|
www.tlab.it
Spécificités
 N.B.: Les images de cette section font référence à une version
précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En particulier, à partir de la version 2021,
une galerie d'images à accès rapide qui fonctionne comme un menu
supplémentaire permet de basculer entre les différentes sorties en
un seul clic De plus l'utilisateur est autorisé à évaluer
facilement les similitudes (ex. -Distance textuelle) entre les
sous-ensembles du corpus (de 2 à 150), et donc aussi pour détecter
les documents quasi-dupliqués et quasi-dupliqués (voir les images
ci-dessous).
N.B.: Les images de cette section font référence à une version
précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En particulier, à partir de la version 2021,
une galerie d'images à accès rapide qui fonctionne comme un menu
supplémentaire permet de basculer entre les différentes sorties en
un seul clic De plus l'utilisateur est autorisé à évaluer
facilement les similitudes (ex. -Distance textuelle) entre les
sous-ensembles du corpus (de 2 à 150), et donc aussi pour détecter
les documents quasi-dupliqués et quasi-dupliqués (voir les images
ci-dessous).
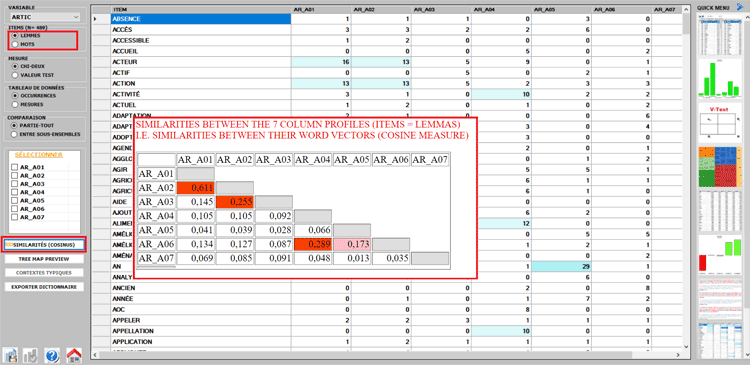
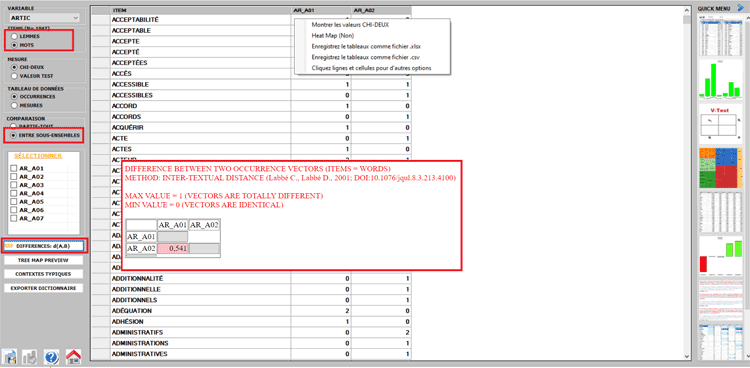
Cet outil T-LAB permet de vérifier quelles unités lexicales (c'est-à-dire mots, lemmes ou
catégories) sont typiques ou
exclusives dans un texte ou un
sous-ensemble du corpus défini par une
variable catégorielle; en outre il permet aussi d'identifier les
unités de contexte caractéristiques
des différents sous-ensembles en examen (par exemple les phrases
"typiques" qui mieux différencient les discours des divers leaders
politiques).
Les unités lexicales
typiques, définies par la proportion des
occurrences respectives (c'est-à-dire par leur sur / sous-
utilisation), sont déterminées par le calcul Chi-Carré ou par la Valeur
Test.
Les contextes
élémentaires caractéristiques sont
identifiés en calculant et en additionnant les valeurs TF-IDF normalisées assignées aux mots dont chaque
phrase ou chaque paragraphe est constitué.
L'analyse de spécificités nous permet d'effectuer deux
types de comparaisons:
1 - entre une partie
(ex. le sous-ensemble "A") et le tout (ex. le corpus entier "B");
2 - entre des couples de
sous-ensembles ("A" e "B").
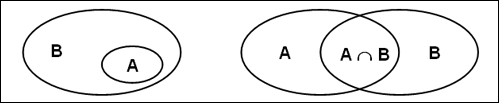
Dans chacun des cas on peut aussi bien analyser les
Spécificités relatives aux intersections que celles relatives aux
différences.
Les modalités du calcul sont montrées dans l'entrée
correspondante du glossaire.
Les unités lexicales considérées peuvent être
toutes (configuration automatique) ou seulement celles choisies par
l'utilisateur (configuration
personnalisée).
En succession, les quatre types de comparaisons possibles
sont les suivantes:
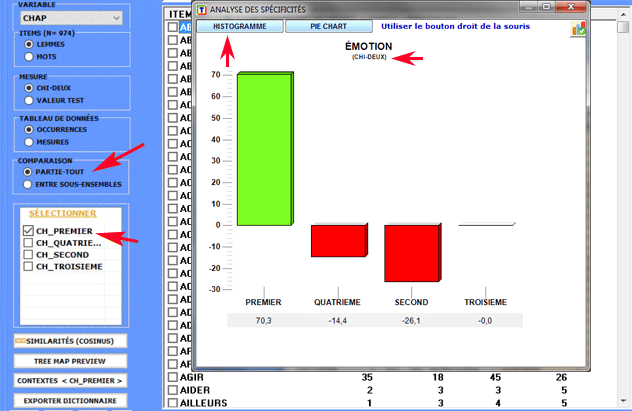
1.1 -
partie/tout: unités lexicales " typiques"
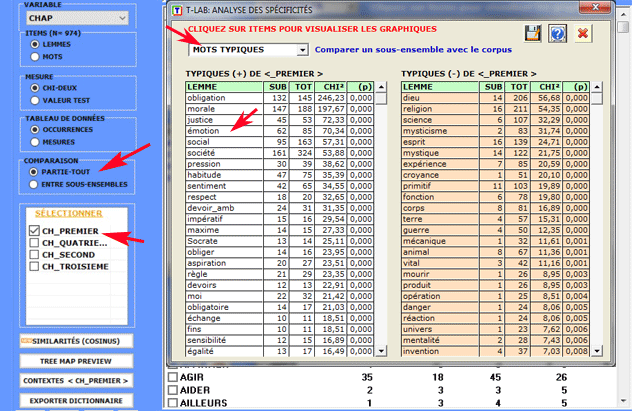
Colonne par colonne les clés de lecture du tableau sont
les suivantes:
- LEMME = unités lexicales "spécifiques" (sur-utilisées ou
sous-utilisées);
- SUB = occurrences de chaque LEMME dans le sous-ensemble
examiné;
- TOT = occurrences de chaque LEMME dans le corpus ou dans les deux
sous-ensembles examinés (voir 2.1);
- CHI2 = valeur du CHI deux (ou VTEST = Valeur Test);
- (p) = probabilité associée à la valeur du chi-deux
(def=1).
En cliquant sur les éléments des tableaux, il est
possible de créer différents types des
graphiques.
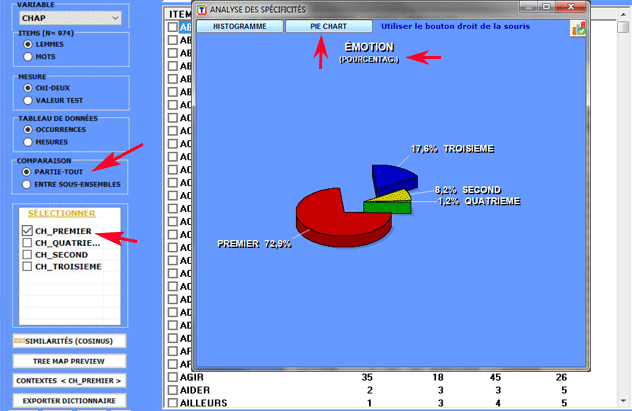
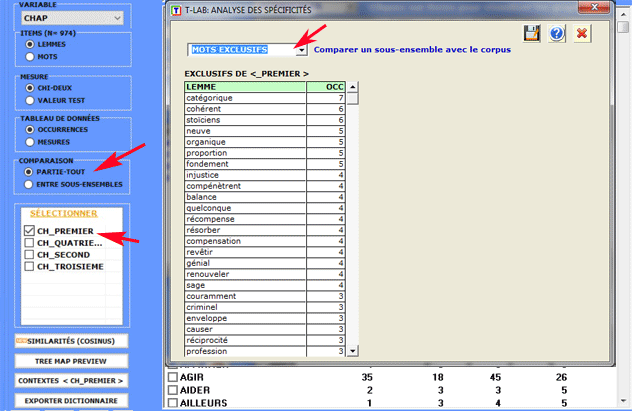
1.2 - partie/tout: unités lexicales "exclusives"
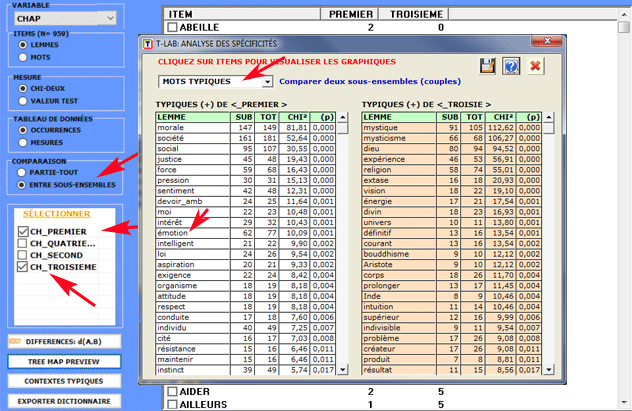
2.1 - sous-ensemble/sous-ensemble: unités
lexicales "typiques"
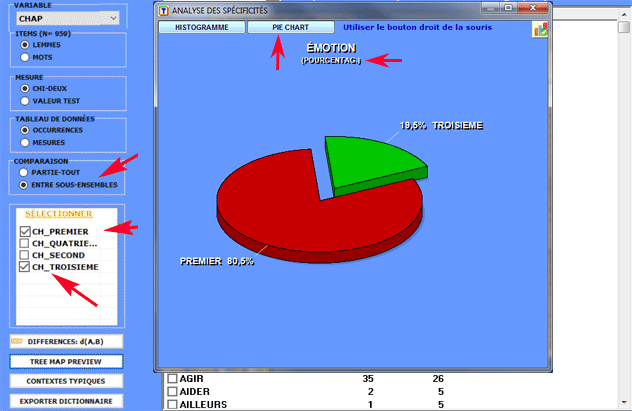
2.2 - sous-ensemble/sous-ensemble: unités
lexicales "exclusives"
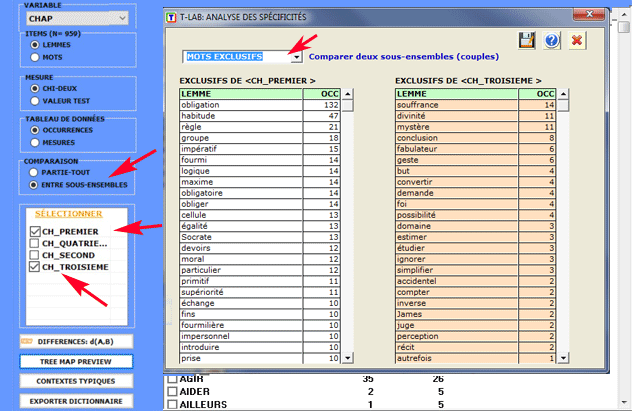
Pour chaque sous-ensemble analysé il est aussi possible de
vérifier les contextes élémentaires (c'est-à-dire phrases ou
paragraphes) qui mieux le distinguent des autres. Dans ce cas, la
spécificité résulte du calcul de valeurs
TF-IDF normalisées; plus particulièrement,
le "score" attribué à chaque contexte élémentaire (voir l'image
ci-dessous) est le résultat de la somme des valeurs TF-IDF
assignées aux mots qui le composent.
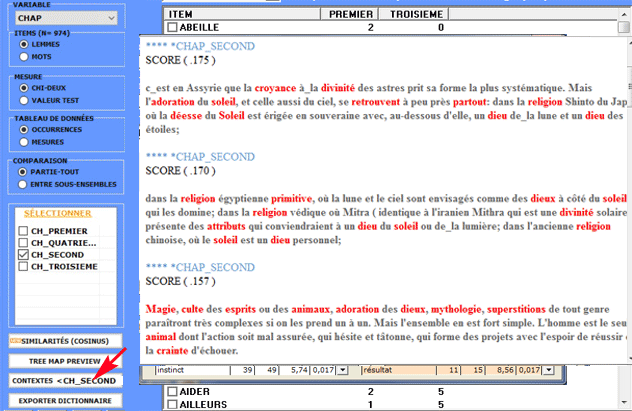
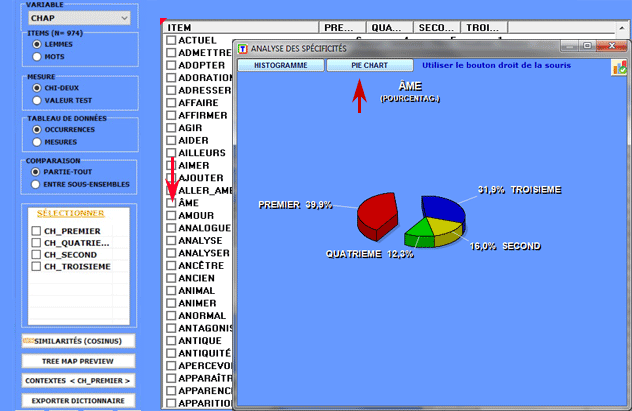
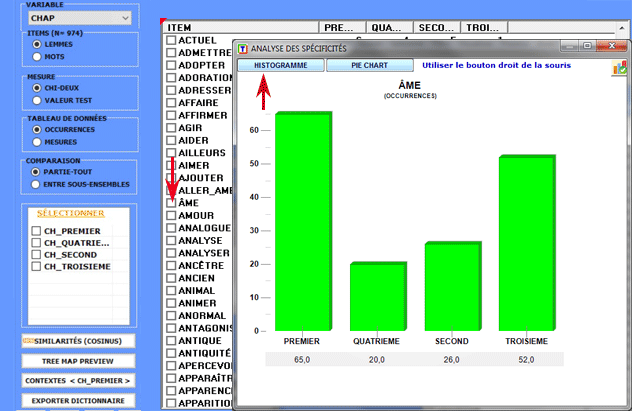
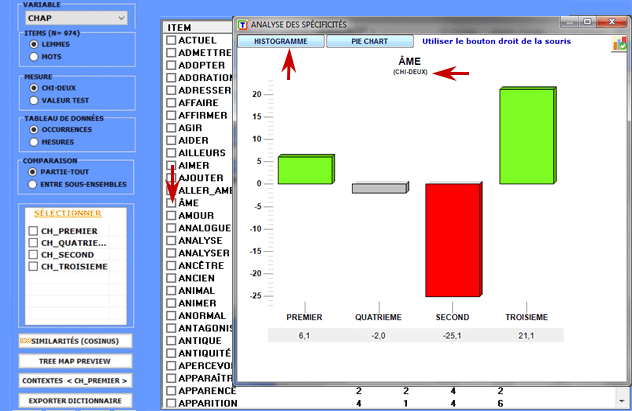
Tous les tableaux de contingence peuvent être facilement
explorés et nous permettent de créer différents types des
graphiques. De plus, en cliquant sur cellules spécifiques du
tableau (voir ci-dessous), il est possible de créer un fichier HTML
montrant tous les contextes élémentaires où le mot en ligne est
présent dans le sous-ensemble correspondant.
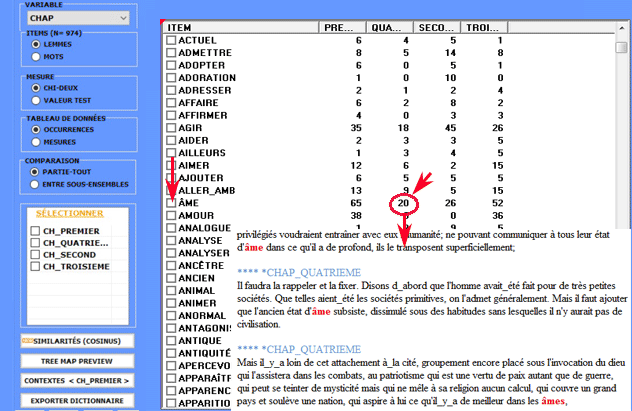
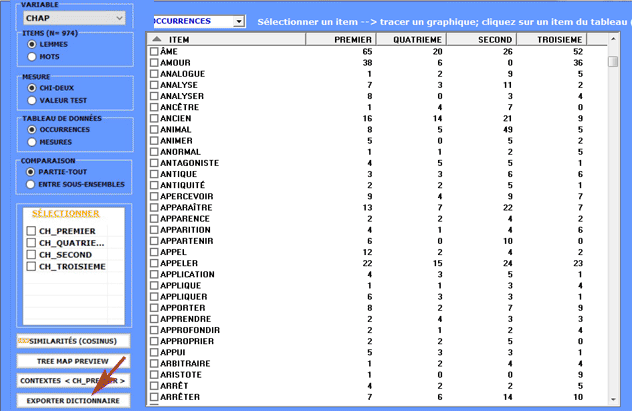
Finalement, en cliquant sur
l'option appropriée (voir ci-dessous), un fichier dictionnaire avec l'extension .dictio est créé,
qui est prêt à être importé par les outils T-LAB pour l'analyse
thématique. Ce dictionnaire comprend tous les mots typiques
de la variable catégorielle sélectionnée.
|


