|
www.tlab.it
TF-IDF
Esta medida, propuesta por G. Salton (1989),
permite comprobar el peso de un termino (unidad lexical) en un
documento (unidad de contexto).
Su fórmula es la siguiente:
w i,j =
tf i,j x idf i (Term Frequency x Inverse
Document Frequency)
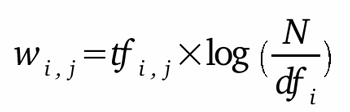
En la que:
tf i,j = número
de ocurrencias del termino i en
el documento j
df i = número de documentos que
contienen i
N = número de documentos en una
colección (corpus)
El valor tf i,j
(Frecuencia del Termino) puede ser normalizada en la manera
siguiente:
tf i,j =
tf i,j / Max (f i,j )
en la que Max (f
i,j ) es la frecuencia máxima de un cualquier termino
i en el documento
j .
|


