|
www.tlab.it
Importar un único archivo
...
En el caso de un único texto (o corpus considerado
como único texto), T-LAB no necesita nada más: es
suficiente seleccionar la opción 'Importar un único archivo' (vease
abajo).
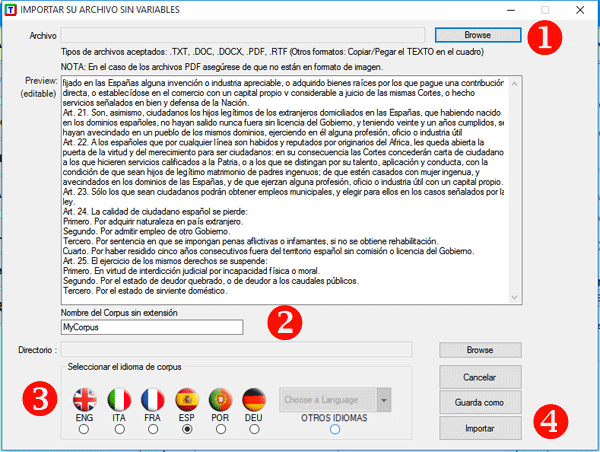
Entonces se requieren cuatro pasos (ver la imagen
siguiente) : (1) seleccionar cualquier archivo; (2) elegir el
nombre del proyecto; (3) seleccionar el idioma de su texto; (4)
hacer clic en "Importar" .
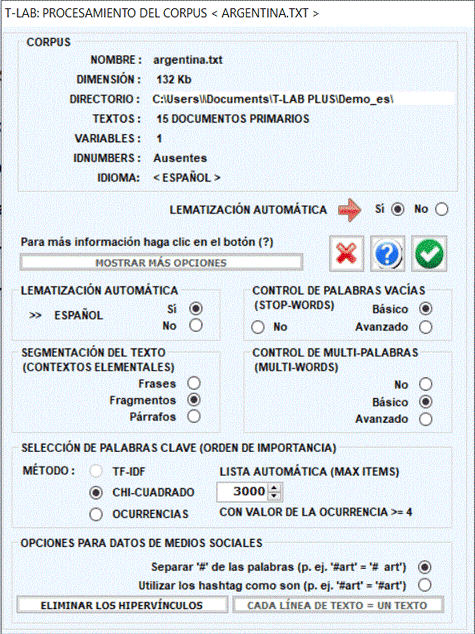
Sucesivamente
aparece una ventana (véase abajo) en la cual el usuario puede
elegir algunos tratamientos.
NOTA:
- Porque
las diferentes opciones determinan el tipo y la cantidad de
unidades de análisis (es decir las unidades de contexto y las
unidades lexicales), diversas opciones determinan diversos
resultados del análisis (véase abajo las opciones avanzadas). Por
esta razón, todos los outputs de T-LAB (es decir gráficos y
tablas) utilizados en el manual del usuario y en la ayuda en red
son solo indicativos;
- Todas las etapas de pre-procesamiento se realizan al importar
cualquier tipo de corpus.
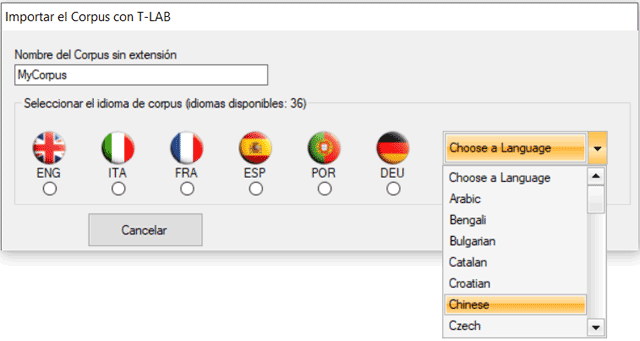
1 - LEMATIZACIÓN AUTOMÁTICA O STEMMING
A continuación, se presenta el listado completo de los 30
idiomas para los cuales T-LAB prevé la posibilidad de
implementar procesos de lematización automática y de stemming.
LEMATIZACIÓN: alemán, catalán, croata,
eslovaco, español, francés, inglés, italiano, latín, polaco,
portugués, rumano, ruso, serbo, sueco y ucraniano.
STEMMING: árabe, bengalí, búlgaro,
checo, danés, finlandés, griego, hindi, húngaro, indonesio,
marathi, noruego, persa y turco.
En cualquier caso, sin lematización automática y / o
mediante diccionarios personalizados, el usuario puede analizar
textos en todos los idiomas. Lo
importante es que las palabras estén separadas por espacios y/o
signos de puntuación.
El
resultado del proceso del lematización se puede verificar por medio
de la función Vocabulario y se puede
modificar por medio de la función Personalización del Diccionario.
2 - SEGMENTACIÓN DE TEXTOS (CONTEXTOS ELEMENTALES)
Según la elección del usuario, los contextos elementales
para el cómputo de co-ocurrencias pueden
ser: frases, fragmentos de longitud comparable, párrafos o textos
breves (por ejemplo, respuestas a las preguntas abiertas).
El fichero corpus_segments.dat contiene el resultado de
la segmentación del corpus.
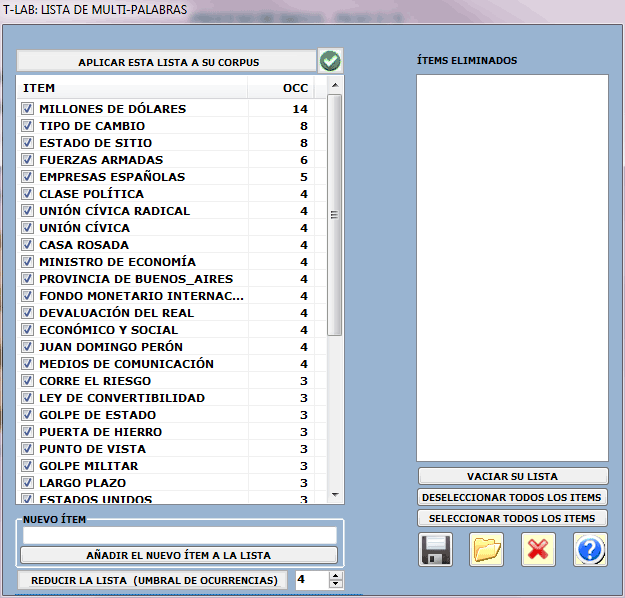
3 - CONTROL DE MULTI-PALABRAS
La opción "Básico" activa el uso automático de
la lista multi-palabras de T-LAB.
Diferentemente la opción "Avanzado", disponible solamente
con la lematización automática, permite las operaciones
siguientes:
- verificar y modificar la lista de multi-palabras no incluidas en
base de datos de T-LAB;
- importar y utilizar listas personalizadas
de multi-palabras (archivos Multiwords.txt).
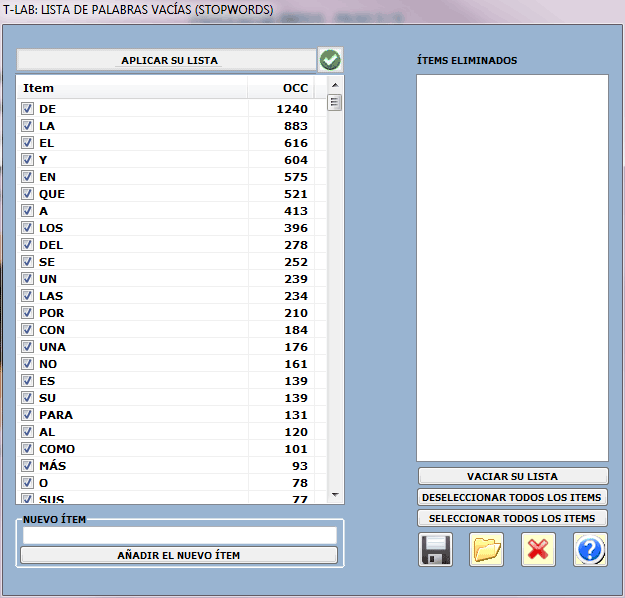
4 - CONTROL DE PALABRAS VACÍAS
La opción "Básico" activa el uso automático de la lista
palabras vacías de T-LAB.
Diferentemente la opción "Avanzado" permite las
operaciones siguientes:
- verificar y modificar la lista de palabras vacías presentes en el
corpus;
- importar y utilizar listas personalizadas
de palabras vacías (archivos StopWords.txt).
5 - SELECCIÓN DE PALABRAS CLAVE
Las opciones disponibles permiten que elijamos el método
de la selección (TF-IDF o Chi-cuadrado) y la cantidad máxima de unidades
lexicales que se incluirán en una lista usada por T-LAB para analizar los textos
con la configuración automática.
NOTA: Al término de la
fase de importación, utilizando la configuración personalizada, el usuario puede
revisar la selección de palabras clave y crear varias listas para
ser aplicadas.
|


