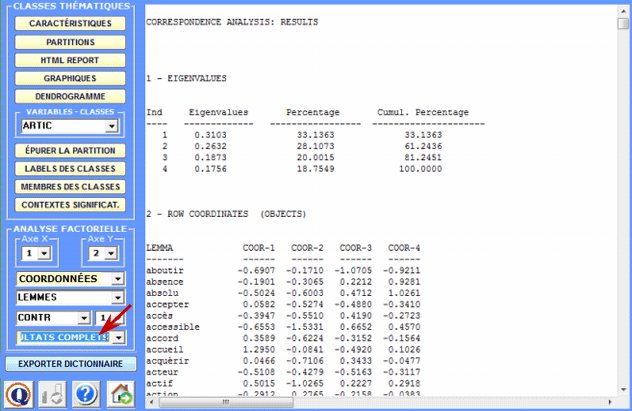
Un clic sur le bouton Tableau des Résultats nous permet de visualiser et de sauvegarder le fichier qui contient tous les résultats de l'analyse: valeurs propres, coordonnées, contributions absolues et relatives, valeurs test.
Une option spécifique (voir
ci-dessous) nous permet de visualiser / exporter le tableau de
contingences et de créer des graphiques montrant la répartition de
chaque mot au sein des clusters. N.B. : Ce tableau comprend
soit les mots-clés actives ('A') soit les mots-clés supplémentaires
('S').
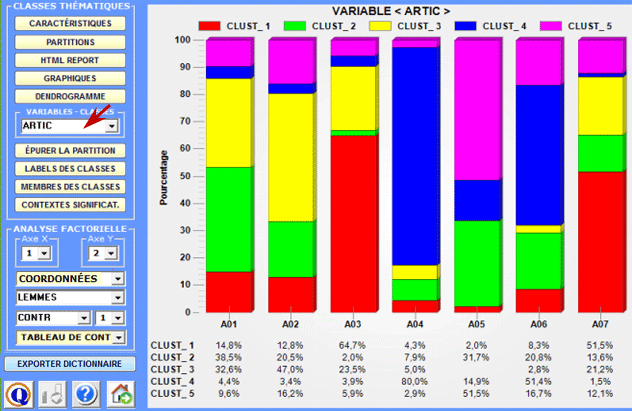
3 - Explorer les relations entre classes et variables Des histogrammes vous permettent de vérifier les rapports entre les classes et les variables.
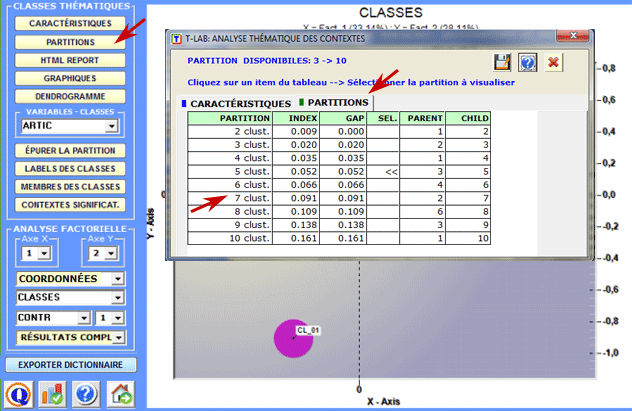
D'autres relations entre classes et variables peuvent être explorées à l'aide des options disponibles dans la section "Analyse factorielle " (voir ci-dessus). 4 - Explorer les différentes partitions des classes Puisque l'algorithme utilisé produit une
classification hiérarchique, l'utilisateur peut facilement explorer plusieurs
solutions de l'analyse: partitions composées de 3 à 50
classes. L'option Partitions (voir ci-après) vous permet d'explorer les caractéristiques des différentes solutions.
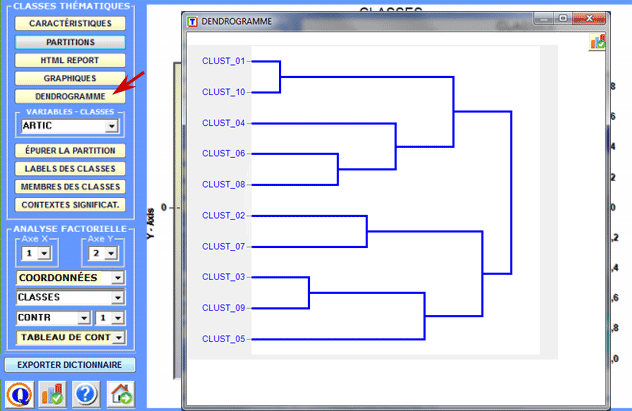
En outre, l'option dendrogramme (voir ci-dessous) permet deux possibilités: A) vérifier l'arbre des différentes bi-sections de clusters:
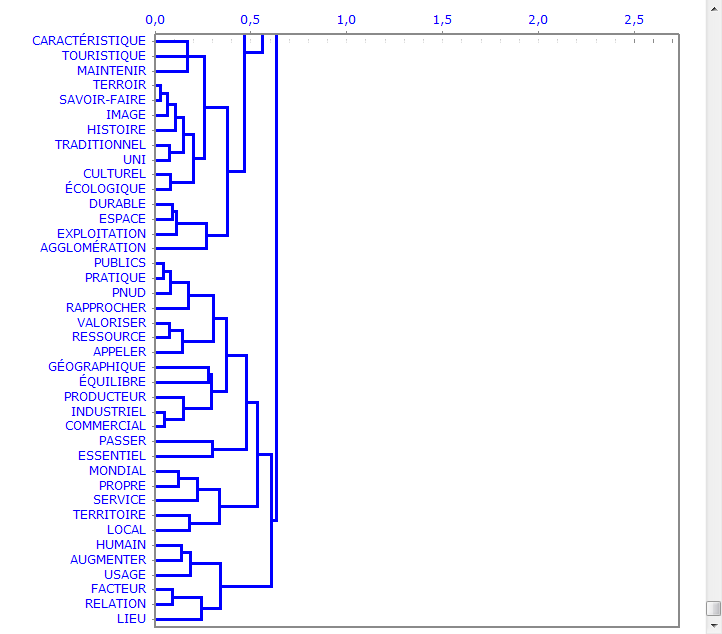
B) vérifier l'arbre des mots caractéristiques à chaque cluster:
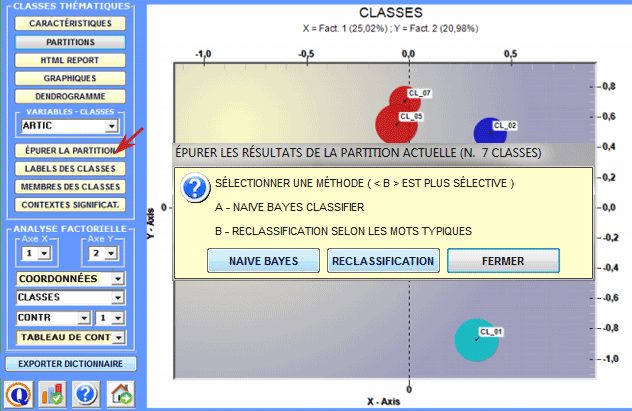
5 - Raffiner les résultats de la partition choisie Ensuite ayant exploré différentes solutions, l'utilisateur peut raffiner les résultats de la partition choisie et, au besoin, répéter certaines des étapes illustrées ci-dessus (1,2,3). À cet effet, deux méthodes sont disponibles (voir image suivante).
Quand on choisit la méthode "A" (c'est-à-dire Naïve Bayes Classifier), cette option
T-LAB
nous permet de supprimer de l'analyse toutes les unités de contexte
dont l'appartenance à une classe ne respecte pas les critères
suivants: Autrement, dans le cas de la méthode "B" (c'est-à-dire Reclassement selon les Mots Typiques) T-LAB considère les caractéristiques des classes, c'est-à-dire les mots avec une valeur significative de Chi-Deux, comme items d'un dictionnaire des catégories et effectue les trois étapes de la "classification supervisée" décrites au début de cette section. Donc, lorsque l'utilisateur est intéressé à réappliquer des dictionnaires et à en comparer les résultats relatifs, il est vivement conseillé l'utilisation de cette méthode. Tous les résultats de ce calcul sont dans un tableau exporté par T-LAB (voir ci-dessous) où les valeurs de les probabilités a posteriori sont converties en format pourcentage.
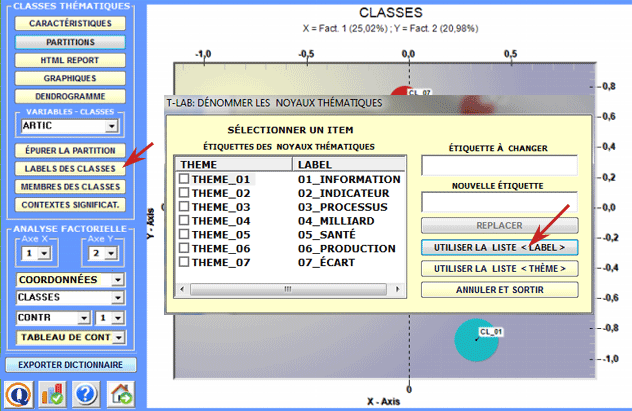
6 - Attribuer des étiquettes aux classes Une fonction particulière de T-LAB
permet d'attribuer des étiquettes aux classes.
Les étiquettes attribuées aux différentes classes peuvent être affichées dans les différents graphiques disponibles (voir ci-après).
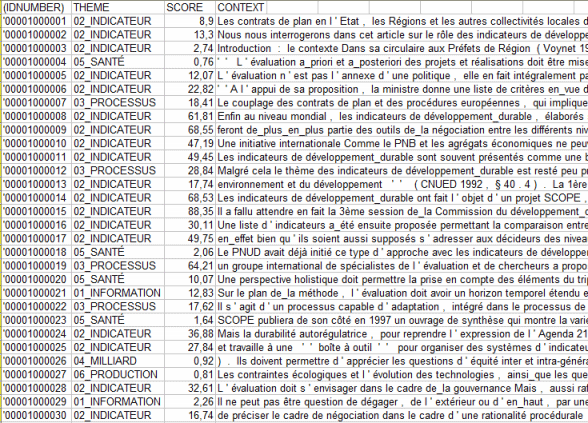
7 - Vérifier quels sont les
contextes élémentaires qui appartiennent à chaque classe
Le bouton Membres des Classes permet d'exporter trois types de tableaux (voir ci-après) sous format MS Excel: a - " Cluster_Partitions.xls " avec toutes les correspondances unités de contexte x classe à l'intérieur des différentes partitions ;
En particulier, la valeur d'importance (score) assignée à chaque contexte élémentaire (j) appartenant à la classe (k) vient de la formule suivante :
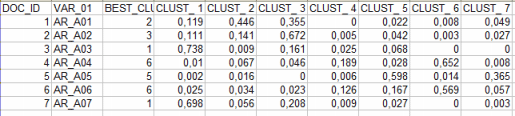
Où: c - " Ec_Document_Classification.xls " (output fourni seulement quand le corpus se compose au moins de 2 documents primaires qui ne sont pas des textes courts comme les réponses aux questions ouvertes) énumérant les appartenances mélangées de chaque document (voir ci-dessous).
10 - Archiver la partition sélectionnée pour l'explorer avec d'autres outils T-LAB Lorsqu'on quitte la fonction Analyse thématique des Contextes Elémentaires, des messages rappellent qu'il est possible d'explorer les classes obtenues avec d'autres outils T-LAB.
Si on choisit l'option Sauvegarder, la variable < CONT_CLUST > (classes de contextes élémentaires) demeure disponible uniquement dans certains types d'analyse (par exemple, Séquences de Thèmes, Associations de Mots, Comparaison entre Paires, Analyse des Mots Associés) et jusqu' au moment où l'utilisateur modifie sa liste de mots clés. 11 - Exporter un dictionnaire des catégories Lorsque cette option est sélectionnée, T-LAB crée deux fichiers: - un fichier dictionnaire avec l'extension '.dictio' prêt à être importé par l'intermédiaire d'un des outils pour l'analyse thématique. Dans ce dictionnaire chaque cluster correspond à une catégorie décrite au moyen de ses mots caractéristiques, c'est-à-dire par tous les mots avec une valeur significative du chi-deux à son interne; - un fichier MyList.diz prêt à être importé par la fonction Configuration Personnalisée. Etant donné que ce fichier contient la liste alphabétique de tous les mots avec une valeur significative du chi-carré, c'est-à-dire tous les mots qui déterminent la différence entre les clusters thématiques, son utilisation peut permettre de répéter certaines analyses avec une modalité plus sélective et discriminante. 12 - Vérifier la qualité de la partition choisie et la cohérence sémantique des différents thèmes
Lorsque vous cliquez sur le bouton Index de Qualité, T-LAB
crée un fichier HTML qui contient diverses mesures. 13 - Explorer les Séquences de Thèmes Contrairement à l'outil Séquences
de Thèmes inclus dans un sous-menu de T-LAB
pour l'analyse des cooccurrences, cette option a été spécialement
conçue pour intégrer l'analyse thématique des contextes
élémentaires. Plus précisément : son usage a sens seulement lorsque
le corpus entier peut être considéré comme un discours et/ou lorsque ses différentes
sections (par exemple : chapitres d'un livre, parties d'une
entrevue, interventions de différents participants à une
conversation ou à une discussion, etc.) se succèdent dans un ordre
temporel précis. Étape par étape, de suite on fournit une brève description des différentes options disponibles. (N.B.: tous les output de l'exemple ont été obtenus à
travers une analyse thématique du livre The
Politics of Climate Change d' Anthony Giddens publiée sur le
site de T-LAB).
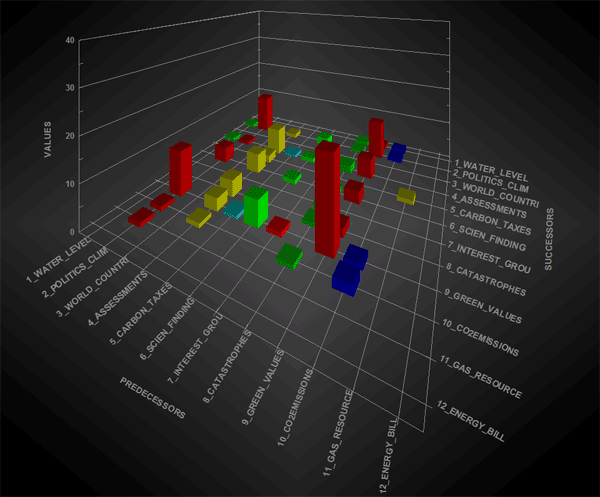
L' option "1" (voir ci-dessus) désigne le type de graphique choisi pour la visualisation des séquences, aussi bien à l' intérieur du corpus entier qu' à l' intérieur d' une partie de celui-ci (voir ci-dessus option "2"). L'option "matrice" fournit un graphique 3D qui résume les relations entre les prédécesseurs et les successeurs à l'aide de barres colorées placées aux croisements respectifs. Dans ce cas, lorsque des graphiques 3D animés sont visualisés, l' accroissement en hauteur des différentes barres indique l'augmentation des occurrences des séquences respectives (voir relations binaires entre "prédécesseurs" et "successeurs" dans le graphique suivant).
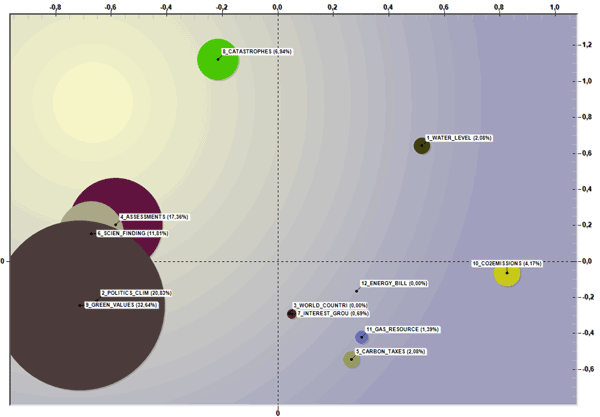
L'option "espace" fournit un graphique 2d dont les dimensions (c' est -à-dire les pourcentages) et les relations entre groupes thématiques sont représentées sur un plan organisé par deux axes factoriels sélectionnés par l'utilisateur. Dans ce cas, lorsque des graphiques animés sont affichés, les tailles des " bulles " - qui sont continuellement réadaptées à un total égal à 100 % - indiquent comment les pourcentages des éléments qui appartiennent à chaque cluster thématique varient avec le temps et, simultanément, le mouvement des flèches indique la direction dans laquelle les thèmes se suivent.
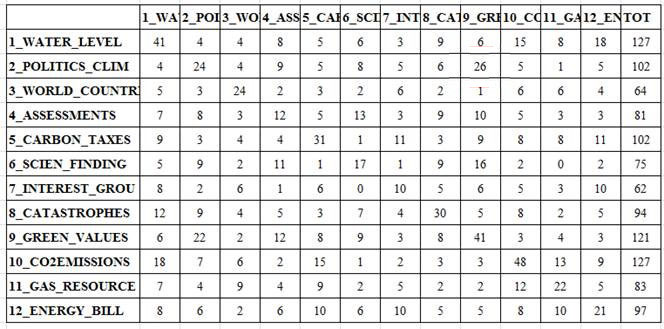
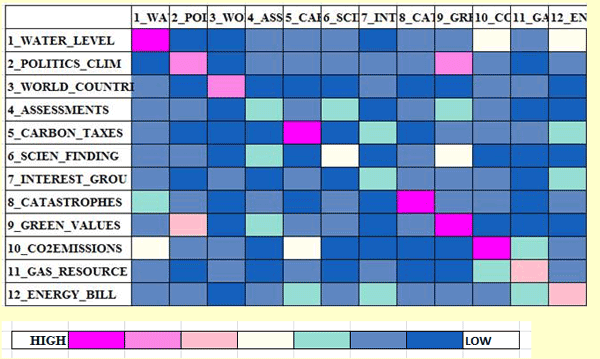
Dans les deux cas à peine décris, après l'arrêt de l' image (voir le bouton "pause"),on peut voir deux autres output : A - des tableaux html qui résument les relations entre les prédécesseurs et les successeurs (voir ci-dessous);
B - des fichiers graphiques qui peuvent être importés à partir d'un logiciel pour l'analyse de réseau.
N.B.: Le graphique précédent, qui fait référence au
troisième chapitre du livre de Giddens, a été créé au moyen du
logiciel Gephi (voir https://gephi.org/).
.
|