|
www.tlab.it
Análisis de Secuencias y
Análisis de Red
Esta herramienta de T-LAB tiene en
cuenta las posiciones de las diferentes unidades lexicales dentro
de las frases, permitiendonos así analizar y representar cualquier
texto como si fuera una red de
relaciones.
Las opciones a dispición del usuario permiten
implementar analisis de Co-Word, analisis tematicos y
desambiguaciones.
De hecho, una vez construidas las dos matrices que
incluyen todas las parejas de predecesores y sucesores,
T-LAB calcula las probabilidades de transición (cadenas de markov) y
proporciona diferentes output relacionados con las palabras objeto
de estudio.
Además, es posible realizar un analisis de
clústeres. Como consecuencia, se podrán explorar las
relaciones semanticas que existen entre palabras tanto dentro de la
red entera como dentro de de los "clústeres temáticos" (N.B.: en
este caso, el algoritmo usado para la clusterización coincide con
el 'Louvain method' desarrollado por Blondel V.D., Guillame J.-L ,
Lambiotte R., Lefebre E., 2008).
Por tanto, una vez implementado este tipo de
analisis, el usuario podrá explorar las relaciones que existen
entre nodos de la red (esto es, las palabras clave) a diferentes
niveles: a) dentro de las relaciones del tipo uno-a-uno; b) dentro
de un "ego network"; c) dentro de las comunidades a las que
pertenecen; d) dentro de la red formada por el texto
analizado.
|
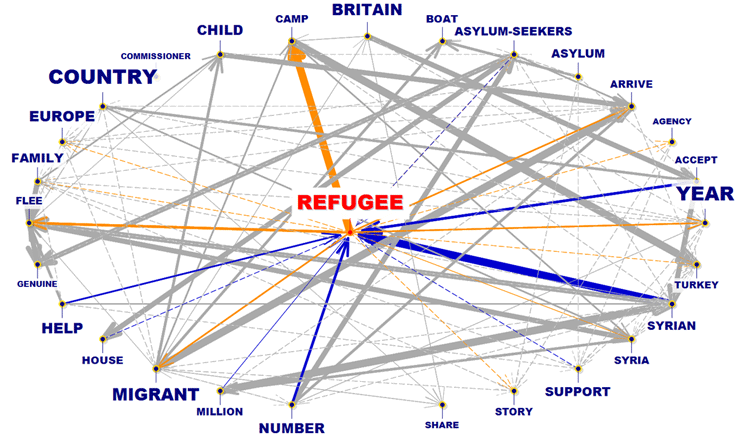
RELACIONES DEL TIPO UNO-AD-UNO
|
EGO-NETWORK
|
|

|
|
COMUNIDADES
|
RED ENTERA
|

|
|
Las informaciones necesarias para utilizar las
diferente opciones de analisis están organizadas en tres secciones
:
A - Explorar las conexiones del tipo uno-a-uno y
las "ego networks;
B - Explorar las "comunidades" (clústeres temáticos) y la red
entera;
C - Algunos detalles técnicos.
N.B.: Por razones de carácter editorial, esta
página incluye ejemplos de analisis basados en un corpus escrito en
lengua inglesa.
A - EXPLORAR LAS CONEXIONES DEL TIPO UNO-A-UNO Y
LAS "EGO NETWORKS"
Una vez acabado el análisis automático, se
dispondrá de diferentes tablas y gráficos que permitirán explorar
las relaciones y los datos asociados a las palabras clave
seleccionadas (N.B.: Para obtenerlos basta con hacer clic sobre uno
de los ítems incluidos en las tablas o en cualquiera de los puntos
que componen los gráficos).
Usando el botón derecho del ratón, será posible
personalizar cualquier tipo de gráfico y exportarlo a diferentes
formatos.
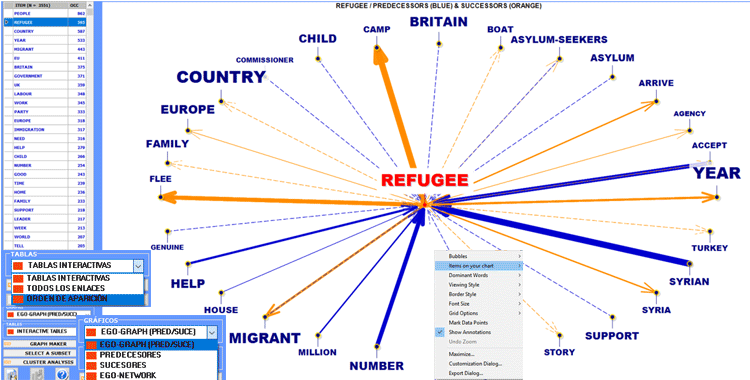
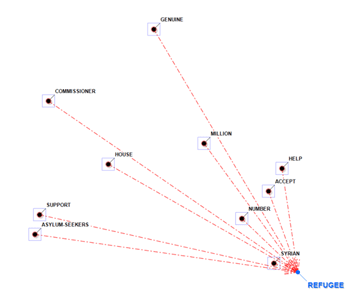
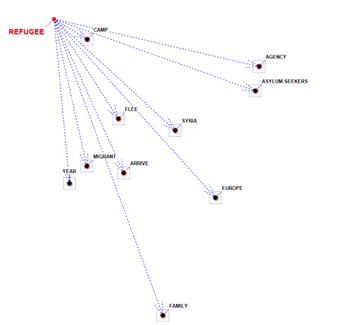
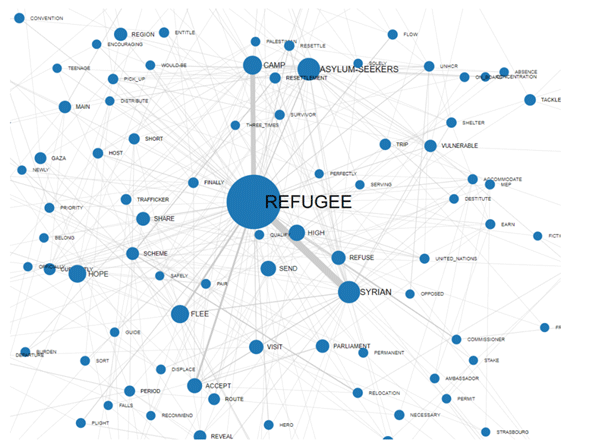
En dos de los gráficos los elementos más cercanos a
los seleccionados son aquellos que mayor probabilidad tienen de
estar delante (predecesores) o detrás (sucesores) de los
mismos.
|
PREDECESORES
|
SUCCESORES
|
|
|
En los demás casos, la cercanía entre
palabras-clave viene representada graficamente mediante el grosor
de las flechas que las conectan.
Es posible comprobar todos los datos utilizando las
diferentes tipologías de tablas.
Más en detalle:
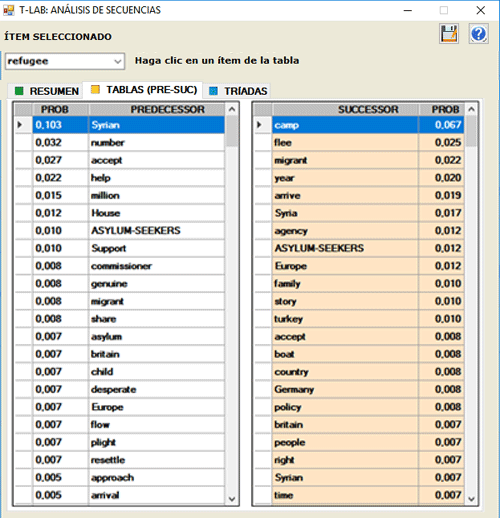
Las TABLAS INTERACTIVAS muestran los
listados de predecesores y sucesores vinculados a las palabras
clave seleccionadas.
La lista está en una orden descendente según los
valores de probabilidad ("PROB"). Por ejemplo, en la tabla
siguiente, la probabilidad de que "camp" siga "refugee" es igual a
0.067, que es 6.7%.
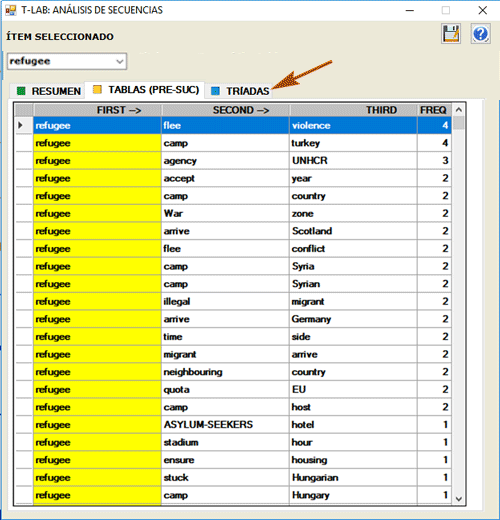
La opción TRÍADAS nos permite visualizar
algunas tablas con secuencias de tres elementos en las cuales la
palabra seleccionada está en la primera, en la segunda o en la
tercera posición. Para cada tríada T-LAB muestra los
correspondientes valores de ocurrencia.
(N.B.: Dentro de las tríadas las palabras
vacías no son incluidas).
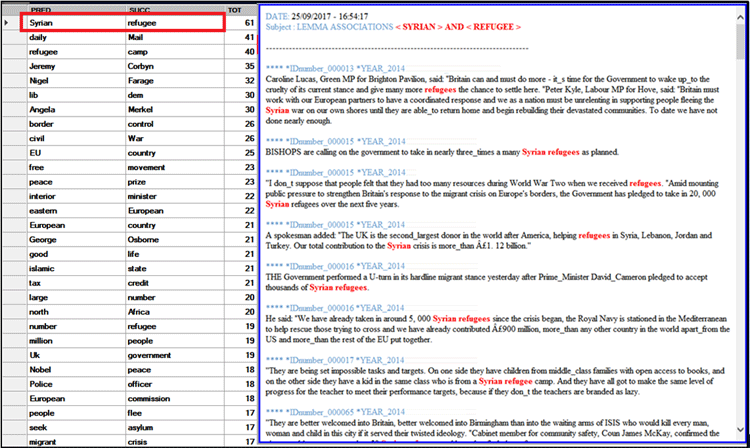
La tabla TODOS LOS ENLACES (véase abajo) es
particularmente util para desambiguar los significados de las
palabras, y contiene todas las parejas de predecesores y sucesores
junto con las ocurrencias a ellas correspondientes.
Cliqueando en una de la líneas de esta tabla, será posible
visualizar, en el lado derecho de la misma y en formato HTLM, todos
los segmentos de texto (esto es, los contextos elementales) en los
cuales aparecen conjuntamente dos elementos de una misma pareja
(esto es, las co-ocurrencias).
La tabla RANGO DE APARICIÓN incluye la
frecuencia y el orden medio de aparición (o evocación) de cada
palabra dentro de un segmento de texto. Sólo es posible ver esta
tabla cuando el corpus está compuesto por textos cortos, como por
ejemplo respuestas a preguntas abiertas.
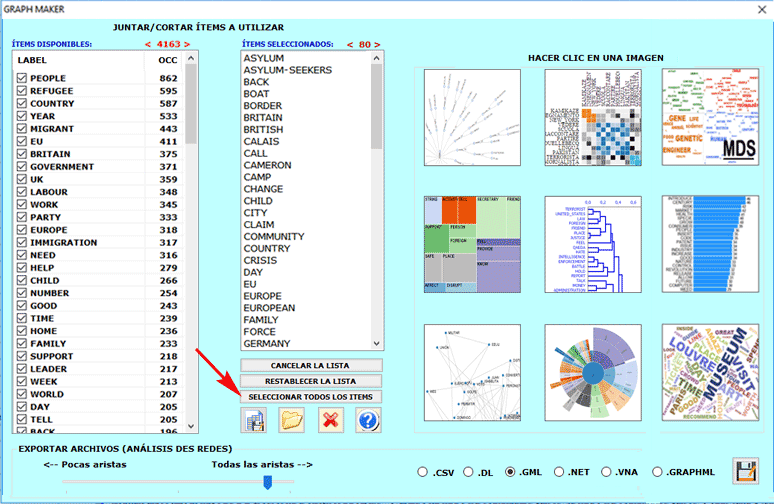
Cliqueando en la opción GRAPH
MAKER el usuario podrá crear, en todo momento y a partir de los
listados personalizados de palabras clave, diferentes tipos de
graficos (véase abajo). Los usuarios avanzados que estén
interesados en exportar archivos a formatos diferentes (p.e. .dl
.gml .vna .graphml) junto con los datos relativos a todos los
enlaces, pueden hacer click en el botón 'SELECCIONAR TODOS LOS
ITEMS'.
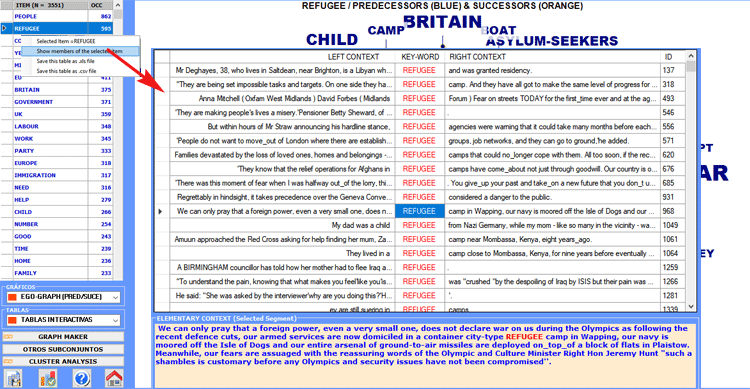
En todo momento, cliqueando con el botón derecho
del ratón sobre las tablas que incluyen las palabras clave, es
posible verificar los contextos de ocurrencia de los diferentes
ítems (véase abajo).
B -
EXPLORAR LAS COMUNIDADES (CLÚSTERES TEMÁTICOS) Y LA RED
ENTERA
Una vez realizado un análisis de clústeres, se
vuelven disponibles nuevos gráficos y tablas.
Todos ellos están indicados por pequeños rectángulos azules (véase
abajo).

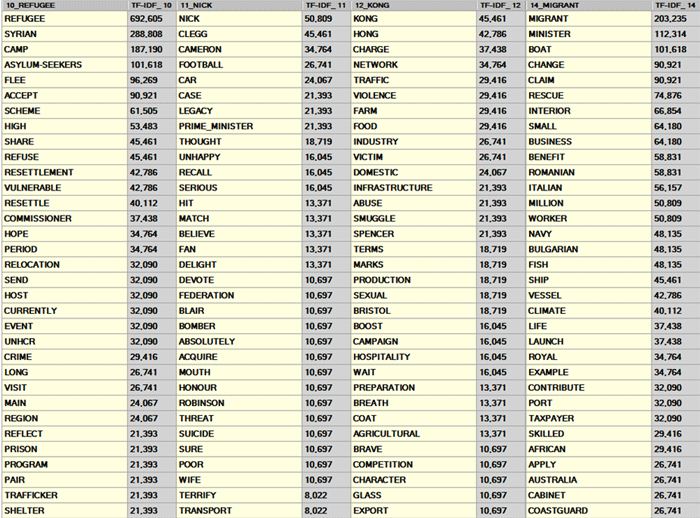
La primera tabla resume las mejores características
(palabras clave) de la PARTICIÓN FINAL obtenida a partir del
algoritmo de clusterización.
En dicha tabla se encuentran ordenadas en base a su valor TF-IDF
(véase abajo) las características de cada clúster.
N.B.: Cuando un clúster de la partición final incluye
solo dos palabras, usualmente eso significa que un caso de
multiword no se ha resuelto durante la fase de preprocesamiento de
datos.
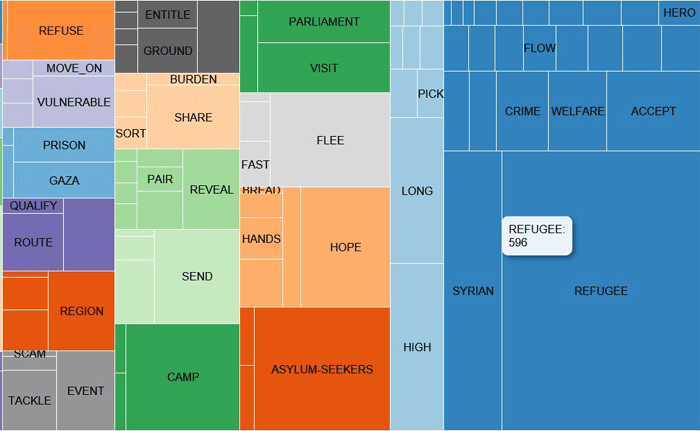
Haciendo clic en cualquier palabra de la tabla
anterior (así como de la tabla PARTICIONES DISPONIBLES), un
TreeMap nos permite verificar las comunidades a las que pertenece
(ver abajo).
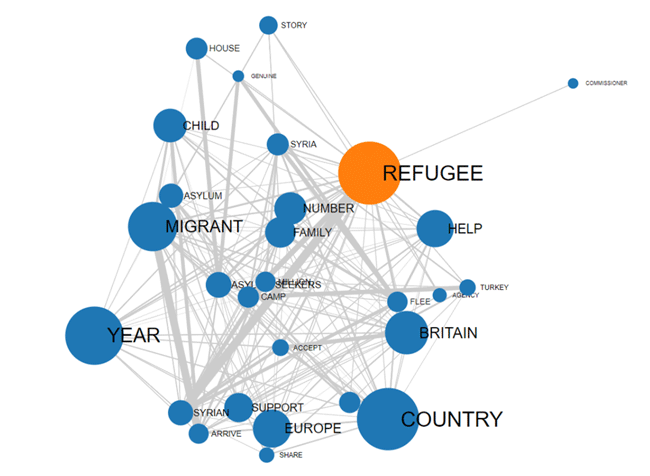
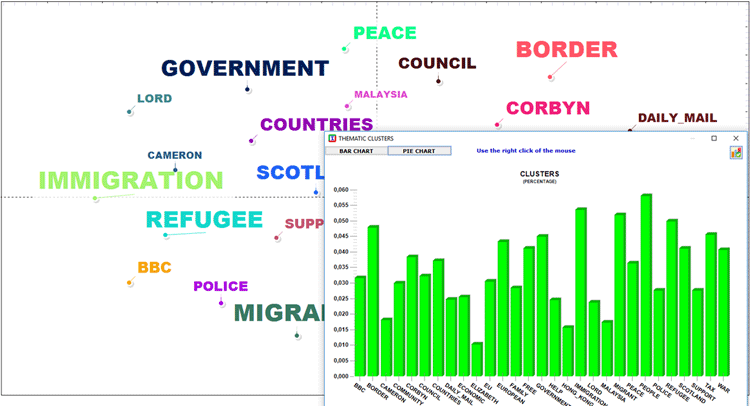
El MAPA MDS y el gráfico PORCENTAJES
(véase abajo) permiten comprobar el 'peso' de cada clúster, así
como las relaciones entre diferentes clústeres dentro de la
partición final encontrada (véase abajo).
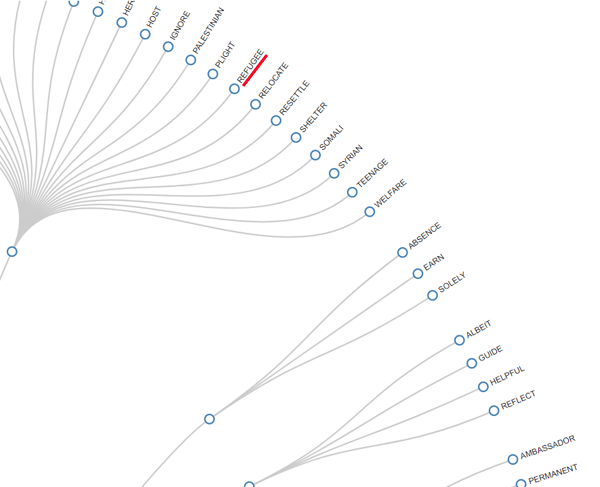
En función del número de palabras clave, será
posible explorar las relaciones entre ellas, utilizando dos
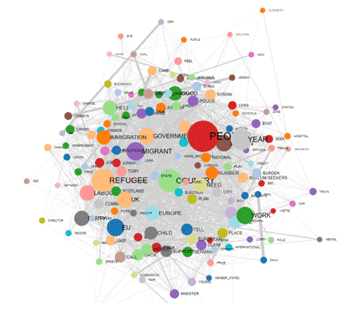
gráficos en formato HTLM. Todo ello, tanto dentro de la entera red
como dentro de los clústeres a los que pertenecen las palabras
clave (véase abajo).
|
DENDROGRAMA RADIAL
|
|
|
NETWORK GRAPH (FORCE-DIRECTED GRAPH)
|
|
Tres nuevas tablas proporcionarán ulterior
información obtenida a partir de los análisis de clústeres.
En concreto:
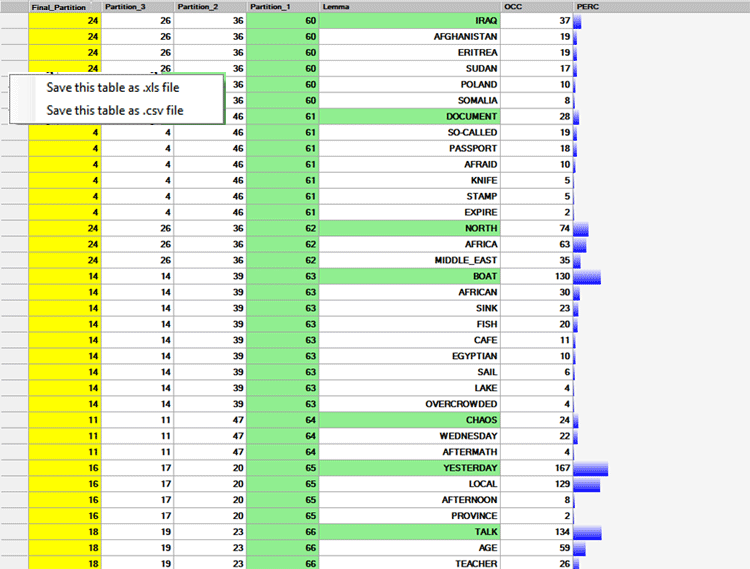
La tabla TODAS LAS PARTICIONES permitirá
comprobar como las palabras claves estén agrupadas a partir de cada
una de las particiones del analisis de clústeres (véase abajo. Los
números incluidos en las columnas de las particiones hacen
referencia a los diferentes clústeres).
N.B.: Por defecto, esta tabla viene ordenada en base a la primera
partición, que presenta el numero más alto de clústeres. Cada
movimiento de un clúster pequeño hacia otro viene puesto de releve
marcando en color verde la primera palabra que lo
compone.
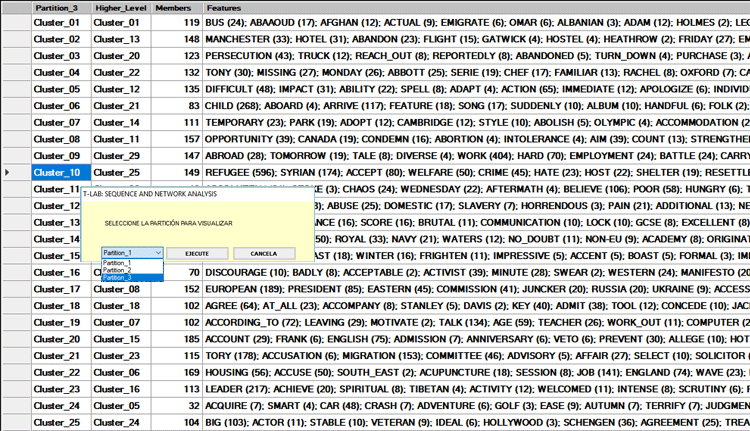
La tabla PARTICIONES INTERMEDIAS permitirá
explorar de qué manera hayan sido agrupadas las palabras claves
dentro de cada una de las particiones seleccionadas. Paso a paso,
éstas vendrán ordenadas de forma descendente en base a los valores
de sus co-ocurrencias (véase abajo).
La tabla CONTEXTOS TÍPICOS permite explorar
los segmentos de texto que mayor puntuación de asociación presentan
en relación con los clústeres de la partición final. En esta tabla
se utiliza el índice de coseno para medir la semejanza entre el
vector de las características de cada clúster y el vector que
contiene los segmentos de texto.
N.B. Viene marcado en color amarillo el segmento de texto más
significativo de cada clúster.

Así como ocurre para otros tipos de análisis
temático, T-LAB permite exportar el diccionario
de la partición final. De este modo, su uso estará disponible para
ulteriores análisis.
C - ALGUNOS DETALLES TÉCNICOS
Esta herramienta de T-LAB puede
ser implementada a partir de las siguientes tipologías de
secuencias:
1- Secuencias de palabras-clave, cuyos
elementos son unidades lexicales (es decir, palabras o lemas)
presentes en el corpus o un subconjunto del corpus mismo. En este
caso, el número máximo de 'nudos' (es decir, los 'tipos' de
unidades lexicales) es 5.000;
N.B.: Quando se aplica la lematización automática,
5.000 unidades léxicales corresponden a cerca de 12.000
palabras.
2- Secuencias de Temas, cuyos elementos son
las unidades de contexto (es decir, contextos elementales)
clasificadas por una de las herramienta de T-LAB para el
análisis temático.
N.B.: En este caso, ya que la secuencia de los
contextos elementales (frases o párrafos) caracteriza la 'cadena'
entera del corpus (predecesores y sucesores), T-LAB implementa una
forma concreta de Análisis del Discurso, cuyos nudos (es
decir los 'temas') varían de un mínimo de 5 a un máximo de
50.
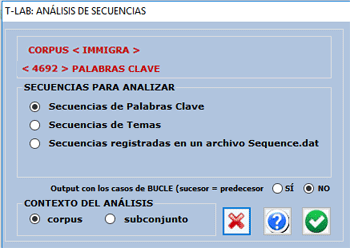
3 - Secuencias registradas en un archivo
Sequence.dat predispuesto por el usuario (véanse las
explicaciones pertinentes al final de esta sección). En este caso,
el número máximo de records es 50.000 y el numero de 'tipos' (es
decir, los nudos) no debe superar los 5.000.
Las informaciones que siguen vienen proporcionadas
para que el usuario comprenda mejor los datos incluidos en la tabla
RESUMEN.
Según la teoría de gráficos, los predecesores y los
sucesores de cada nodo (en este caso, unidad lexical) pueden ser
representados por medio de flechas (arcos) entrantes (in-degree =
los tipos de predecesores) y salientes (out-degree = los tipos de
sucesores).
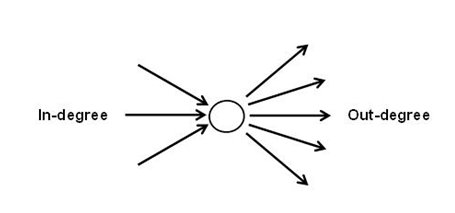
Por ejemplo, en la tabla siguiente "people" tiene
412 tipos de sucesores y 449 tipos de predecesores.
Y el centrality degree es igual a 0.243.
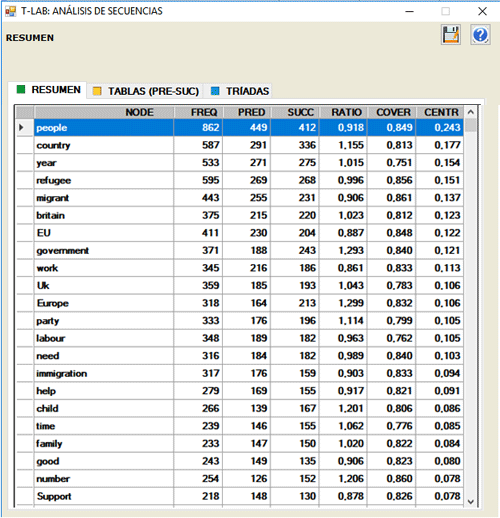
Según el cociente (sucesores/predecesores), es
posible verificar la variedad semántica engendrada por cada
nodo:
- si el cociente es mayor de 1, el nodo es definido
"fuente";
- si el cociente es igual a 1, el nodo es definido "relais"
- si el cociente es más bajo de 1, el nodo es definido
"pozo".
En la misma tabla, para cada unidad lexical, la
columna "cover" (cobertura) indica el porcentaje de sus ocurrencias
precedidas o seguidas por las unidades lexicales incluidas en la
lista del usuario.
Cuando las unidades analizadas "cubren" la totalidad de
los presentes dentro del corpus, el valor de "cover" es igual a 1;
si no, es un valor inferior. Por otra parte: cuando el valor de
"cover" es igual a 1, también las adiciones de los valores de
probabilidad (de predecesores y de sucesores) son iguales a 1; si
no, son valores inferiores. En ambos casos, el porcentaje
"residual" es determinado por el hecho de que hay predecesores y
sucesores no incluidos en el análisis.
Por ejemplo, la secuencia representada en la imagen
siguiente es constituida por 39 acontecimientos: de éstos,
solamente 16 (las hipotéticas unidades en análisis) "se cubren"
(las cajas grises). Es porque algunos de ellos (véase aquéllos
correspondientes a las ocurrencias de la unidad "A") tienen
predecesores y sucesores no incluidos en el análisis (cajas
blancas).
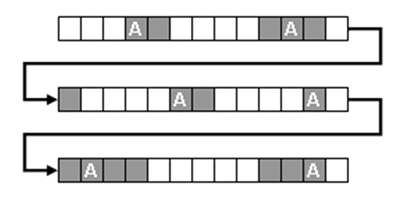
Diferentemente, cuando el usuario analiza
Secuencias de Temas o un archivo externo todos los acontecimientos
"se cubren".
N.B.: Para analizar un fichero externo es necesario
preparar el fichero 'Sequence.dat' correspondiente. Sucesivamente,
y una vez abierto un proyecto ya existente, el usuario debe escoger
la opción "Secuencias registradas en un archivo
Sequence.dat".
El método del cálculo, los gráficos y las tablas
son análogos a ésos ya descritos (véase arriba).
El archivo de Sequence.dat, que puede contener cada
clase de etiquetas (e.g. los nombres en una conversación, las
categorías obtenidas por análisis del contenido, las clases de
acontecimientos,etc.), se debe componer por "N" líneas (mínimo 50
máximo 10.000), cada una con una etiqueta de máximo 50 caracteres,
sin signos de puntuación o espacios en blanco.
Los tipos de etiquetas deben ser máximo 5.000.
He aquí algunos ejemplos de Sequence.dat en el formato
correcto:
|
Hamlet
King
Hamlet
Queen
Hamlet
Queen
Hamlet
King
Queen
Hamlet
King
Hamlet
Horatio
Hamlet
Horatio
... ... ...
|
activist
food
genetic
conservative
activist
genetic
conservative
activist
commerce
conservative
activist
conservative
biology
society
activist
... ... ...
|
event_01
event_03
event_02
event_03
event_03
event_01
event_05
event_02
event_05
event_01
event_02
event_04
event_03
event_01
event_01
... ... ...
|
Tanto en el caso de secuencias de unidades lexicales
(corpus analizado) como en el de secuencias incluidas en un archivo
externo (Sequence.dat), T-LAB produce algunas tablas en la
carpeta MY-OUTPUT.
|