|
www.tlab.it
Analyse des
Correspondances
 N.B.: Les
images de cette section font référence à une version précédente de
T-LAB. En T-LAB 10, l'aspect est légèrement différent.
En outre : a) le bouton droit sur les
tableaux avec les mots-clés rend disponibles des options
supplémentaires; b) il y a un nouveau bouton (TREE MAP PREVIEW) qui permet à l'utilisateur de
créer plusieurs graphiques dynamiques au format HTML; c) deux
nouveaux boutons nous permettent de vérifier les spécificités de chaque variable en utilisant le
test du Khi-deux ou la valeur test; d) il y a un bouton qui permet
de réaliser une analyse de clusters qui
utilise les coordonnées des objets (selon les cas, d' unités
lexicales ou d' unités de contexte) sur les premiers axes
factoriels (jusqu'à un maximum de 10); e) une galerie d'images à
accès rapide qui fonctionne comme un menu supplémentaire permet de
basculer entre les différentes sorties en un seul clic. N.B.: Les
images de cette section font référence à une version précédente de
T-LAB. En T-LAB 10, l'aspect est légèrement différent.
En outre : a) le bouton droit sur les
tableaux avec les mots-clés rend disponibles des options
supplémentaires; b) il y a un nouveau bouton (TREE MAP PREVIEW) qui permet à l'utilisateur de
créer plusieurs graphiques dynamiques au format HTML; c) deux
nouveaux boutons nous permettent de vérifier les spécificités de chaque variable en utilisant le
test du Khi-deux ou la valeur test; d) il y a un bouton qui permet
de réaliser une analyse de clusters qui
utilise les coordonnées des objets (selon les cas, d' unités
lexicales ou d' unités de contexte) sur les premiers axes
factoriels (jusqu'à un maximum de 10); e) une galerie d'images à
accès rapide qui fonctionne comme un menu supplémentaire permet de
basculer entre les différentes sorties en un seul clic.
Certaines de ces nouvelles fonctionnalités sont mises en évidence
dans l'image ci-dessous..
Cet outil T-LAB a le but de mettre en évidence les
similitudes et les différences entre les unités de contexte.
Plus précisément, dans
T-LAB,l'analyse
de correspondance nous permet d'analyser trois genres de
tableaux:
(A) tableaux mots par variable,
avec les valeurs des occurrences;
(B) tableaux contextes élémentaires par mots, avec les
valeurs des co-occurrences;
(C) tableaux
documents par mots, avec les valeurs des occurrences.
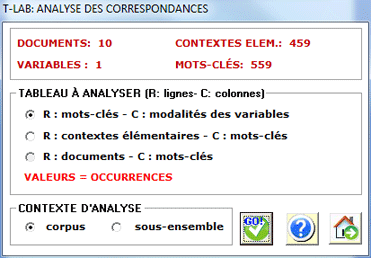
Pour analyser les tableaux (A) lemmes (ou mots) par variables, le
corpus doit se composer de trois textes au minimum ou être codifié
avec quelques variables (pas moins de
trois modalités).
Les variables sont énumérées dans une boîte appropriée et
peuvent être employées une à la fois.
Après chaque choix, T-LAB montre le tableau de contingence
correspondant et vous êtes invités à cliquer le bouton analyser (voir ci-dessous).
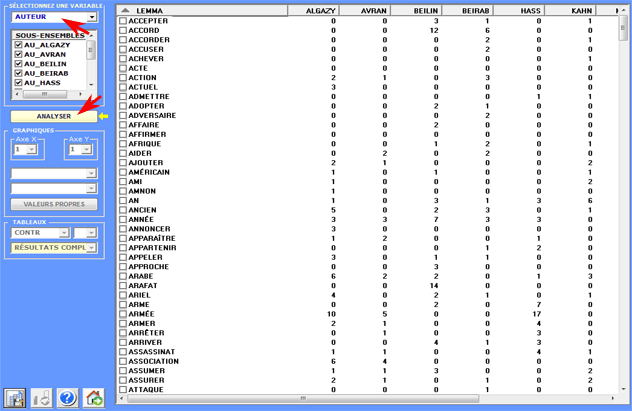
Le résultat de l'analyse se compose de tableaux à partir
desquels T-LAB produit des diagrammes où sont
représentés les rapports entre les sous-ensembles du corpus et
entre les unités lexicales dont ils font partie.
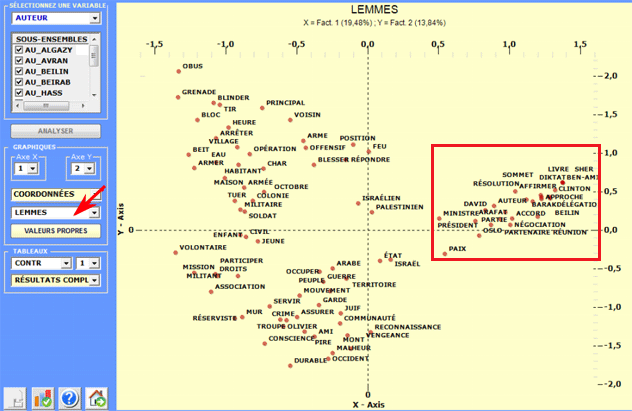
Plus précisément, selon les cas, les types de graphiques
disponibles montrent les relations entre variables actives, entre variables illustratives, entre lemmes, entre
lemmes et variables.
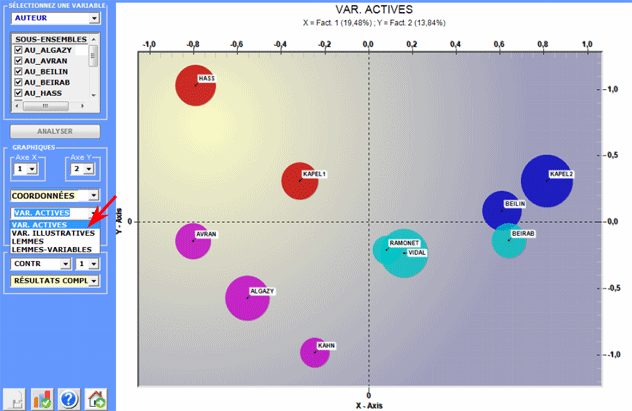
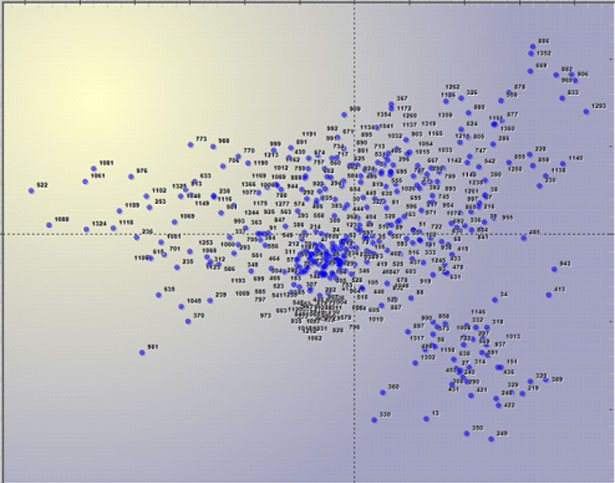
En outre, lorsque le tableau analysé est du genre
documents pour mots, on peut voir les points (Max 3000) qui
correspondent à chaque document.
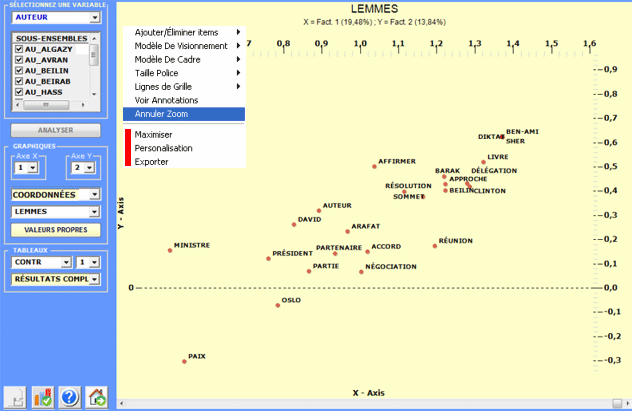
Tous les graphiques peuvent être maximisés et
personnalisés en employant la boîte de dialogue appropriée
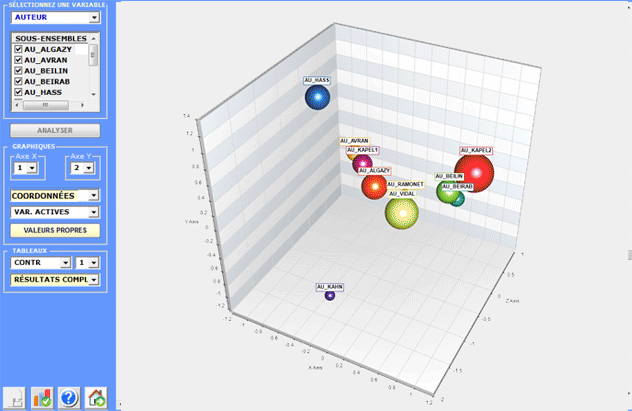
(utiliser le bouton droit de la souris). D'ailleurs, quand les
catégories variables sont 3 ou plus, leurs rapports peuvent être
explorés en 3d (voir ci-dessous).
Pour explorer les diverses combinaisons des axes
factoriels il suffit de les sélectionner dans les boîtes
appropriées ("Axe X", "Axe Y").
Pour chaque axe
factoriel T-LAB fournit deux tableaux qui aident à
l'interprétation: celles avec les Contributions Absolues et celles avec les Valeurs Test.
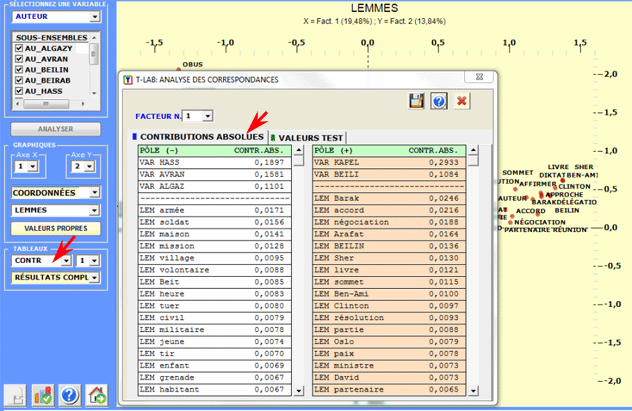
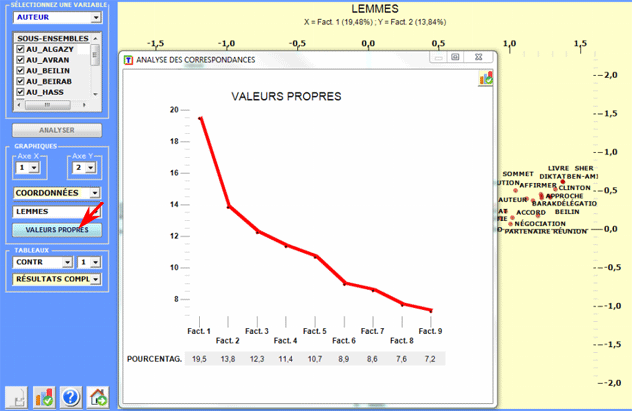
En utilisant l'histogramme des valeurs-propres il est
possible d'apprécier l'importance relative de chaque facteur
c.-à-d. le pourcentage d'inertie qu'ils déploient.
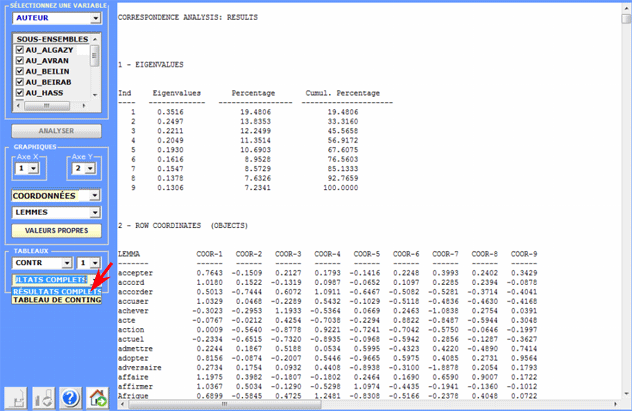
Un clic sur le bouton "Résultats Complets" vous
permet de visualiser et de sauvegarder le fichier qui contient tous
les résultats de l'analyse: valeurs propres, coordonnées,
contributions absolues et relatives, valeurs test.
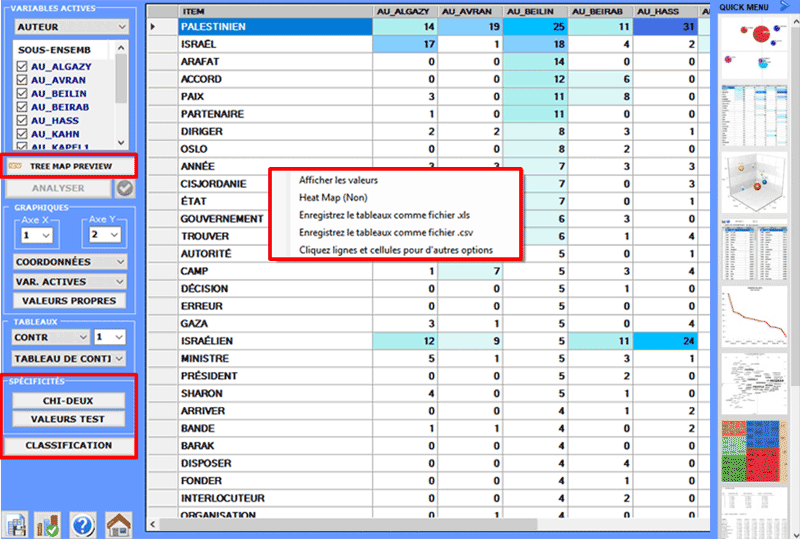
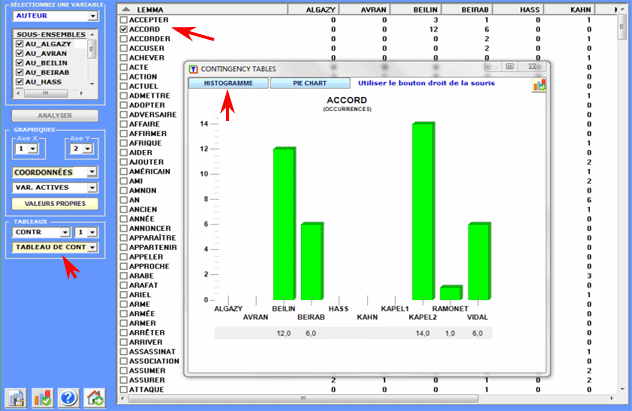
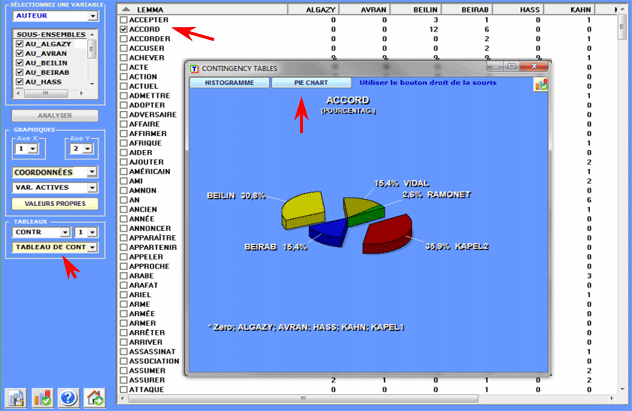
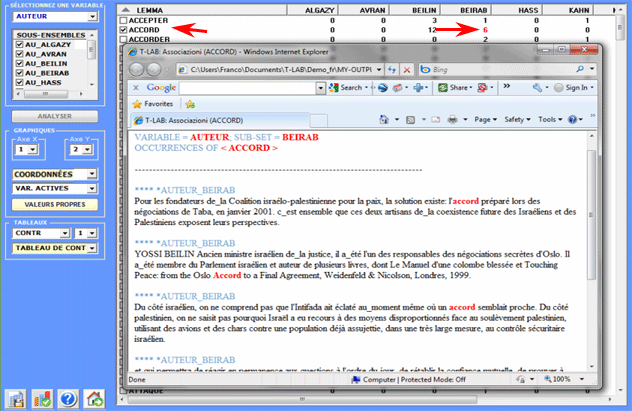
Tous les tableaux de contingence peuvent être facilement
explorés et nous permettent de créer différents types des
graphiques. De plus, en cliquant sur cellules spécifiques du
tableau (voir ci-dessous), il est possible de créer un fichier HTML
montrant tous les contextes élémentaires où le mot en ligne est
présent dans le sous-ensemble correspondant.
Dans le cas des tableaux (B) et (C),
elles sont constituées par autant de lignes que sont les unités de
contextes (max 10.000) et autant de colonnes que sont les Mots-Clés
sélectionnés (max 3.000).
L'algorithme de calcul et les résultats sont semblables à ceux de
l'analyse unités lexicales par variables, sauf que dans ce cas,
pour limiter le temps d'élaboration, T-LAB se limite à extraire les
premiers 10 facteurs: un nombre plus que suffisant pour condenser
la variabilité des données.
En outre, on peut par la suite effectuer deux types de
classification dont les "objets" sont
aussi bien constitués par des Mots-Clés que par des segments
(contextes élémentaires).
|


