|
www.tlab.it
Occurrences et
Cooccurrences
Dans l'analyse des données textuelles les notions
d'occurrence et de cooccurrence ont une importance
fondamentale.
Les occurrences sont les
quantités qui résultent du calcul de combien de fois (fréquences)
une unité lexicale (LU, lexical unit)
est présent dans un corpus ou dans les
unités de contexte (CU, context units)
qui le composent.
Leur distribution peut être représentée en tableaux de
contingence tels que le suivant
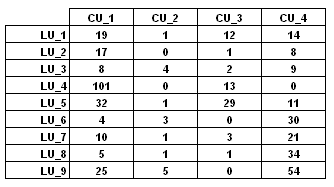
Les cooccurrences sont
des quantités qui résultent du calcul de combien de fois deux unité
lexicales sont présentes dans les mêmes contextes élémentaires (EC, elementary
contexts).
Leur distribution peut être représentée en tableaux du
type présence/absence tels que le suivant
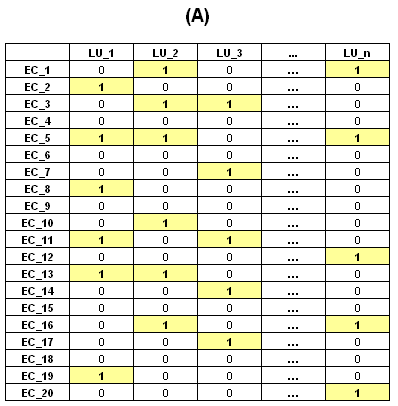
Avec une simple transformation, les tableaux du
type "A" (rectangulaire) peuvent être transformés en tableaux du
type "B" (carrés et symétriques) dans lesquels pour chaque couple
d'unités lexicale est indiquée la quantité de leurs cooccurrences,
c'est-à-dire le total de contextes élémentaires dans lesquels ils
sont présents simultanément.
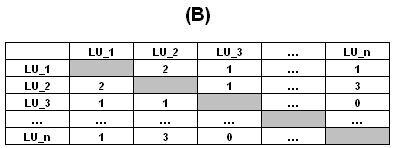
Dans T-LAB, la plupart des analyses des
textes sont effectuées par l'étude des rapports entre des
Occurrences et des Cooccurrences, par des index d'association spécifiques, ou par
l'utilisation des techniques statistiques multidimensionnelles
comme la Classification Hiérarchique
(Cluster Analysis) et l'Analyse des
Correspondances.
|


