|
www.tlab.it
Exportar Tablas
Personalizadas
 NOTA: Las imagenes contenidas en este apartado hacen
referencia a una versión anterior de T-LAB, ya que el interfaz de
T-LAB 10
cambia ligeramente. Sin embargo, las herramientas a disposición del
usuario siguen siendo las mismas. NOTA: Las imagenes contenidas en este apartado hacen
referencia a una versión anterior de T-LAB, ya que el interfaz de
T-LAB 10
cambia ligeramente. Sin embargo, las herramientas a disposición del
usuario siguen siendo las mismas.
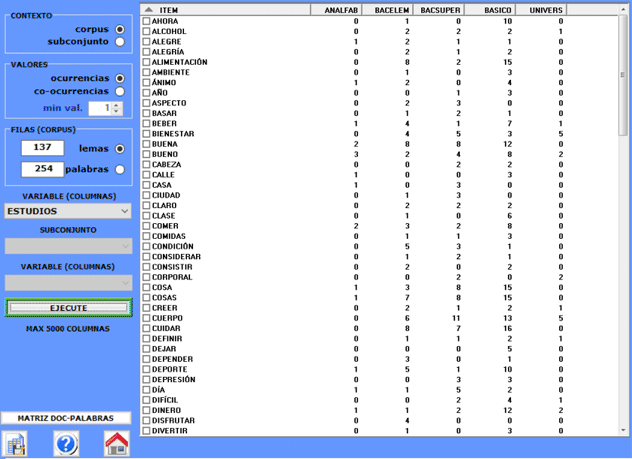
Esta opción nos permite permite crear, explorar y
exportar tres tipologías de tablas:
a) ellas con los valores de ocurrencias de las unidades lexicales dentro de
los subconjuntos del corpus definidos por medio de alguna variable
(matrices rectangulares);
b) ellas con los valores de las co-ocurrencias de las unidades lexicales (matrices
cuadradas) dentro del corpus o dentro de los subconjuntos;
c) ellas con las ocurrencias de las diferentes unidades lexicales
presentes en todos los documentos (matrices dispersas con los
índices de los diferentes elementos).
Los tamaños máximos de estas tablas son, respectivamente:
a) 10.000 líneas por 150 columnas; b) 5.000 líneas por 5.000
columnas; c) 30.000 documentos por 10.000 unidades
lexicales.
El uso de esta función es muy intuitivo.
En los casos más simples, el usuario debe seleccionar una
variable, cuya modalidades constituirán las columnas de la
tabla.
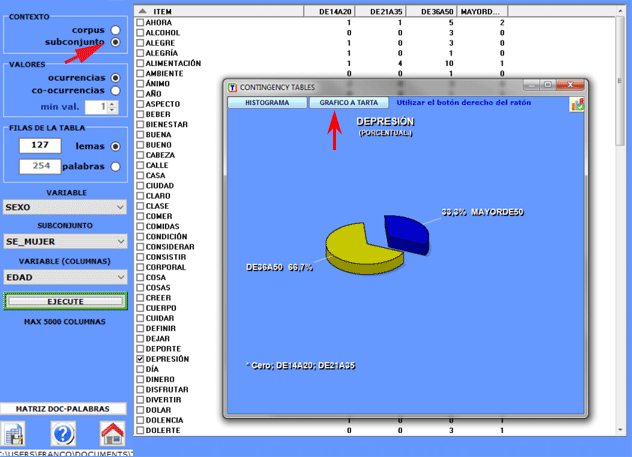
En los casos más complejos, se exige seleccionar una variable y
un subconjunto.
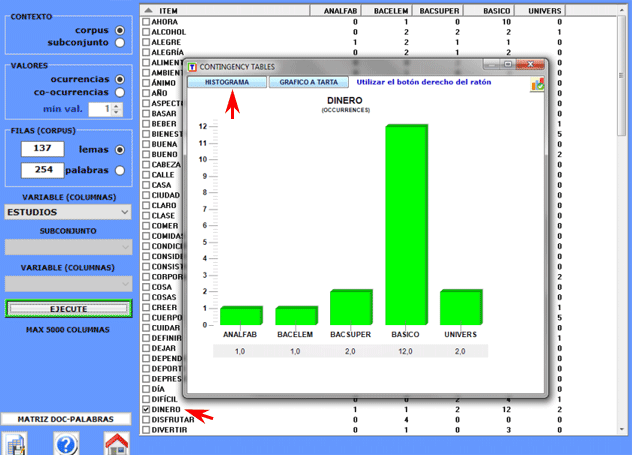
Todas las tablas nos permiten crear varios tipos de
gráficos.
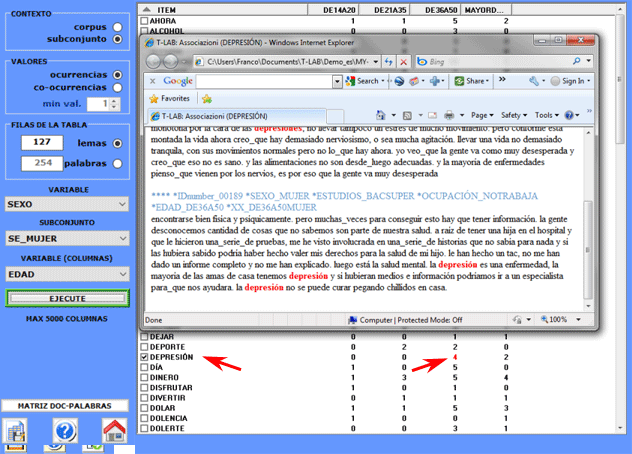
Además, haciendo clic en específicas células de una tabla, es
posible crear un archivo HTML que
incluye todos los contextos elementales en que la palabra en la
fila está presente en el subconjunto correspondiente (véase
abajo).
Para exportar matrices dispersas de la tipología de documentos
por palabras es suficiente cliquear en el botón correspondiente
('Matriz Documentos-Palabras').
En este caso, hay dos tipologías de output:
El primero (Sparse_Matrix.csv) tiene el siguiente formato:
Doc_Index; Word_Index; Word_Occ
00001; 1; 12
00001; 2; 5
…..
El segundo (Word_Indexes.csv) tiene el siguiente formato:
Word_Index; Word_Label
1; abrir
2; acabar
….
.
|


