|
www.tlab.it
Descomposición de Valores
Singulares (SVD)
La Descomposición de Valores Singulares (SVD -
Singular Value Decomposition - véase Wikipedia https://en.wikipedia.org/wiki/Singular-value_decomposition)
es una técnica de reducción de dimensiones que, en minería de
textos, puede utilizarse para descubrir las dimensiones
latentes (o componentes) que determinan similitudes
semánticas entre las palabras (es decir, unidades léxicas) o
entre los documentos (es decir, unidades de contexto ).
T-LAB nos permite
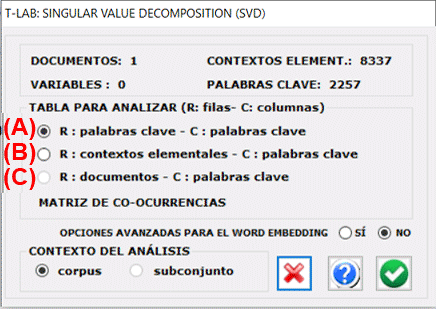
realizar un SVD de tres tipos de tablas de datos. En el
primer caso (ver 'A' a continuación), la tabla de datos es una
matriz de co-ocurrencias con - en filas y en columnas - las
palabras clave seleccionadas. En el segundo caso (ver 'B' a
continuación), la tabla de datos contextos elementales X palabras
clave contendrá valores de presencia / ausencia (es decir, '1' y
'0'). En el tercer caso (ver 'C' a continuación) la tabla de datos
documentos X palabras clave contendrá valores de
ocurrencia.
NOTA: Tenga en cuenta que, al analizar la matriz de co-ocurrencias
cuyas filas y columnas son términos clave (ver 'A' a continuación),
T-LAB proporciona vectores
densos de alta calidad (es decir, word embeddings).
El procedimiento de análisis consta de los siguientes
pasos:
1 - construcción de la tabla de datos a analizar (hasta 300,000
filas x 5,000 columnas);
2 - normalización TF-IDF y escalado de vectores de fila a longitud
de unidad (norma euclidiana);
3 - extracción de las primeras 20 'dimensiones latentes' a través
del algoritmo Lanczos.
NOTA:
- En el caso de las matrices de co-ocurrencia (ver "A" arriba), la
normalización de los datos se obtiene usando la medida del
coseno;
- Cuando se seleccionan las opciones avanzadas para el word
embedding, T-LAB calcula los
valores de PPMI (Positive Pointwise Mutual Information) y hace
posible utilizar las primeras 50 dimensiones de la SVD;
Los resultados del análisis se muestran en tablas
y gráficos.
En detalle:
Dos tablas, cuyas filas pueden ser unidades léxicas o
unidades de contexto, tienen tantas columnas como las dimensiones
extraídas.
En el caso de la tabla LEMAS (es decir, unidades
léxicales), se muestra una columna más, en la que se informan los
puntajes de importancia (ver a continuación).
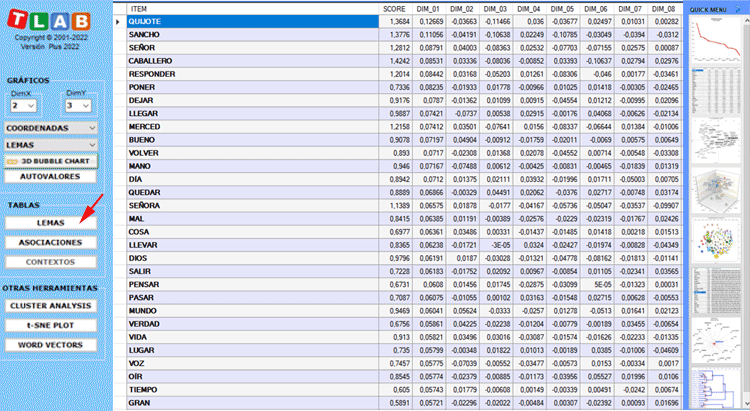
NOTA: La puntuación (es decir el 'score') de
importancia de cada lema se calcula sumando los valores
absolutos de sus primeras 20 coordenadas (es decir, los vectores
propios), cada uno multiplicado por lo valor propio
correspondiente.
Cualquier tabla se puede ordenar en orden
ascendente o descendente haciendo clic en cualquier encabezado de
columna..
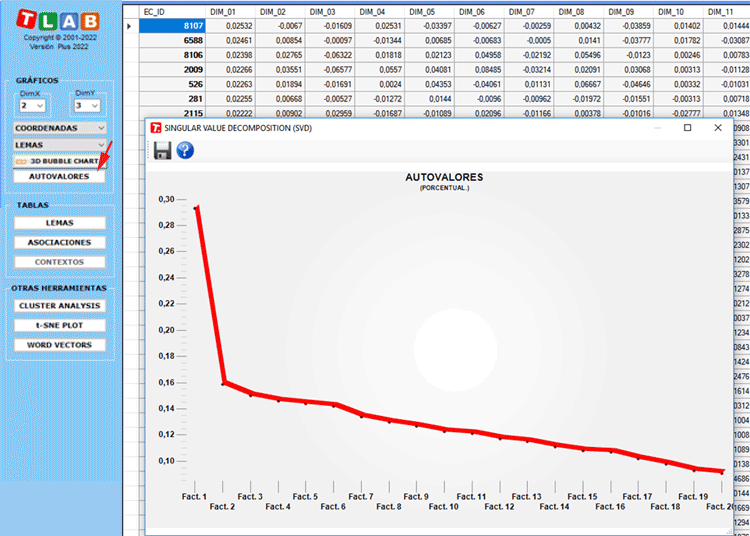
Para exportar cualquier tabla, solo use el botón derecho del
mouse cuando se muestren los datos.Tenga en
cuenta que, la primera vez que se exporta una tabla de este tipo,
los valores propios también se exportan. De esta forma, el usuario
puede evaluar el peso relativo de cada dimensión, es decir el
porcentaje de varianza explicado por cada una de ellas.
Al hacer clic en el botón Asociaciones (véase a
continuación), se muestra una tabla adicional con las medidas de
similitud (es decir, el coseno) de cada palabra clave. Además,
cuando se hace clic en cualquier fila de dicha tabla, se muestra un
gráfico con los datos correspondientes.
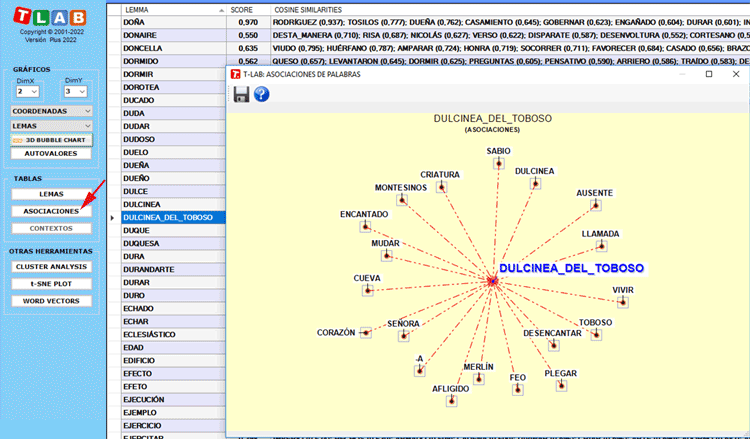
Los gráficos principales muestran las relaciones entre
las palabras clave (es decir, lemmas) en las dimensiones
seleccionadas (véase a continuación).

Por defecto, el cuadro anterior incluye los 100 lemas más
importantes. Sin embargo, el usuario puede personalizar tanto el
número de lemas como las características del
gráfico.
|


