|
www.tlab.it
Analyse des Séquences et
Analyse de Réseaux
Cet outil T-LAB tient compte des positions
des différentes unités lexicales à l'intérieur des phrases et il
nous permet de représenter et d'explorer n' importe quel texte
comme un réseau de relations
Les différentes options disponibles peuvent être
utilisées pour des buts tels qu'analyses Co-Word, analyses
thématiques et désambiguïsations.
En effet, après avoir construit deux matrices dans
lesquelles tous les couples de prédécesseurs et successeurs sont
enregistrés, T-LAB calcule les probabilités de
transition (chaînes de Markov) et il fournit différents outputs
qui concernent les mots cible.
En outre, il est possible d'exécuter un cluster analysis et
d'explorer les relations sémantiques entre les mots soit à
l'intérieur du réseau entier qu'à l'intérieur de "clusters
thématiques" (N.B: Dans ce cas-ci, l'algorithme de clustérisation
est constitué par la "méthode Louvain" développée par Blondel V.D.,
Guillame J.-L, Lambiotte R., Lefebre E., 2008).
CCeci signifie, après avoir exécuté ce type
d'analyse, que l'utilisateur peut vérifier les relations entre les
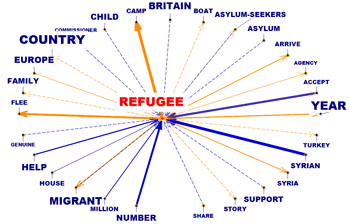
nœuds du réseau (c'est-à-dire les mots-clés) à plusieurs niveaux:
a) en relations du type un-à-un; b) à l'intérieur d' "ego network";
c) à l'intérieur des "communautés" auxquelles ils appartiennent; d)
à l'intérieur du réseau entier constitué par le texte en
analyse.
|
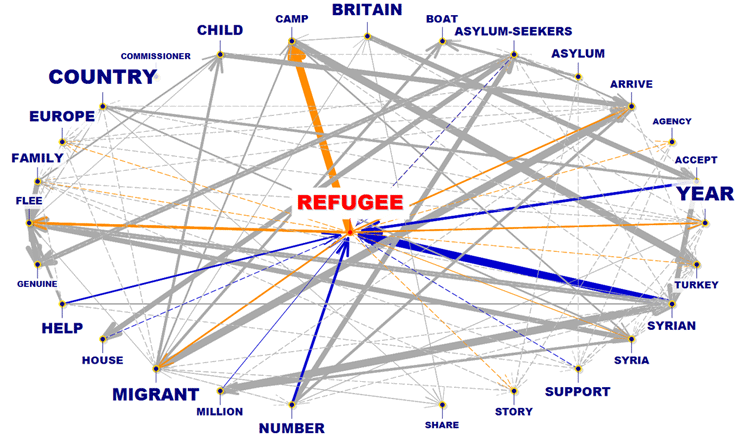
RELATIONS UN-À-UN
|
EGO-NETWORK
|
|

|
|
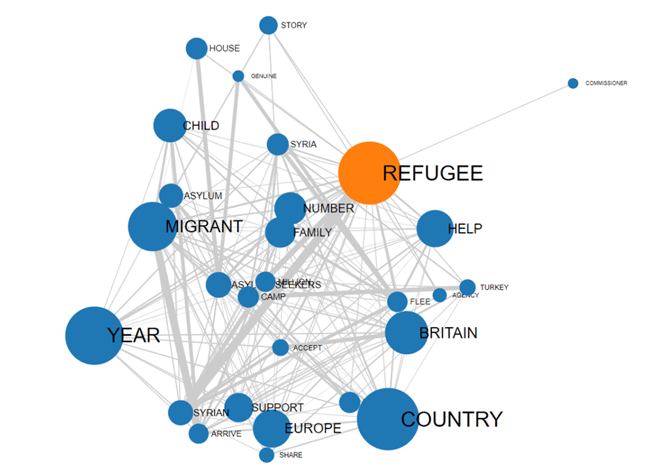
COMMUNAUTES
|
RÉSEAU ENTIER
|

|
|
Les renseignements sur l'utilisation des
différentes options d'analyse sont organisés en trois
sections:
A - Explorer les connexions du type un-à-un et les
"ego network;
B - Explorer les "communautés" (c'est-à-dire les clusters
thématiques) et le réseau entier;
C - Certains détails techniques.
N.B.: Pour motifs d'édition, cette page inclut des
exemples d'analyse tirés d'un corpus dont les textes sont en
anglais.
A - EXPLORER LES CONNEXIONS DU TYPE UN-À-UN ET
LES "EGO NETWORK"
Quand l'analyse automatique est terminée, divers
graphiques et tableaux qui permettent de vérifier les relations et
les données qui concernent les mots-clés sélectionnés sont
disponibles (N.B: à ce but il est suffisant de cliquer sur un item
des tableaux ou sur un point quelconque montré dans les
graphiques).
Tous les graphiques peuvent être
personnalisés et exportés en divers formats (utiliser le bouton
droit de la souris).
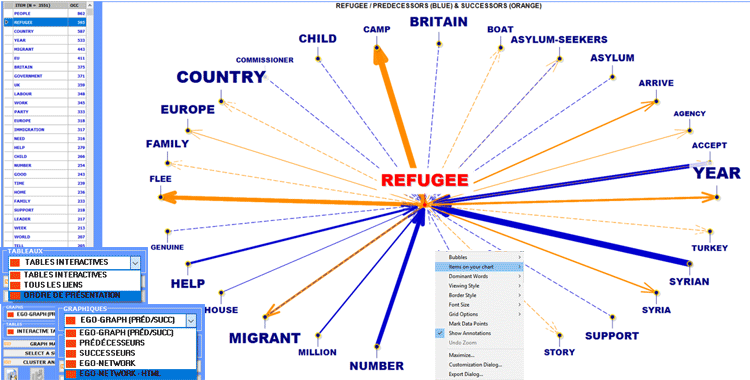
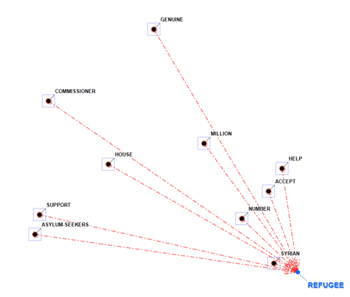
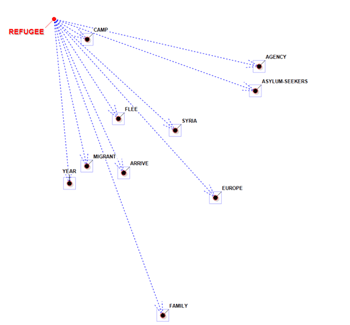
En deux des graphiques, les éléments les plus
voisins à ceux sélectionnés sont ceux qui ont les probabilités les
plus élevées de venir devant (prédécesseurs) ou après (successeurs)
de ceux-ci.
|
PREDECESSEURS
|
SUCCESSEURS
|
|
|
Dans les autres cas, la proximité entre les
termes-clés est représentée par les différentes épaisseurs des
flèches qui les joignent (voir ci-dessous).
Toutes les données peuvent être vérifiées au moyen
de plusieurs types de tableaux.
En détail:
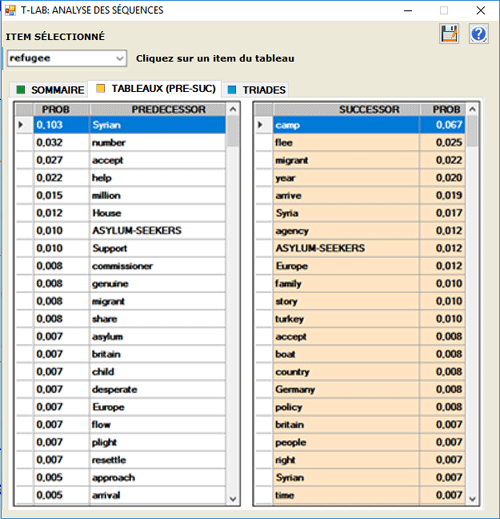
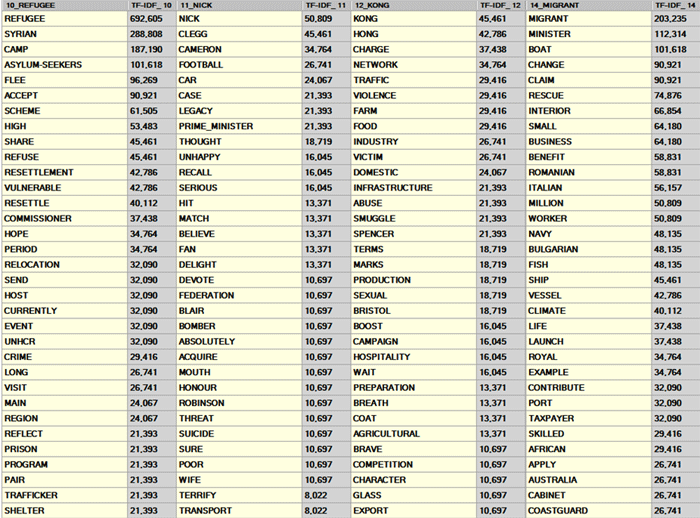
Les TABLEAUX INTERACTIFS montrent les listes
des prédécesseurs et des successeurs associés avec les mots-clés
sélectionnés.
La liste est en ordre décroissant selon les valeurs
de probabilité ("PROB"). Par exemple, dans le tableau suivant, la
probabilité que "camp" suive "refugee" est égale à 0.067, c.-à-d.
le 6.7%.
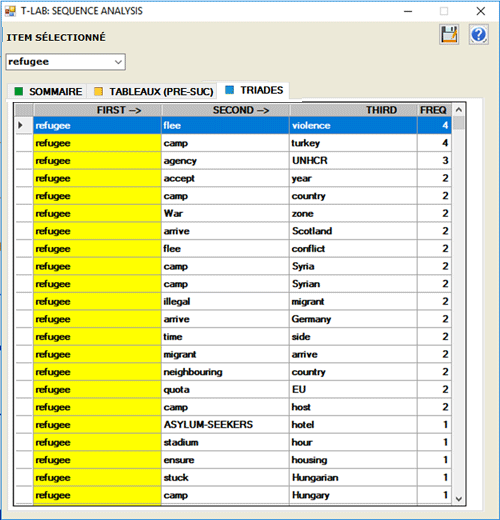
L'option TRIADES nous permet de visualiser
quelques tables avec des séquences de trois éléments dans lesquels,
selon le choix de l'utilisateur, le mot choisi est dans la
première, dans la deuxième ou dans la troisième position. Pour
chaque triade T-LAB montre les valeurs d'occurrence
correspondantes. (N.B.: Dans les triades les mots vides ne sont pas inclus).
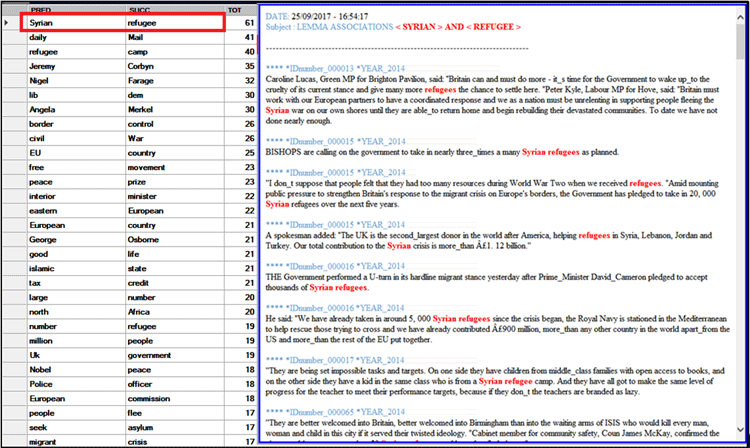
Le tableau TOUS LES LIENS (voir ci-dessous),
qui est particulièrement utile pour désambiguïser les sens des
mots, contient tous les couples de prédécesseurs et de successeurs,
et aussi les occurrences respectives. En faisant clic sur une ligne
de ce tableau, tous les segments de texte, (c'est-à-dire les
contextes élémentaires) dans lesquels les deux membres de chaque
couple sont présents en même temps (c'est-à-dire co-occurrences),
seront visualisés en format HTML sur le côté droit du
tableau.
Le tableau RANG D'APPARITION, avec la
fréquence et l'ordre moyen d'apparition (ou d'évocation) de chaque
terme à l'intérieur des segments de texte, est visible seulement
quand le corpus est constitué par des textes brefs, par exemple des
réponses à des questions ouvertes.
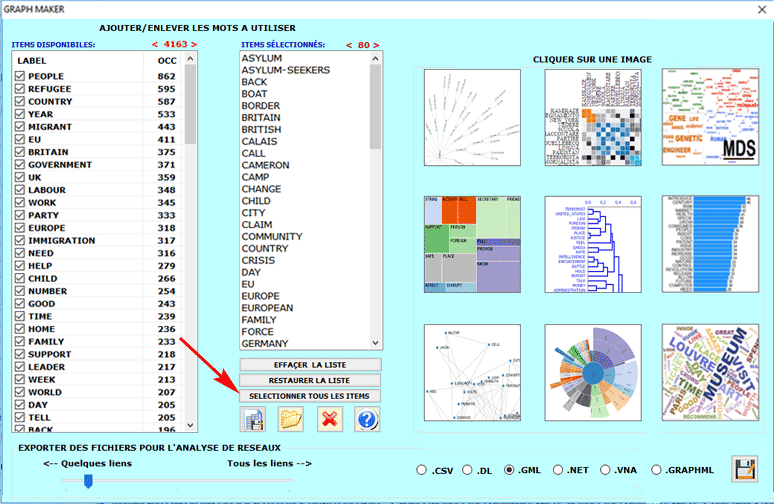
À n'importe quel moment, en faisant clic sur
l'option GRAPH MAKER, l'utilisateur peut créer des
différents types de graphiques en utilisant des listes
personnalisées de mots-clés (voir ci-dessous).
N.B.: Les utilisateurs experts intéressés à exporter des fichiers
en formats divers (par exemple .dl .gml etc.) avec les données
relatives à tous les links, peuvent faire clic sur le bouton
"SÉLECTIONNER TOUS LES ITEMS".
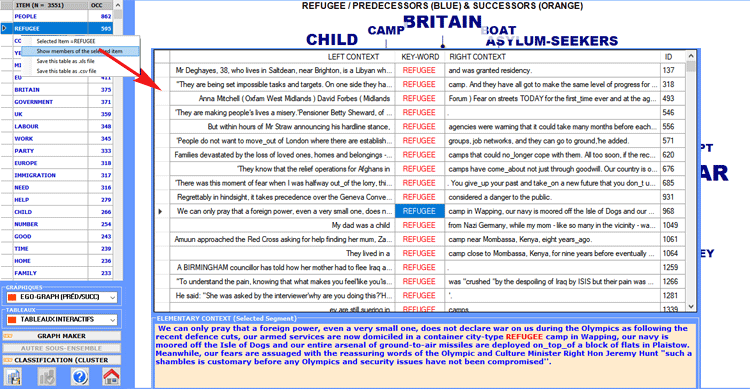
À n'importe quel moment, en utilisant le bouton
droit, it il est possible de vérifier les concordances de chaque
mot (voir ci-dessous).
B -
EXPLORER LES " COMMUNAUTÉS " (C'EST-À-DIRE LES CLUSTERS
THÉMATIQUES) ET LE RÉSEAU ENTIER
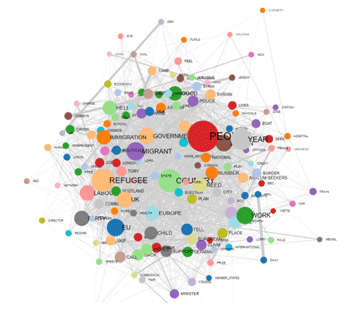
Quand on fait une analyse cluster, d' autres
graphiques et tableaux sont disponibles. Ils sont tous marqués
avec un petit rectangle bleu (voir ci-dessous).
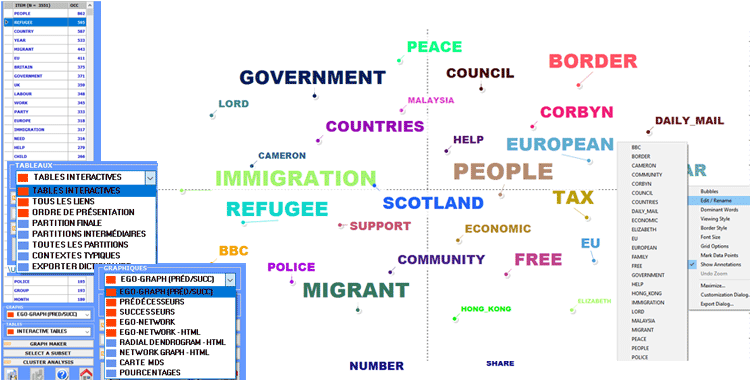
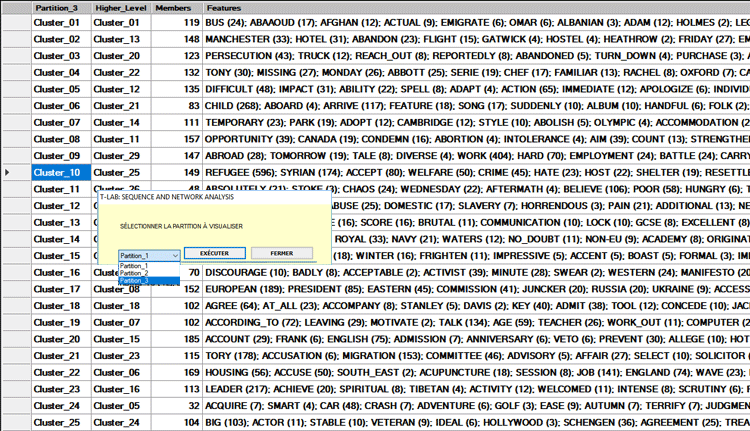
Un premier tableau résume les caractéristiques
(c'est-à-dire les termes-clés), de la PARTITION FINALE
obtenue par l'algorithme de clustérisation.
Dans ce tableau, les caractéristiques de chaque cluster thématique
sont ordonnées par la valeur relative TF-IDF (voir
ci-dessous).
N.B : Lorsqu'un cluster de la partition finale comprend seulement
deux mots, habituellement cela signifie qu'un cas de multiword n'a
pas été résolu pendant la phase de pré-traitement.
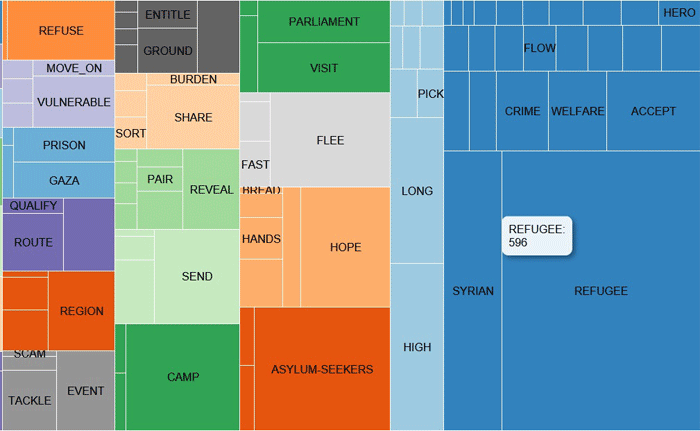
En cliquant sur n'importe quel mot dans le tableau
ci-dessus (ainsi que dans le tableau TOUTES LES PARTITIONS),
un TreeMap nous permet de vérifier les communautés auxquelles il
appartient (voir ci-dessous).
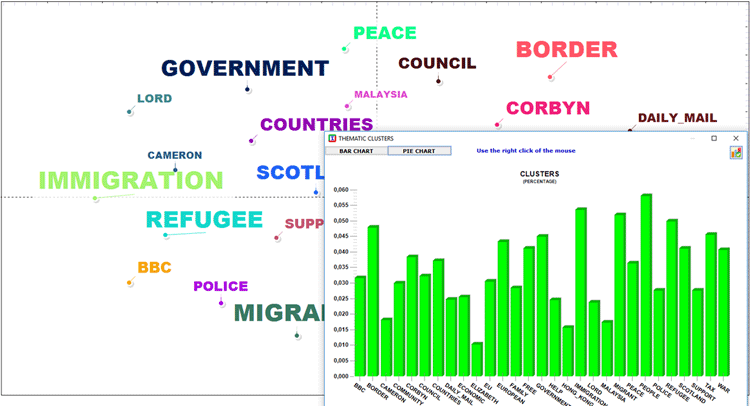
La CARTE MDS et le graphique
POURCENTAGES nous permettent de vérifier le "poids" de
chaque cluster ainsi que les relations entre les différents
clusters à l'intérieur de la partition finale (voir
ci-dessous)..
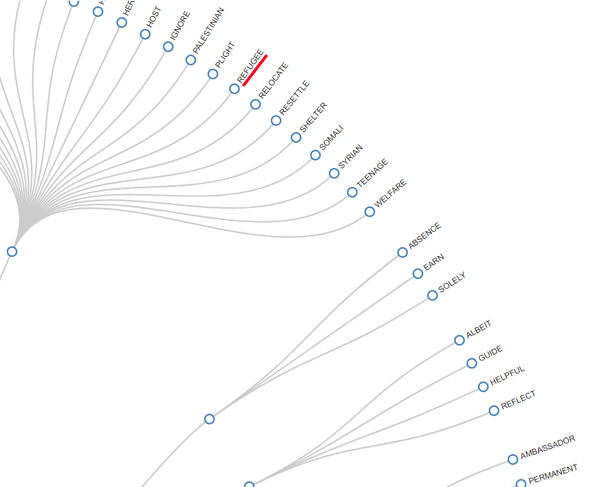
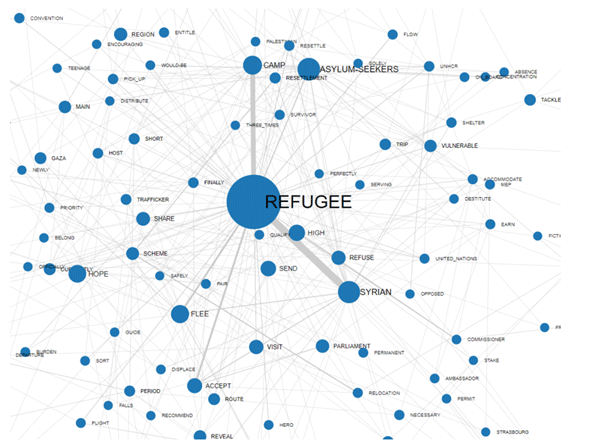
Selon le numéro de mots-clés, deux graphiques en
format HTML nous permettent de vérifier leurs relations soit à
l'intérieur du réseau entier qu'à l'intérieur du cluster auquel ils
appartiennent (voir ci-dessous).
|
NETWORK (FORCE-DIRECTED GRAPH)
|
|
|
NETWORK GRAPH (FORCE-DIRECTED GRAPH)
|
|
Trois autres tableaux nous fournissent d'autres
renseignements obtenus par l'analyse cluster.
En particulier:
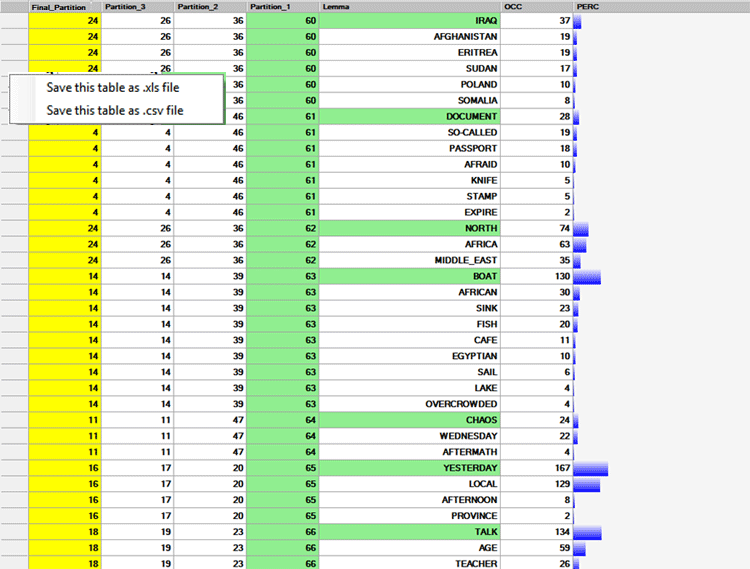
Le tableau TOUTES LES PARTITIONS permet de
vérifier comment les mots-clés ont été groupés dans chaque
partition de l' analyse des clusters (voir
ci-dessous).
N.B.: Pour réglage prédéfini, ce tableau est présenté ordonné sur
la première partition (c'est-à-dire celle avec le plus grand numéro
de clusters), et chaque passage d'un petit cluster à l'autre est
marqué en soulignant en vert le premier mot qui lui
appartient.
Le tableau PARTITIONS INTERMEDIAIRES nous
permet de vérifier comment les mots-clés ont été groupés dans la
partition sélectionnée.
Dans cet tableau, les caractéristiques de chaque groupe thématique
sont triées par leur valeurs d'occurrence (voir ci-dessous).
Le tableau CONTEXTES TYPIQUES nous permet de
contrôler les segments de texte qui ont le plus haut score
d'association avec les différents clusters de la meilleure
partition. Dans ce tableau le "score" se réfère à la ressemblance
(index cosinus) entre le vecteur des caractéristiques de chaque
cluster et le vecteur dans lequel chaque segment de texte est
représenté.
N.B. Le segment de texte plus significatif de chaque cluster est
marqué en jaune.

Comme en d'autres cas d'analyse thématique,
T-LAB permet
d'exporter le dictionnaire de la partition meilleure qui
peut être utilisé pour d'autres analyses.
C - QUELQUES DÉTAILS TECHNIQUES
Les types de séquences que cet outil
T-LAB nous permet
d'analyser sont les suivants:
1- Séquences de mots-clés, dont les éléments
sont des unités lexicales (c'est-à-dire mots ou lemmes) présentes
dans le corpus ou dans un de ses sous-ensembles. Dans ce cas, le
nombre maximum des 'nœuds' (à savoir les " types" d'unités
lexicales) est de 5.000;
N.B.: Lorsque la lemmatisation automatique est
appliquée, 5.000 unités lexicales correspondent à environ 12.000
mots.
2- Séquences de Thèmes, dont les éléments
sont des unités de contexte (c'est-à-dire des contextes
élémentaires) classifiées par un outil T-LAB pour
l'analyse thématique.
N.B.: Dans ce cas, étant donné que la séquence des
contextes élémentaires (phrases ou paragraphes) caractérise toute
la "chaîne" (prédécesseurs et successeurs) du corpus,
T-LAB produit une forme spécifique de l'analyse du discours, dans
laquelle les nœuds (c'est-à-dire les "thèmes") peuvent varier d'un
minimum de 5 à un maximum de 50.
3 - Séquences archivées dans un fichier
Sequence.dat, préparé par l'utilisateur (voir les explications
relatives à la fin de cette section). Dans ce cas le nombre maximum
de records est de 50.000 et le nombre de " types " (c'est-à-dire de
nœuds) ne doit pas dépasser 5.000.
Les informations suivantes sont fournies pour aider
l'utilisateur à mieux comprendre les données dans le tableau
SOMMAIRE.
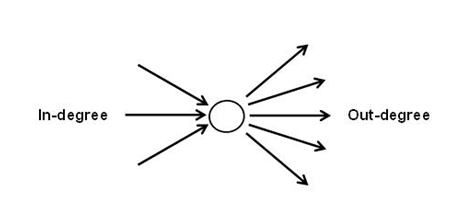
Selon la théorie des graphiques, les prédécesseurs
et les successeurs de chaque nœud (dans ce cas-ci, chaque
unité lexicale) peuvent être représentés au moyen de flèches (arcs)
en entrée (in-degree = types de prédécesseurs) ou en sortie
(out-degree = types de successeurs).
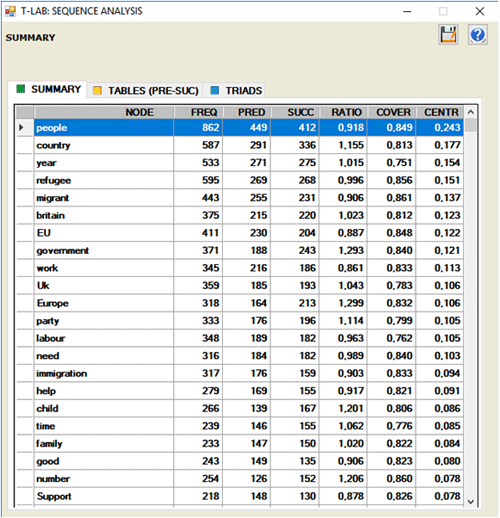
Par exemple, dans la table suivante "people" a 412
types de successeurs et 449 types de prédécesseurs.
Et son degré de centralité est 0.243.
Selon leur rapport (successeurs/prédécesseurs), il
est possible de vérifier la variété sémantique engendrée par chaque
noeud:
- si le rapport est plus grand que 1, le nœud est
définie "source;
- si le rapport est égal à 1, le nœud est défini "relais";
- si le rapport est inférieur à 1, le nœud est défini
"puits".
Dans le même tableau, pour chaque unité lexicale,
la colonne "cover" (couverture) indique le pourcentage de ses
occurrences précédées ou suivies des unités lexicales incluses dans
la liste de l'utilisateur.
Quand les unités analysées "couvrent" la totalité de
celles présentes dans le corpus, la valeur de "cover" est égale à
1; autrement, c'est une valeur inferieure. D'ailleurs: quand la
valeur de "cover" est égale à 1, également les totaux des
probabilités (des prédécesseurs et des successeurs) sont égales à
1; autrement, ils sont des valeurs inferieures. Dans les deux cas,
le pourcentage "résiduel" est déterminé par le fait qu'il y a des
prédécesseurs et des successeurs non inclus dans l'analyse.
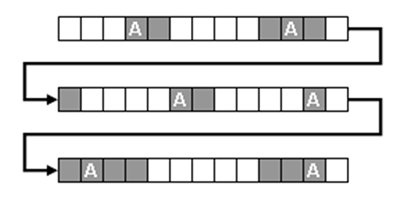
Par exemple, la séquence représentée dans l'image suivante
est constituée par 39 événements. De ces derniers, seulement 16
(les hypothétiques unités analysées) sont "couverts" (boîtes
grises); ceci parce que certains d'eux, par exemple ceux
correspondants aux occurrences de l'unité lexicale "A", ont des
prédécesseurs et des successeurs non inclus dans l'analyse (boîtes
blanches).
Différemment, quand l'utilisateur analyse séquences
de thèmes ou un fichier externe tout les événements sont
"couverts".
N.B.: Pour analyser un fichier externe,
l'utilisateur doit préparer le fichier " Sequence.dat "
correspondant; puis, après avoir ouvert un projet déjà existant, il
doit sélectionner l'option "Séquences enregistrées dans un fichier
Sequence.dat".
La méthode de calcul, les graphiques et les tables
sont analogues à ceux déjà décrites (voir ci-dessus).
Le fichier Sequence.dat, qui peut contenir chaque
genre d'étiquettes (par exemple les noms des parleurs dans une
conversation, des catégories obtenues par analyse du contenu, des
séquences d'événements, etc.), doit se composer par "N" lignes
(minimum 50 maximum 50.000), chacune avec une étiquette d'un
maximum de 50 caractères, sans signes de ponctuation ni espaces
vides.
Les types d'étiquettes doivent être maximum
5.000.
Voici quelques exemples de fichier Sequence.dat dans le format
correct:
|
Hamlet
King
Hamlet
Queen
Hamlet
Queen
Hamlet
King
Queen
Hamlet
King
Hamlet
Horatio
Hamlet
Horatio
... ... ...
|
activist
food
genetic
conservative
activist
genetic
conservative
activist
commerce
conservative
activist
conservative
biology
society
activist
... ... ...
|
event_01
event_03
event_02
event_03
event_03
event_01
event_05
event_02
event_05
event_01
event_02
event_04
event_03
event_01
event_01
... ... ...
|
Aussi bien après l'analyse des séquences (syntagmes) du
corpus qu'après l'analyse d'un fichier externe
(Sequence.dat), T-LAB produit des
tableaux dans le dossier MY-OUTPUT.
|