|
www.tlab.it
Contextos Clave de Palabras
Temáticas
Esta herramienta de
T-LAB puede ser utilizada
para alcanzar dos objetivos diferentes:
a) extraer conjuntos de unidades de contexto que permiten
profundizar el valor temático de palabras-clave especificas;
b) extraer las unidades de contexto que son más parecidas a los
textos de muestra propuestos por el
usuario.
Los procedimientos a
seguir, paso a paso, son:
Caso (A)
Éste funciona de la siguiente manera:
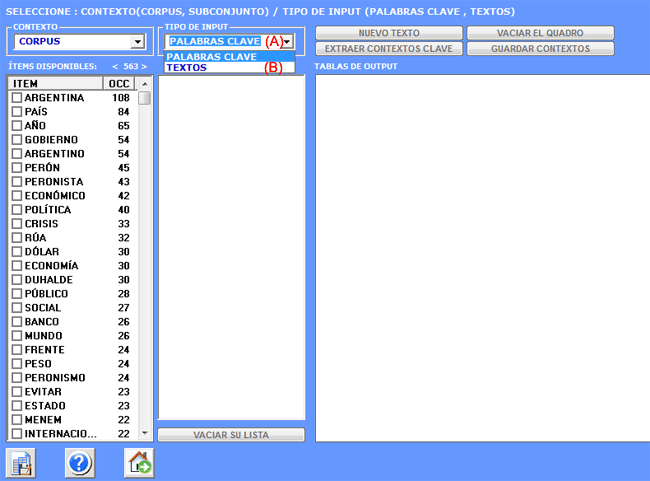
1- el usuario elige una
palabra temática "X" (véase abajo);
2- T-LAB propone una lista de palabras (máximo
50) los cuales valores de co-ocurrencia con "X" son más
significativos;
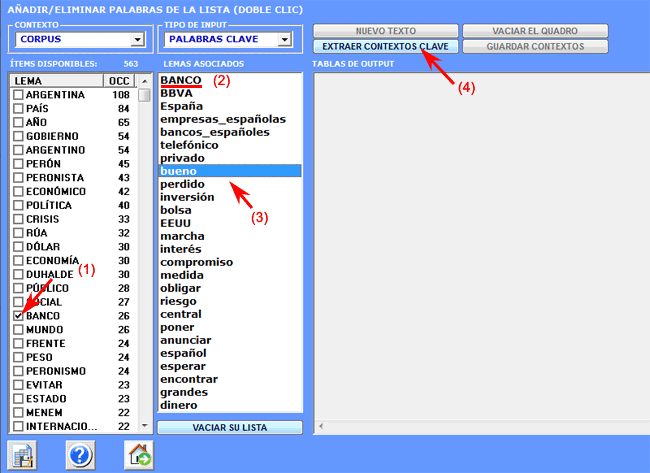
3- el usuario
puede quitar ítems irrelevantes de la lista
proporcionada;
T-LAB asume que la lista del usuario es un
vector de búsqueda (query vector) y computa sus índices de asociación (es decir los coeficientes
del coseno) con todos los contextos elementales del corpus o del
subconjunto
seleccionado;
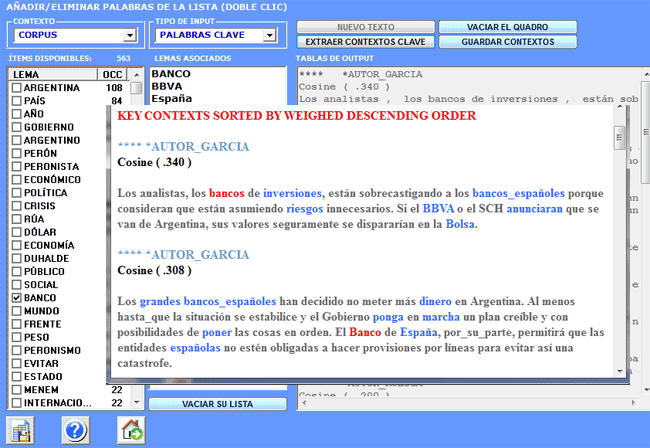
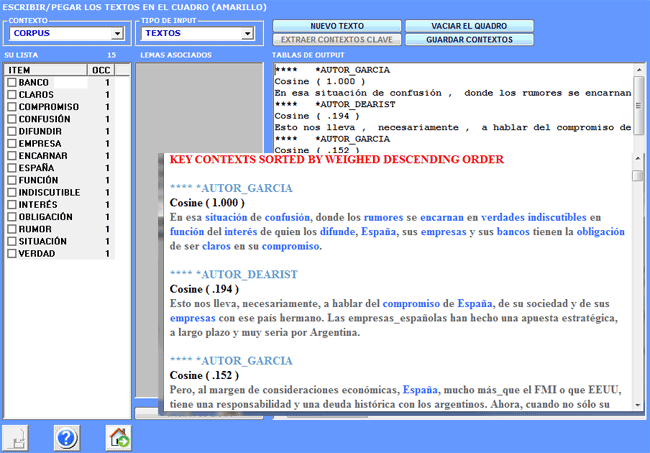
4- el output es un archivo
HTML que contiene una lista de
los contextos clave más significativos de "X" enumerados por orden
descendente de sus índices de asociación (véase abajo).
Nota: Desemejante de la función Concordancias, que
permite la extracción de todos los contextos elementales en los
cuales las palabras clave seleccionadas son presentes
(ocurrencias), y desemejante de la función Asociaciones de
Palabras, que permite
la extracción de todos los contextos elementales en los cuales las
palabras clave seleccionadas se emparejan (co-ocurrencias), esta
herramienta nos permite extraer los contextos elementales en los
cuales cada palabra clave seleccionada se asocia a un conjunto de
otras palabras (co-ocurrencias múltiples) que definen su campo
temático.
Los resultados, tanto en formato HTML como en TXT, contienen un
listado de los contextos clave más significativos de 'X' y están
ordenados, de forma decreciente, en base a sus índices de
asociación.
Los pasos 1-4 pueden ser reiterados para "n" palabras
temáticas.
Caso (B)
Éste funciona de la siguiente manera:
1 - El usuario copia/pega un
'modelo' de texto (máx. 5000 caracteres) en la casilla
correspondiente;
2 - Después de haber seleccionado la
opción 'extraer contextos clave', T-LAB transforma el texto introducido en un
vector (query vector) y calcula los índices reativos de asociación
(es decir, los coeficientes coseno) junto con todos los contextos
elementales del corpus o del subconjunto seleccionado.
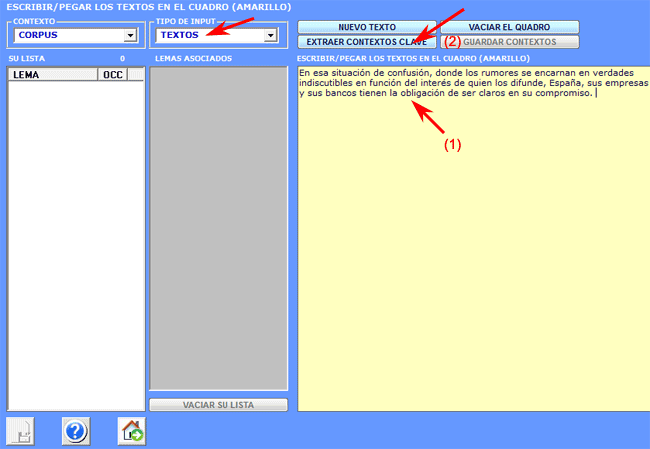
Los resultados, bien en formato HTML o bien en formato
TXT, contienen un listado de los contextos clave que más semejanza
tienen con el texto de input.
Nota: En este caso, la medida de semejanza no incluye a las
palabras múltiples cuyas cadenas, con o sin el carácter de guion
bajo ('_'), no correspondan al texto analizado.
Los pasos 1-2 pueden ser reiterados para "n" modelos de
texto.
|


