|
www.tlab.it
Classification (Cluster
Analysis)
 N.B.: Les images de cette section font référence à une
version précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre: a) il y a un nouveau bouton
(TREE MAP PREVIEW) qui permet à
l'utilisateur de créer plusieurs graphiques dynamiques au format
HTML; b) le bouton DENDROGRAMME a été remplacé par l'outil Graph Maker; c) une galerie d'images à accès
rapide qui fonctionne comme un menu supplémentaire permet de
basculer entre les différentes sorties en un seul clic (voir
l'image ci-dessous). N.B.: Les images de cette section font référence à une
version précédente de T-LAB. En
T-LAB 10, l'aspect est
légèrement différent. En outre: a) il y a un nouveau bouton
(TREE MAP PREVIEW) qui permet à
l'utilisateur de créer plusieurs graphiques dynamiques au format
HTML; b) le bouton DENDROGRAMME a été remplacé par l'outil Graph Maker; c) une galerie d'images à accès
rapide qui fonctionne comme un menu supplémentaire permet de
basculer entre les différentes sorties en un seul clic (voir
l'image ci-dessous).
Cette option met en marche un calcul qui emploie
les résultats d'une précédente Analyse des
Correspondances; en particulier, le calcul emploie les
coordonnées des objets (unités lexicales ou unités de contextes)
sur les premiers axes factoriels (pour un maximum de 10).
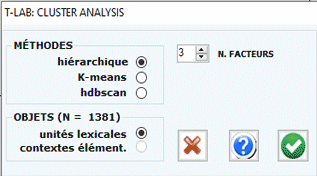
Selon les cas, l'utilisateur peut choisir entre
trois techniques de classification:
a) hiérarchique (méthode Ward);
b) K-means (méthode MacQueen);
c) hdbscan (hierarchical DBSCAN).
Les deux premières (a, b) permettent d'explorer (tableaux
et graphiques) des solutions de 3 à 20 cluster; alors que la
troisième (c), qui nécessite un paramètre supplémentaire
(c'est-à-dire le nombre minimum de mots dans un cluster), permet à
l'utilisateur d'explorer une seule solution.
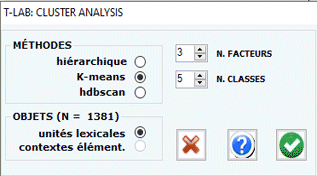
N.B.: Lorsque la méthode 'hiérarchique' est sélectionnée,
T-LAB rend disponible une
option (voir le bouton 'épurer' ci-dessous) qui permet à
l'utilisateur de combiner les méthodes de Ward et
K-Means.
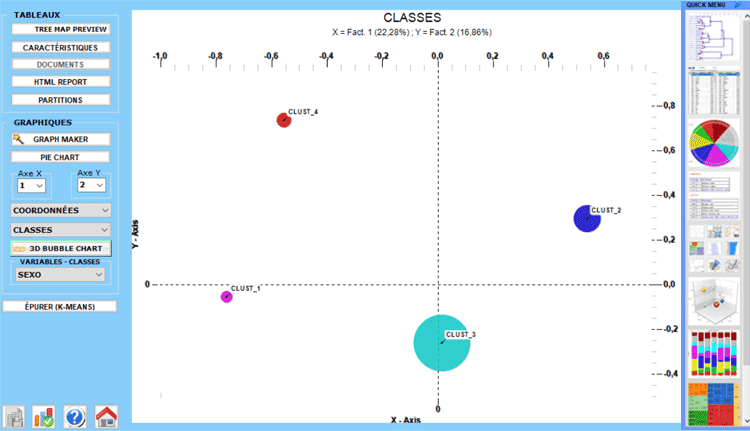
À la fin du traitement, T-LAB montre des graphiques et des
tableaux.
Les graphiques représentent les classes dans
l'espace détecté par la précédente Analyse des
Correspondances.
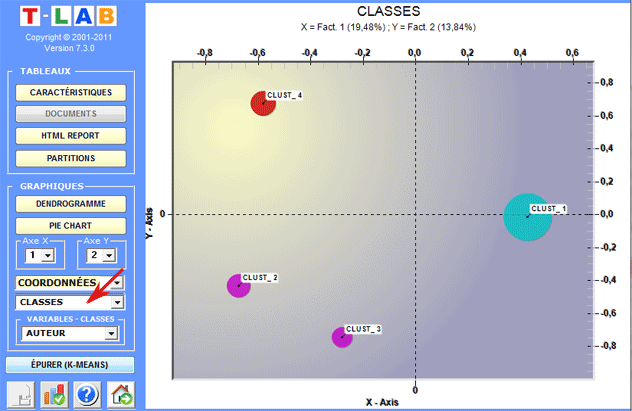
N.B.: Pour explorer les diverses combinaisons des
axes factoriels il suffit de les sélectionner dans les boîtes
appropriées ("Axe X", "Axe Y").
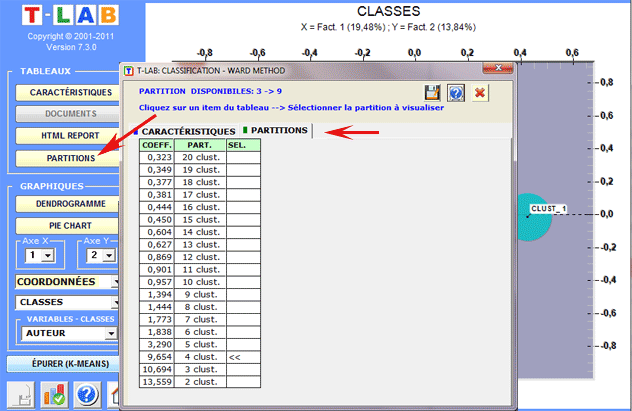
Dans le cas de classification hiérarchique,
l'utilisateur peut facilement explorer (graphiques et tableaux) les
partitions différentes.
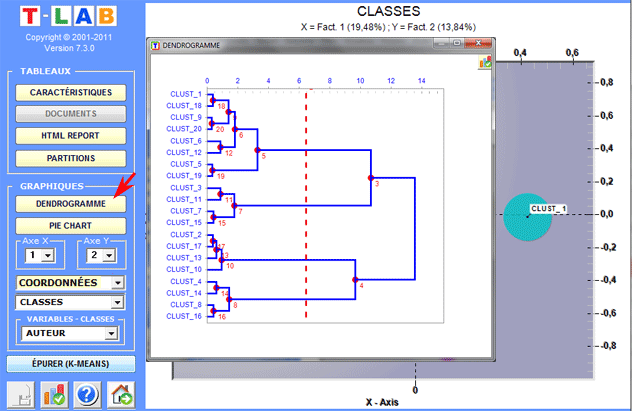
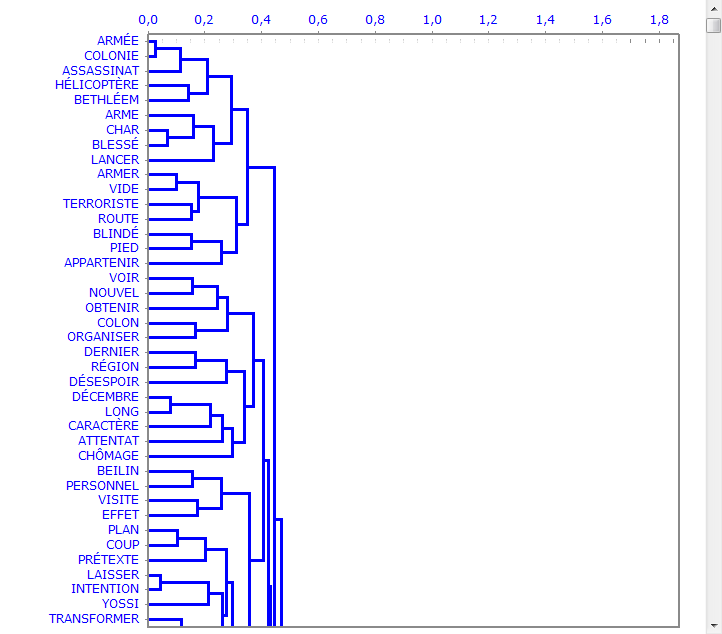
Dendrogrammes, graphiques circulaires (pie
charts) et histogrammes montrent les caractéristiques de chaque
partition.
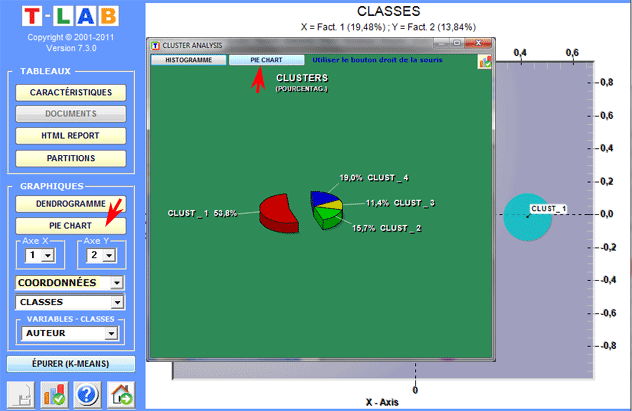
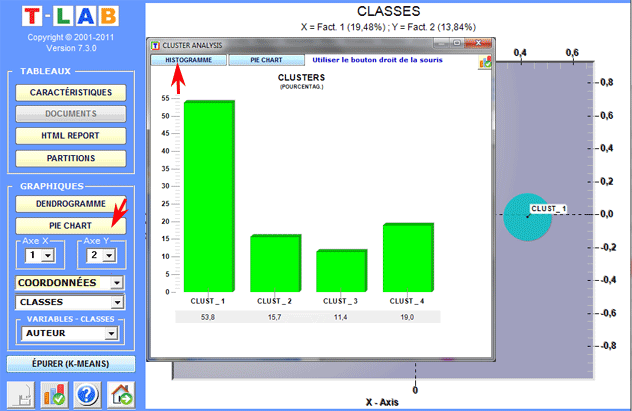
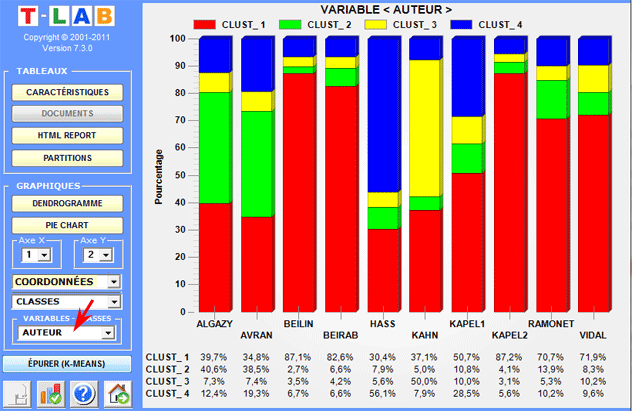
Des histogrammes nous permettent de vérifier les
rapports entre les classes et les variables.
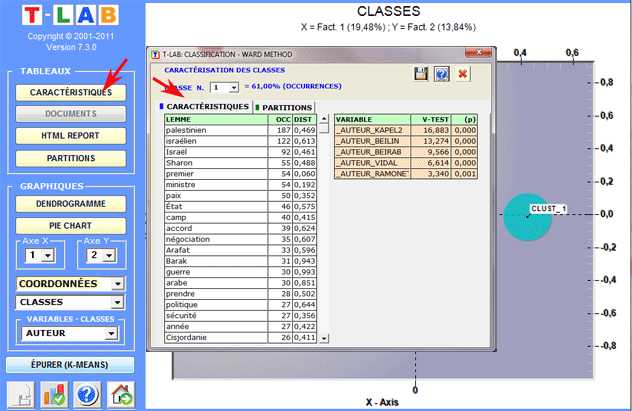
Les tableaux sont de deux types:
(A) si les objets classés
sont les unités lexicales, pour chacune d'elles (et
pour chaque classe) sont montrées les occurrences respectives
('OCC') et le distances ('DIST') au centroïde; aussi, pour chaque
variable qui est sensiblement associée à la classe examinée, est
montrée la Valeur Test.
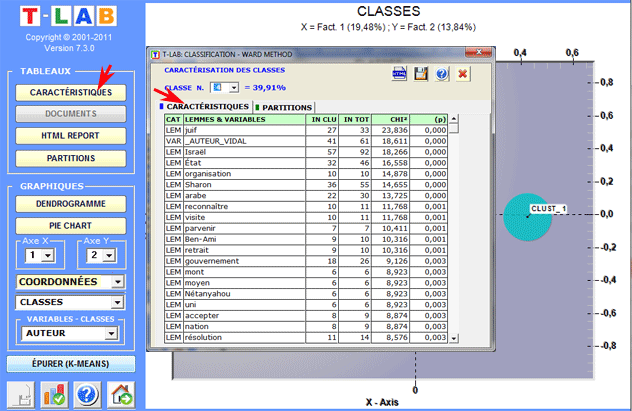
(B) si les
objets classés sont des contextes élémentaires, les
caractéristiques de chaque classe (unités
lexicales ou variables)
sont décrites au moyen de la même méthode employée dans Analyse Thématique des Contextes Élémentaires
(voir ci-dessous).
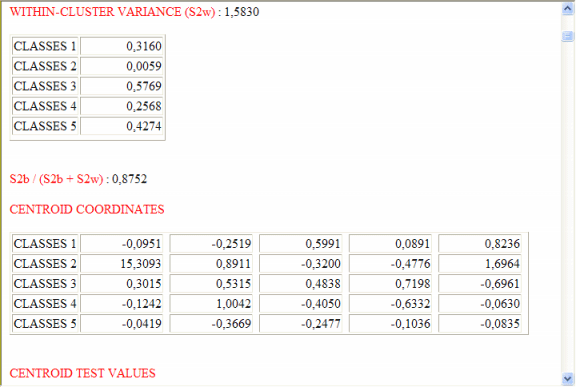
Dans le cas d'analyses réalisées avec des méthodes
hiérarchiques ou K-means T-LAB
permet de visualiser et exporter un fichier (voir bouton "Output
HTML") dans lequel les caractéristiques des clusters et certaines
mesures concernant la qualité de la partition du partage en examen
sont reportées.
|