|
www.tlab.it
Importer un fichier unique
...
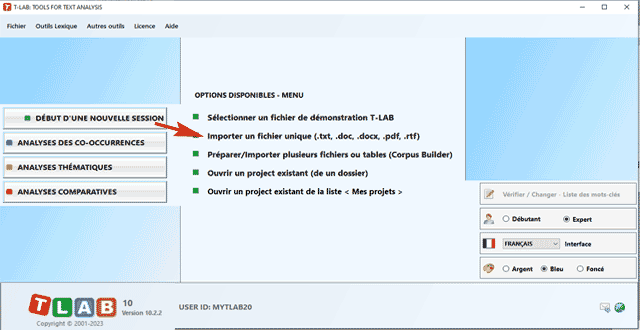
Dans le cas de textes uniques (ou corpus considéré
comme texte unique) on n'a pas besoin d' autre travail : il vous
suffit de sélectionner l'option 'Importer un fichier unique..'
(voir l'image ci-dessous):
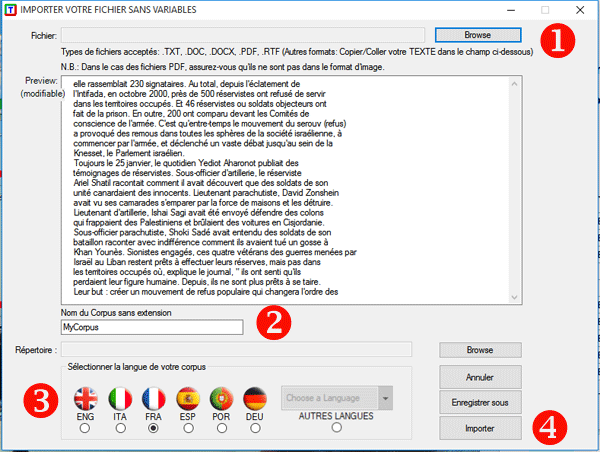
Ensuite, quatre étapes sont nécessaires (voir
l'image ci-dessous) : (1) sélectionner un fichier ;
(2) choisir le nom du projet ; (3) sélectionner la langue
de votre texte; (4) cliquer sur "Importer" .
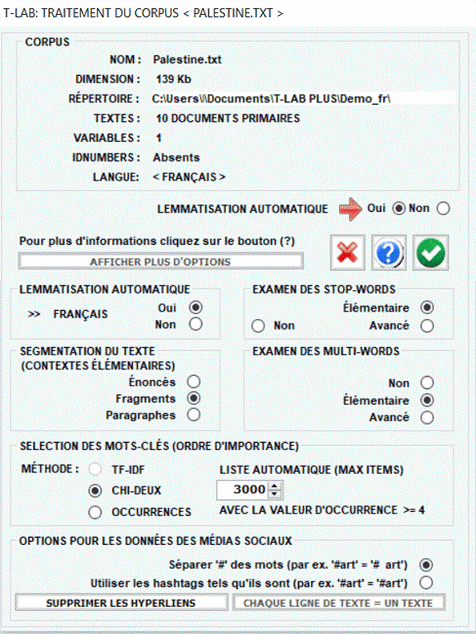
Ensuite une
fenêtre apparaît (voir ci-dessous) dans laquelle l'utilisateur peut
faire ses choix.
N.B.:
-
Puisque les options de prétraitement déterminent le type
et la quantité d'unités d'analyse (c.-à-d. des unités de contexte
et des unités lexicales), les différents choix de l'utilisateur
déterminent différents résultats de l'analyse. Pour cette raison,
tous les outputs de T-LAB (c.-à-d. graphiques et tableaux)
montrés dans le manuel et dans l'aide en ligne sont simplement
indicatifs;
- Toutes les étapes du prétraitement sont effectuées lors de
l'importation de tout type de corpus.
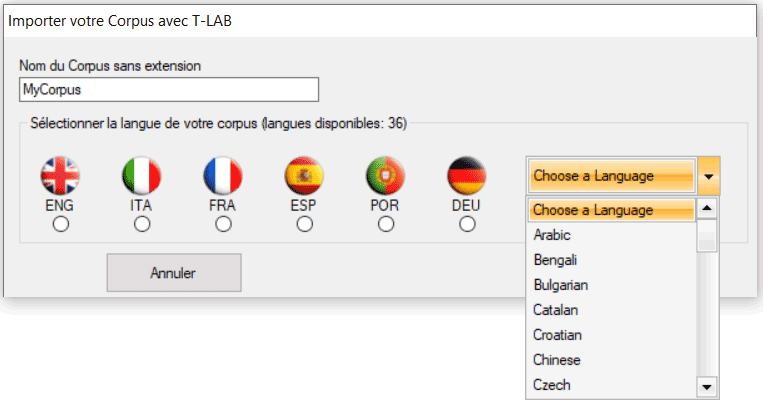
1 - LEMMATISATION AUTOMATIQUE OU
STEMMING
De suite la liste complète des trente langues pour
lesquelles la lemmatisation automatique ou bien le processus de
stemming sont supportés par T-LAB.
LEMMATISATION: allemand, anglais,
catalan, croate, espagnol, français, italien, latin, polonais,
portugais, roumain, russe, serbe, slovaque, suédois,
ukrainien.
STEMMING: arabe, bengali, bulgare, danois,
hollandais, finlandais, grec, hindi, hongrois, indonésien, marathi,
norvégien, persan, tchèque, turc.
En tout les cas, sans lemmatisation automatique et / ou
en utilisant des dictionnaires personnalisés, l'utilisateur peut
analyser textes dans toutes les langues, à condition que les mots
soient séparés par des espaces et/ou des signes de
ponctuation.
Le résultat du processus de lemmatisation peut être
vérifié avec la fonction Vocabulaire et
peut être modifié avec la fonction Personnalisation du Dictionnaire.
2 - SEGMENTATION DES TEXTES (CONTEXTES ÉLÉMENTAIRES)
Selon le choix de l'utilisateur, les types de contextes
élémentaires utilisés pour le calcul des co-occurrences peuvent être les suivants:
énoncés, fragments de longueur comparable, paragraphes ou textes
courts (ex. réponses aux questions ouvertes).
Le fichier corpus_segments.dat permet à
l'utilisateur de vérifier le résultat de la segmentation du
corpus.
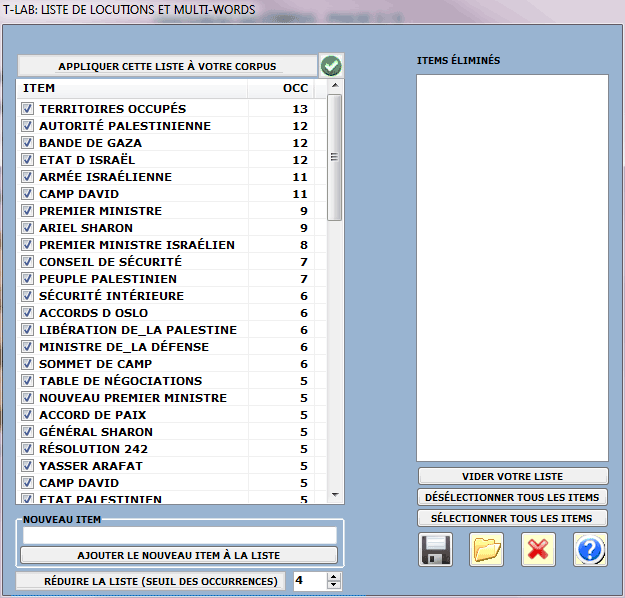
3 - EXAMEN DES MULTIWORDS
L'option "Élémentaire" active l'utilisation automatique
de la liste Multi-Words de
T-LAB.
Différemment l'option "Avancé", habilitée seulement avec
la lemmatisation automatique, permet à l'utilisateur de vérifier et
de modifier la liste des Multi-Words non inclus dans le
dictionnaire de T-LAB.
Il est aussi possible d'importer et d'employer d'autres fichiers Multiwords.txt.
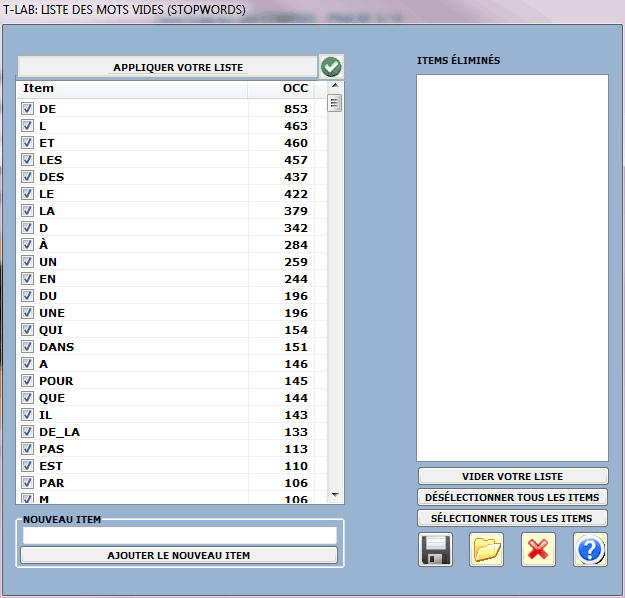
4 - EXAMEN DES STOPWORDS
L'option "Élémentaire" active l'utilisation automatique
de la liste Stop-Words de
T-LAB.
Différemment l'option "Avancé" permet à l'utilisateur de
vérifier et modifier la liste des Stop-Words présentes dans le corpus à
analyser.
Il est aussi possible d'importer et d'employer autres fichiers StopWords.txt.
5 - SÉLECTION DES
MOTS-CLÉS
Les options disponibles nous
permettent de choisir la méthode de choix (TF-IDF ou Chi-deux ) et la
quantité maximum d'unités lexicales à inclure dans une liste
employée par T-LAB
pour analyser les textes avec les configurations automatiques.
N.B.: Lorsque la phase d'importation
est terminée, en utilisant la configuration
personnalisée, l'utilisateur peut vérifier la sélection des
mots-clés et créer des listes différentes.
|


