|
www.tlab.it
Lemmatisation
Dans les dictionnaires que nous pouvons consulter,
chaque entrée correspond à un lemme
qui - généralement - définit un ensemble de mots avec la même
racine (ou lexème) et qui appartiennent à la même catégorie
grammaticale (verbe, adjectif, etc.).
En général, la lemmatisation se fait de la manière suivante: les
formes de verbes à l'infinitif, les noms au singulier, les
adjectifs au masculin singulier et ainsi de suite.
Par exemple, les formes fléchies
"parlait" et "parlassent", résultant d'une combinaison d'une
racine (< parl- >) et deux
différents suffixes (< - ait > et < - assent >), sont
ramenées au même lemme (< parler > ).
Il y a, cependant, certains cas pour lesquels la lemmatisation
n'observe pas la règle de la racine, par exemple dans le cas de
verbes irréguliers.
Pendant la phase d'importation du corpus,
T-LAB réalise un genre spécifique de
lemmatisation automatique qui suit la logique de l' "arbre" suivant
:
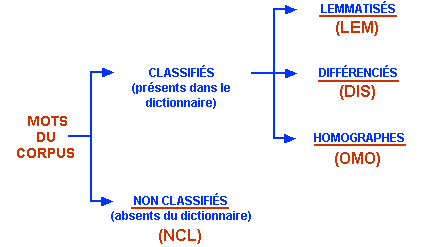
Évidemment, le dictionnaire de référence est celui de
T-LAB.
Les abréviations des quatre catégories sont employées dans beaucoup
de tableaux, toujours dans la colonne " INF ".
N.B.:
- la catégorie "DIS " ("à distinguer") signifie que T-LAB
n'applique pas la lemmatisation standard, pour ne pas annuler les
significations différentes au sein des différentes formes (par
exemple : < bien > et <biens >);
- parfois, afin de différencier les homographes, T-LAB ajoute le caractère '_' (tiret bas) à leur
lemme.
|


