|
www.tlab.it
Classification Thématique des
Documents
Cette fonction est activée uniquement lorsque le corpus
que l'on analyse comprend d'un minimum de 20 à un maximum de 99.999
documents primaires.
Le processus d'analyse peut être effectué au moyen d'une
méthode de clustering "non supervisée" (dans le cas particulier, un
algorithme de bisecting K-Means) ou à travers une classification
supervisée (c'est-à-dire une approche top-down). Lorsqu'on choisit
la deuxième (c'est-à-dire la classification supervisée), on vous
demande d'importer un dictionnaire des catégories, soit qu'il soit
créé par une analyse précédente de T-LAB que construit par l'utilisateur.
Son utilisation permet de construire des classes de
documents et d'explorer leurs caractéristiques à l'aide
d'opérations/options semblables à celles qui sont décrites dans la
section de l'aide dédiée à l'Analyse
Thématique des Contextes Elémentaires.
Sa spécificité consiste dans le fait que le tableau
analysé est formé par un nombre de lignes égal à celui des
documents du corpus, chacun desquels est représenté comme un
vecteur de valeurs indiquant les occurrences des mots qu'il
contient.
En outre, lorsque les documents analysés ne dépassent pas
les 3000, on peut obtenir des mesures de similarité (index du
cosinus) entre chacun d'eux et tous les autres (voir ci-dessous).
N.B. : dans ce cas le seuil minimum de l' 'index de similarité est
fixé à 0,05.
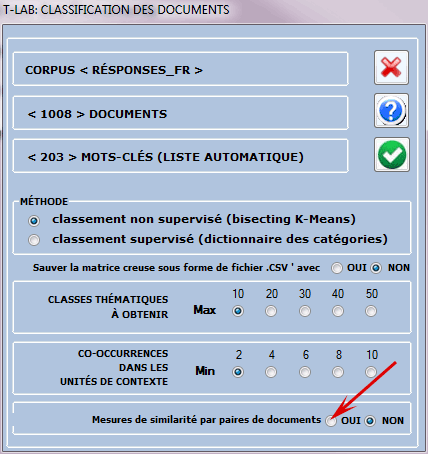
D'ailleurs les outputs suivants sont
différents:
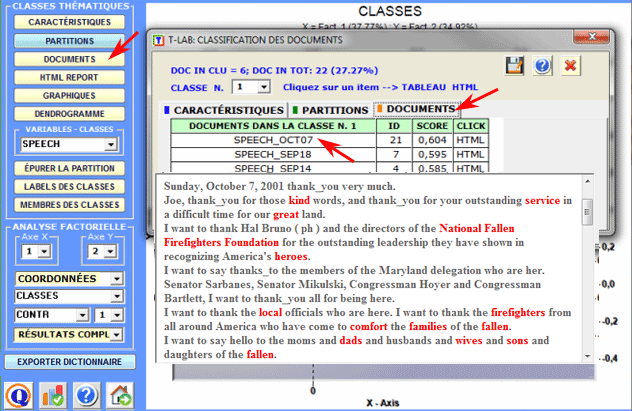
Les documents appartenants à chaque classe sont ordonnés
par la valeur décroissante de leur importance et peuvent être
explorés dans le format HTML.
Dans ce cas-ci la valeur d'importance (score) assignée à
chaque document (i) de la classe (k) est obtenue en appliquant la
formule suivante:
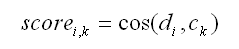
Où:
i - se réfère au document i;
k - se réfère à la classe k;
cos - est le symbole du cosinus;
di - est le vecteur normalisé du TFj, i IDFj, où
j se réfère à un mot du document i ;
ck - est le vecteur normalisé du de TFj, k IDFj, où
j se réfère à un mot de la classe k.
En employant les scores obtenus par la formule ci-dessus,
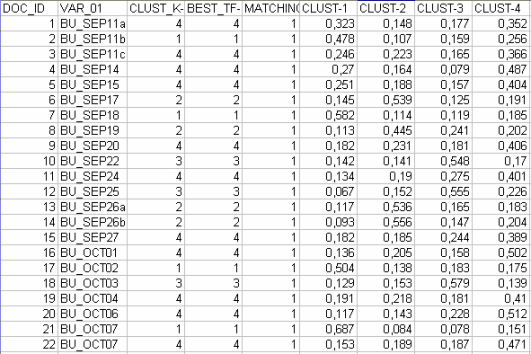
qui sont transformés en pourcentages, T-LAB rend disponible le fichier
"Document_Membership_Degree.xls " (voir ci-dessous) contenant les
classes auxquelles les documents sont assignés, soit par le
bisecting K-Means (appartenance exclusive de chaque document à un
classe) soit par le TF-IDF(appartenance mélangée de chaque document
aux différentes classes).
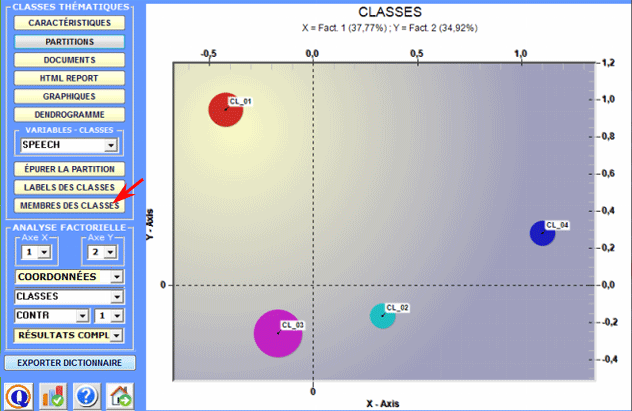
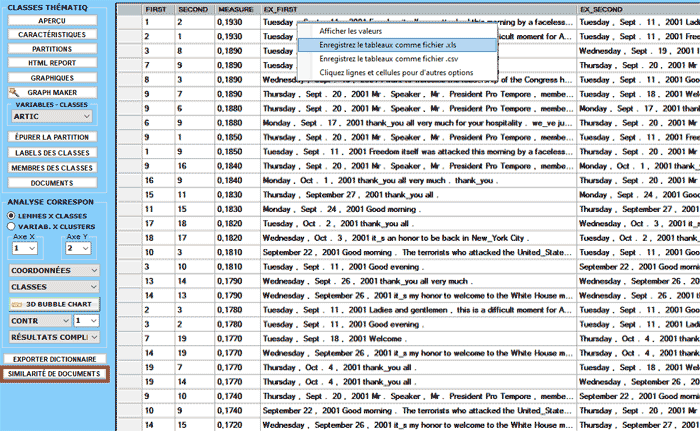
Lorsque le bouton Similarité de
Documents est activé, en cliquant dessus on peut vérifier
dans quelle mesure chaque document est similaire à chacun des
autres. Dans ce cas, la mesure de similarité est le coefficient du
cosinus et sa valeur varie en fonction de combien de mots ont été
utilisés pour le classement thématique.
L'image suivante décrit les options disponibles pour ce
genre de vérification.
Lorsqu'on quitte cette fonction, des messages rappellent
qu'il est possible d'explorer les classes obtenues avec d'autres
outils T-LAB.
Si on choisit l'option "Sauvegarder", la variable <
DOC_CLUST > (classes de documents)
demeure disponible pour toutes les analyses suivantes du même
corpus effectuées avec d'autres outils T-LAB.
|



