|
www.tlab.it
Associations de
Mots
 N.B.: Les images de cette section font référence à une version
précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre: a) il y a une nouvelle option qui
permet à l'utilisateur de tracer une Carte
MDS avec les mots les plus pertinents; b) un nouveau bouton
(Graph Maker) permet à l'utilisateur de
créer et d'exporter plusieurs graphiques dynamiques au format HTML;
c) le bouton droit sur les tableaux
avec les mots-clés rend disponibles des options supplémentaires; d)
une galerie d'images à accès rapide qui fonctionne comme un menu
supplémentaire permet de basculer entre les différentes sorties en
un seul clic.
N.B.: Les images de cette section font référence à une version
précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre: a) il y a une nouvelle option qui
permet à l'utilisateur de tracer une Carte
MDS avec les mots les plus pertinents; b) un nouveau bouton
(Graph Maker) permet à l'utilisateur de
créer et d'exporter plusieurs graphiques dynamiques au format HTML;
c) le bouton droit sur les tableaux
avec les mots-clés rend disponibles des options supplémentaires; d)
une galerie d'images à accès rapide qui fonctionne comme un menu
supplémentaire permet de basculer entre les différentes sorties en
un seul clic.
Certaines de ces nouvelles fonctionnalités sont mises en évidence
dans l'image ci-dessous.
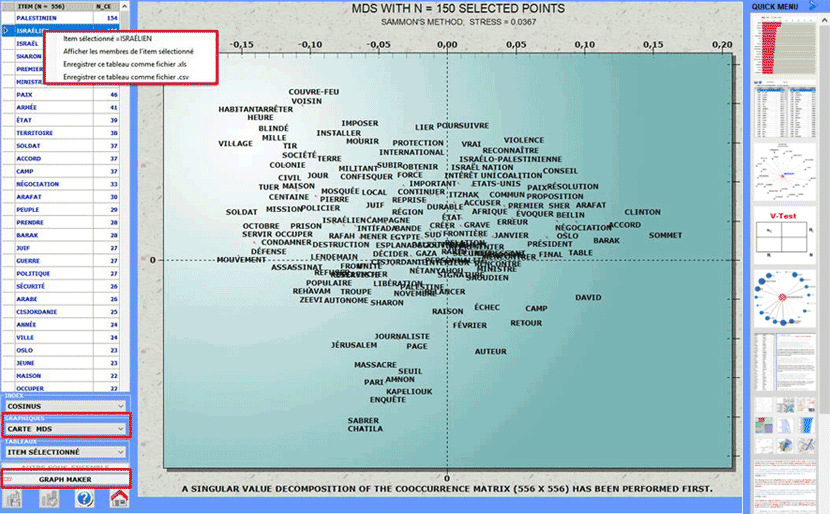
Cet outil T-LAB
nous permet de vérifier comment les relations de co-occurrence et de similarité qui, à l'intérieur
du corpus ou d'un de son sous-ensemble, déterminent le sens local
de mots clé sélectionnés par l'utilisateur.
Cette vérification peut être faite au moyen d'
options prédéfinies (A) ou à travers des options sélectionnées par
l'utilisateur (B).
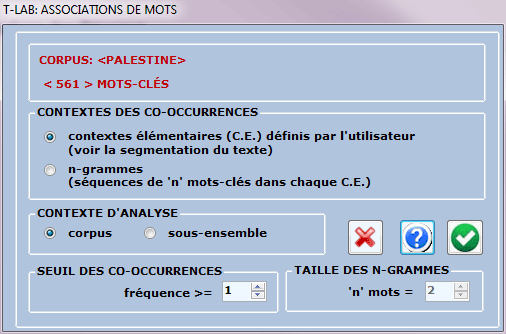
Dans le premier cas (A: options prédéfinies) les
cooccurrences des mots sont calculées
à l' intérieur des contextes
élémentaires sélectionnés en phase d'importation du corpus (ex.
phrases, fragments, paragraphes, etc.); différemment, dans le
second cas (B: options sélectionnées par l'utilisateur) les
cooccurrences peuvent aussi être calculées à l' intérieur de
séquences de mots de longueur variable (c'est-à-dire n-grammes, voir section du glossaire
correspondante) et il est aussi possible de décider le seuil
minimum (c'est-à-dire la fréquence) des cooccurrences à
considérer.
La fenêtre de travail (voir ci-dessous) devient disponible tout de
suite après avoir effectué le calcul des cooccurrences entre tous
les mots inclus dans la liste sélectionnée par
l'utilisateur.
À gauche de cette fenêtre il y a un tableau avec la
liste des mots et les valeurs numériques qui indiquent la quantité
de contextes élémentaires ou de n-grammes dans lesquels chaque mot
résulte présent.
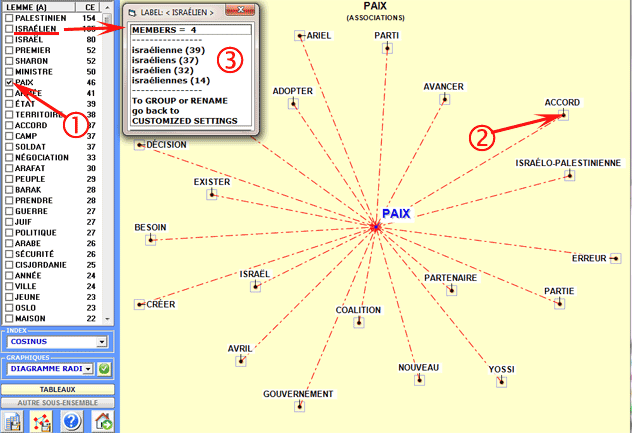
Un simple clic sur les mots du tableau (option "1") ou sur les
points des graphiques (option "2") permet de vérifier les
associations relatives à chaque mot cible. Différemment, un click
sur les labels inclus dans le tableau (option "3") permet de
vérifier les items inclus dans chaque lemme.
De fois en fois, la sélection des mots associés est effectuée à
travers le calcul d'un Index
d'Association (voir section correspondante du glossaire) ou par
un index de ressemblance du deuxième ordre (voir explication à la
fin de cette section). Dans le premier cas les index disponibles
sont six (Cosinus, Dice, Jaccard, Équivalence, Inclusion et
Informartion Mutuelle) et leur calcul est plutôt rapide ;
différemment, dans le cas des index du deuxième ordre - et surtout
lorsque le corpus est de dimensions considérables - l'analyse des
données peut demander plusieurs minutes. En outre, il faut tenir
compte du fait que, dans le cas des index du deuxième ordre, les
résultats sont aussi plus fiables que plus nombreux sont les mots
inclus dans la liste.
Pour chaque interrogation, T-LAB produit graphiques et tableaux.
Soit les graphiques soit les tableaux peuvent être sauvés utilisant
les boutons appropriés.
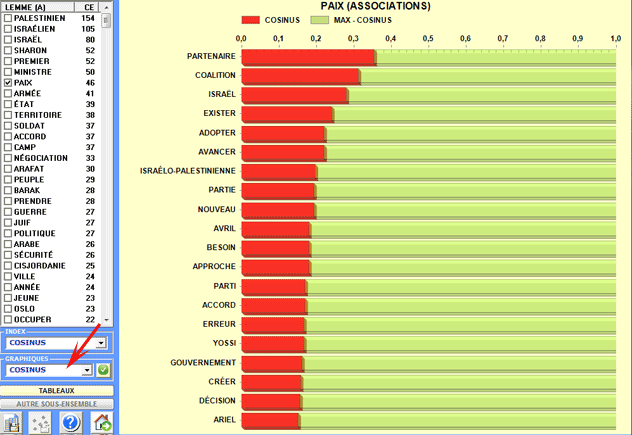
Dans le diagramme radial, le lemme
choisi est placé au centre. Les autres sont distribués autour de
lui, chacun à la distance proportionnelle à son degré
d'association. Les rapports significatifs sont donc du type "un à
un" entre le lemme central et chacun des autres.
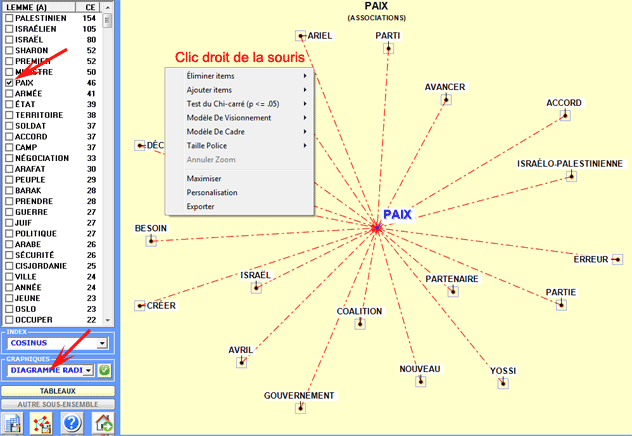
Chaque clic sur un item produit un nouveau diagramme et, en
employant le bouton droit de la souris, il est possible
d'ouvrir une fenêtre de dialogue qui permet plusieurs
personnalisations des graphiques.
Les tableaux
contiennent des données qui permettent de vérifier les relations
entre occurrences et cooccurrences des mots (Max. 50) qui résultent
les plus associés à celui sélectionné.
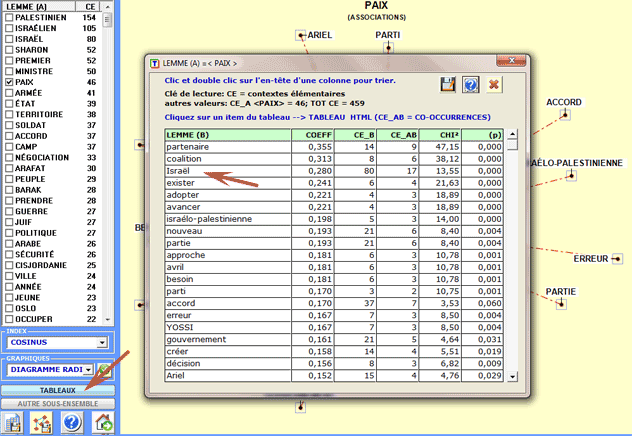
Les clés de lecture sont les
suivantes:
- LEMME (A) = lemme
sélectionné;
- LEMME (B) = lemmes
associés avec le LEMME (A);
- COEFF = valeur de
l'index d'association sélectionné;
- TOT CE = total des contextes élémentaires (CE) ou des n-grammes
analysés;
- CE_A = total des CE
dans lesquels le lemme sélectionné (A) est présent;
- CE_B = total des CE
dans lesquels chaque lemme associé (B) est présent;
- CE_AB = total des CE
dans lesquels les lemmes "A" e "B" sont associés
(co-occurrences);
- CHI2 = valeur du Chi
Deux (signification des co-occurrences);
- (p) = probabilité
associée à la valeur du chi-deux (def=1).
Dans le cas du Chi
Deux, pour chaque couple de lemmes ("A"
e B") la structure du tableau analysé est la
suivante.
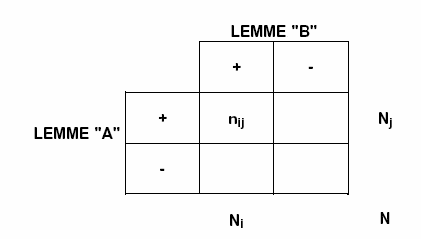
Avec : nij = CE_AB; Nj = CE_A; Ni = CE_B; N = TOT
CE.
Un clic sur chaque étiquette (par exemple "Israël") permet de
sauvegarder un fichier avec tous les contextes élémentaires
(c.-à-d. phrases ou paragraphes) où il est en couple avec le mot
choisi (co-occurrences de "paix" et "Israël").

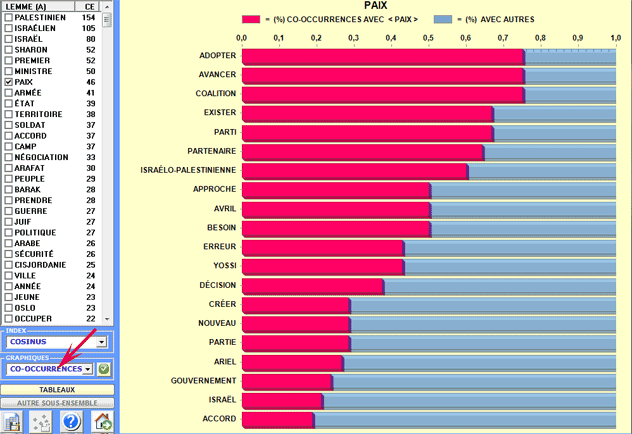
D'autres graphiques (Histogrammes) nous permettent
d'apprécier les valeurs du coefficient
utilisé et les pourcentages des
co-occurrences.
En cliquant sur le bouton en bas à gauche,
l'utilisateur peut exporter différents types
de tableaux (voir l'image ci-dessous).
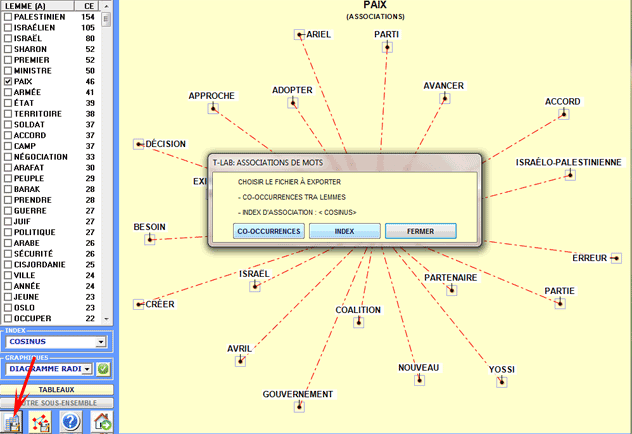
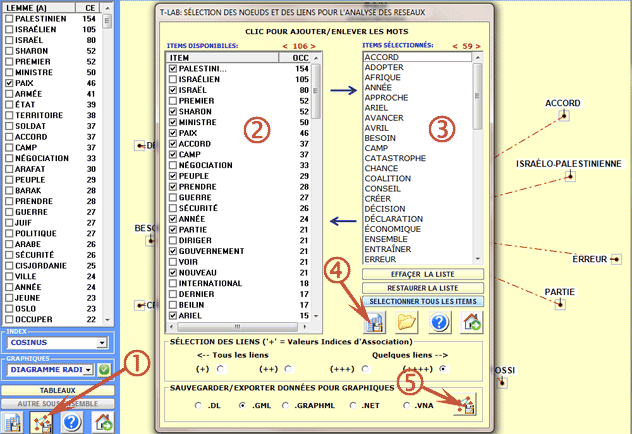
Une autre fenêtre T-LAB (voir image suivante, étape 1) permet de
créer des fichiers graphiques qui peuvent être édités avec un
logiciel pour le network analysis comme Gephi, Pajek, Ucinet, yEd
et d'autres encore. Dans ce cas, les nœuds du réseau sont
constitués par les mots associés au mot cible. Les options
disponibles sont les suivantes : sélectionner les items
(c'est-à-dire les " nœuds") à insérer dans les graphiques (voir
ci-dessous, étapes 3 et 4), exporter le type de fichier graphique
sélectionné (voir ci-dessous, étape 5).
N.B.: En T-LAB 10 la
fenêtre suivante a été remplacée par l’outil Graph Maker.
Par exemple, des fichiers .gml exportés par
T-LAB peuvent permettre de réaliser des
graphiques comme les suivantes.
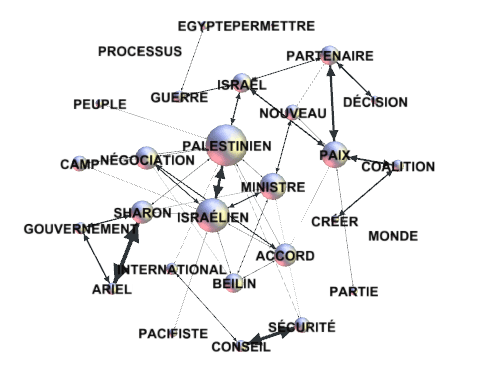
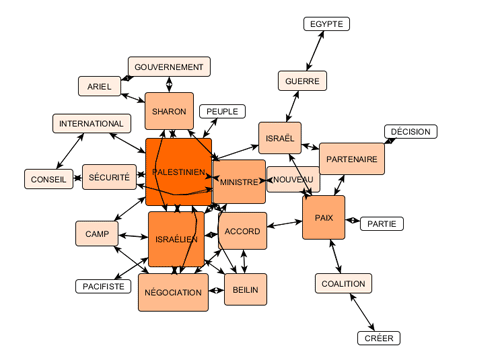
N.B.: Le premier graphique a été créé au moyen de
Gephi (https://gephi.org/ ), le second au
moyen de yEd (http://www.yworks.com/en/products_yed_download.html/
), deux logiciels disponibles en téléchargement gratuit.
Les modalités de calcul des différents index
d'association (ou proximité) sont illustrées dans la section
correspondante du Manuel/Aide (voir glossaire). Comme on pourra vérifier, tous ces
index sont obtenus à travers une normalisation des valeurs de
cooccurrence qui concernent des couples de mots; donc - dans les
calculs du premier ordre - deux mots
jamais co-occurrents ont un index d'association égal à "0".
Différemment, les index du deuxième
ordre soulignent des phénomènes de "similarité" concernant
l'usage (et donc le sens) des mots qui ne dépendent pas directement
de leurs cooccurrences; en effet, dans ce cas, deux mots jamais
co-occurrents peuvent avoir un index d'association même très
élevé.
En utilisant certains concepts de la linguistique
structurelle, nous pouvons affirmer que, pendant que les index du
"premier ordre" relèvent des phénomènes qui concernent l' axe
syntagmatique (combinaison et proximité "in praesentia",
c'est-à-dire des mots "l'un à coté de l'autre" dans une phrase
spécifique) les index du "deuxième ordre" relèvent des phénomènes
qui concernent l'axe paradigmatique (association et similarité "in
absentia", c'est-à-dire des relations de quasi synonymie entre deux
ou plusieurs termes utilisés par le même auteur..
Pour comprendre la façon dont T-LAB calcule les index du "deuxième ordre",
il est utile de rappeler que les index du "premier ordre" peuvent
être utilisés pour construire des matrices de proximité comme la
suivante (A).
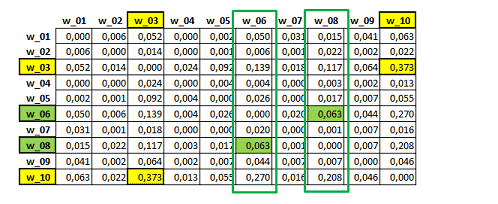
Matrice 'A' - similarité du premier ordre
Dans cette matrice symétrique (A) la valeur 0.373 (en jaune)
correspond à l'index le plus élevé du "premier ordre" et il indique
l'association entre les mots "w_03" et "w_10". Plus précisément, il
s'agit d'un index d'équivalence obtenu en divisant le carré de
leurs cooccurrences par le produit de leurs occurrences
(360^2/267*553).
À partir de la matrice ci-dessus (A), T-LAB construit une deuxième matrice (B)
obtenue en calculant les cosinus résultants de la comparaison de
toutes les colonnes qui contiennent les index du premier ordre
(voir matrice 'A'). Comme on peut vérifier, dans le tableau 'B'
suivant , la valeur de "similarité" plus élevée concerne la
relation entre les mots "w_06" et "w_08". Ceci signifie que les
vecteurs respectifs (voir les deux colonnes soulignées en vert dans
la matrice 'A') résultent être entre eux très semblables (cosinus
=0.905), même si l'association du "premier ordre" entre les deux
mots en question résulte plutôt basse (0.063).
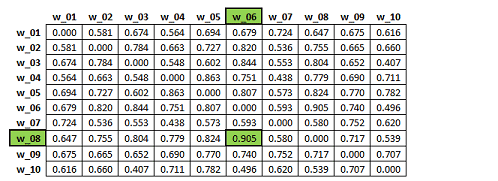
Matrice "B" : similarité du deuxième
ordre.
Autrement dit, un index du "premier ordre" est obtenu en appliquant
une formule qui inclut des valeurs de cooccurrence et occurrence,
pendant qu'un index du "deuxième ordre" est obtenu en multipliant
deux vecteurs normalisés.
Au-delà des modalités de calcul, il faut souligner le fait que dans
les deux cas ("A" et "B") deux différents phénomènes sont relevés.
Dans le premier cas ("A"), en effet, le focus est sur les
cooccurrences; différemment, dans le second cas ("B") - et
indépendamment de leurs cooccurrences - le focus est sur les
ressemblances entre "profils" dont les données font référence à
l'usage des mots de la part des auteurs des textes analysés.
Juste pour faire un exemple, dans l'analyse de Pinocchio du premier
ordre le terme "fée" résulte généralement associé (voir
cooccurrences) avec "gentille" et "cheveux bleus"; différemment,
dans l'analyse du second ordre, le terme qui résulte le plus
semblable à "fée" est "maman" , même si les cooccurrences entre ces
deux termes ("fée" et "maman" ) sont - à l'intérieur du conte de
fées de Collodi - presque insignifiantes (c'est-à-dire seulement
3).
Les tableaux visualisés par T-LAB permettent de vérifier soit les
similarités du deuxième ordre (voir sous colonne SIM-II°) soit les
index du premier ordre (EQU-I°, c'est-à-dire index
d'équivalence).
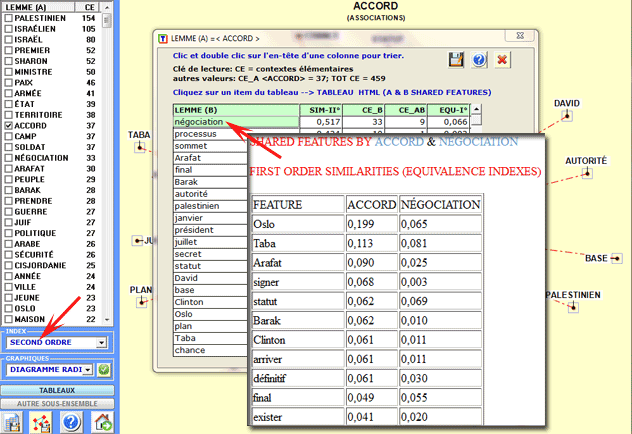
En outre, en cliquant sur chaque item de ce tableau, il est
possible de visualiser des fichiers HTML qui permettent de vérifier
quelles caractéristiques ("features") déterminent la ressemblance
entre chaque couple de mots. Par exemple, le tableau suivant montre
que la similarité du deuxième ordre entre "accord" et "négociation"
est en premier lieu déterminée par des caractéristiques partagées
telles que "Oslo", "Taba", "Arafat", etc.
|


