|
www.tlab.it
Clasificación Basada en
Diccionarios
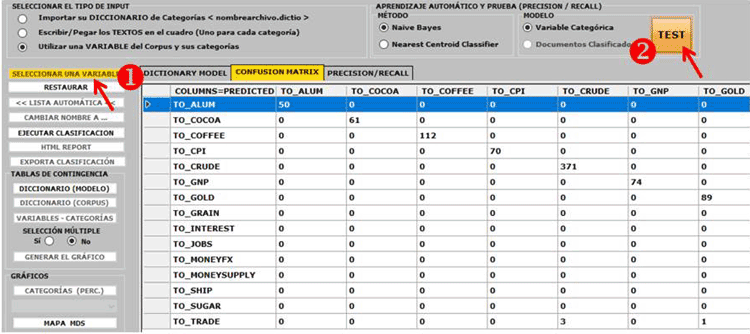
 NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. En particular, a partir de la versión 2021, una
nueva característica permite probar fácilmente cualquier modelo en
datos etiquetados (por ejemplo, datos que incluyen temas obtenidos
de un análisis cualitativo anterior) y obtener resultados como
matrices de confusión y métricas de precisión / recall (ver imagen
a continuación).
NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. En particular, a partir de la versión 2021, una
nueva característica permite probar fácilmente cualquier modelo en
datos etiquetados (por ejemplo, datos que incluyen temas obtenidos
de un análisis cualitativo anterior) y obtener resultados como
matrices de confusión y métricas de precisión / recall (ver imagen
a continuación).
Esta herramienta de T-LAB permite implementar una clasificación automática tanto de las unidades lexicales (es decir, palabras y lemas,
incluidas los multiworlds ) como de las unidades de contexto (frases, párrafos o pequeños
documentos) presentes en un corpus. Todo esto aplicando un conjunto
de categorías predefinidas o elegidas por el usuario
Según el tipo de categorías elegidas, que pueden ser
importadas a través de un diccionario o generadas por
T-LAB, dicha clasificación
puede considerarse como una variedad de análisis del contenido o como una tipología de
sentiment analysis.
Ya que el proceso de análisis permite la creación de
variables nuevas y de ulteriores diccionarios que se pueden
importar y exportar en otros proyectos de análisis, dicho
instrumento se puede también utilizar para explorar el mismo corpus
según perspectivas diferentes. Además, esta herramienta permitiría
analizar dos o más conjuntos de textos aplicando los mismos
modelos.
Entre los posibles usos de
la herramienta destacan:
- Codificación automática de las respuestas a preguntas
abiertas;
- Análisis top-down de los discursos políticos;
- Sentiment Analysis de los comentarios sobre productos
específicos;
- Verificación del proceso psicoterapéutico;
- Validación de metodologías para el análisis
cualitativo.
A continuación se proporciona una breve descripción de
las cuatro fases principales del proceso de análisis. Éstas, sin
embargo, tienen que ser consideradas como independientes las unas
de las otras. De hecho, el investigador también tiene la opción de
utilizar esta herramienta sólo para personalizar sus diccionarios o
para explorar su conjunto de datos.
A) - FASE DE PRE-PROCESSING
Existen, para la fase de pre-processing, tres posibles
puntos de partida, con tipologías
distintas de input asociadas a ellos:
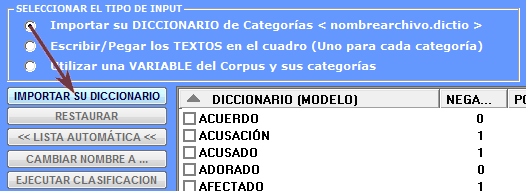
1 - Un diccionario
pre-configurado de las categorías en el formato apropiado, y que ya
se encuentra disponible (véanse las informaciones que a ello
conciernen en la sección 'E' de este documento). En este caso hay
que seleccionar la opción 'Importar su Diccionario' (véase
abajo);
2 - Un diccionario de las categorías que hay que generar
a partir de ejemplos de textos o a
partir de listas de palabras
proporcionadas por el usuario. En este caso es suficiente teclear o
copiar/pegar los textos en la casilla apropiada (un ejemplo por
cada categoría, en secuencia y con un máximo 100.000 caracteres por
cada uno);

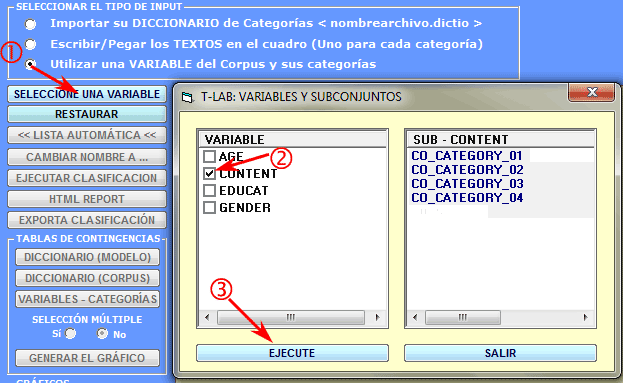
3 - Un diccionario que hay que generar a partir de las
categorías de una variable obtenida en
un análisis anterior de contenido. En este caso es suficiente hacer
clic en la opción 'Seleccione una variable' y realizar las
elecciones apropiadas (véase abajo).
En base al punto de partida en el que se encuentre el usuario, y
antes de habilitar la función 'Ejecutar Clasificación',
T-LAB funciona de la siguiente
manera:
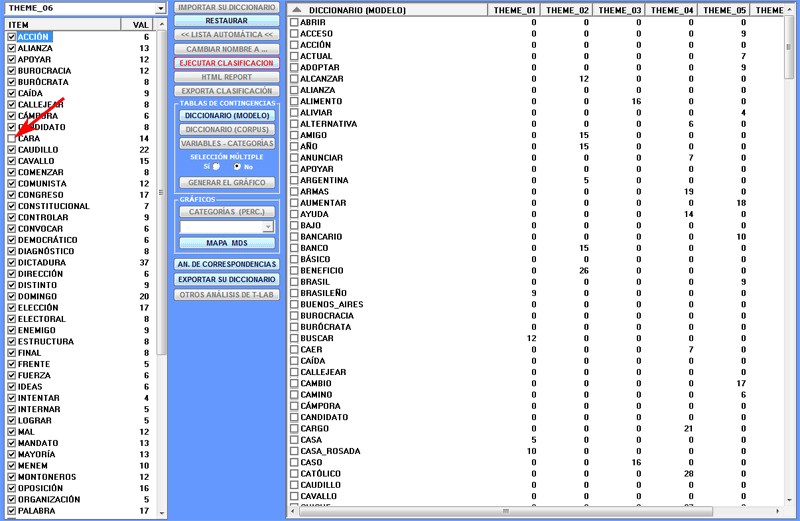
1 - Se transforma el diccionario importado en una tabla
de contingencia que el usuario puede utilizar de distintas maneras
(véase la sección 'C' de este documento). Además, seleccionando
cada categoría, es posible eliminar uno o más de los elementos
correspondientes (véase imagen de abajo).
2 - Una vez que se hayan introducido los textos de
ejemplo en la casilla correspondiente, y después de haber
seleccionado la opción 'Lista automática' (véase abajo),
T-LAB ejecuta una tipología de
lematización específica que sólo utiliza el diccionario del corpus
seleccionado (véase el listado de palabras en la zona de izquierda
de la imagen siguiente) y luego transforma cada texto en un listado
cuyos elementos pueden ser incluidos o excluidos en la selección.
Sucesivamente, para convalidar cada lista de palabras (es decir,
cada categoría del diccionario), se necesita seleccionar la opción
'Aplicar su lista' (véase abajo). Es necesario repetir cada una de
las operaciones recién mencionadas para cada categoría presente en
el diccionario. Después de haberlo hecho, el usuario está en
disposición de ejecutar las operaciones descritas en la sección 'C'
de este documento.
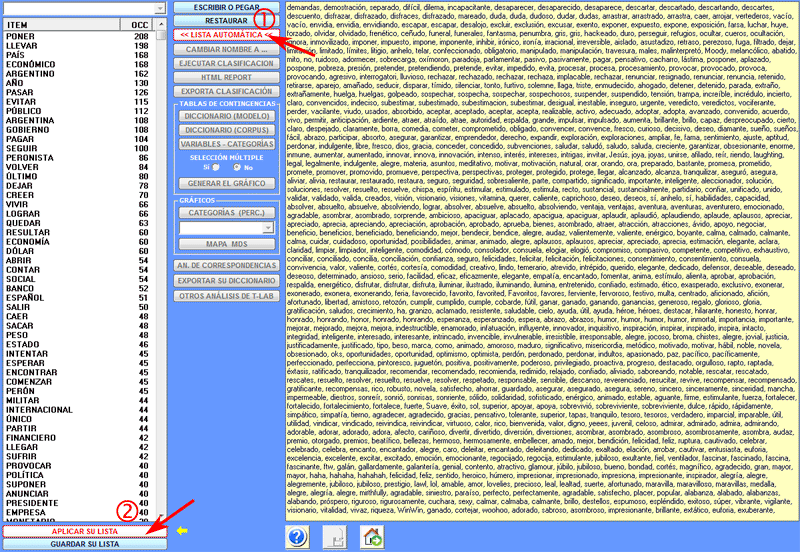
3 - Cuando se selecciona una variable proporcionada por
un anterior análisis del contenido, T-LAB le asocia una tabla de contingencia
palabras por categorías. De esta manera el usuario puede ejecutar
todo tipo de operaciones de exploración de los datos (véase la
sección 'C' del presente documento).
B) - PROCESO DE CLASIFICACIÓN
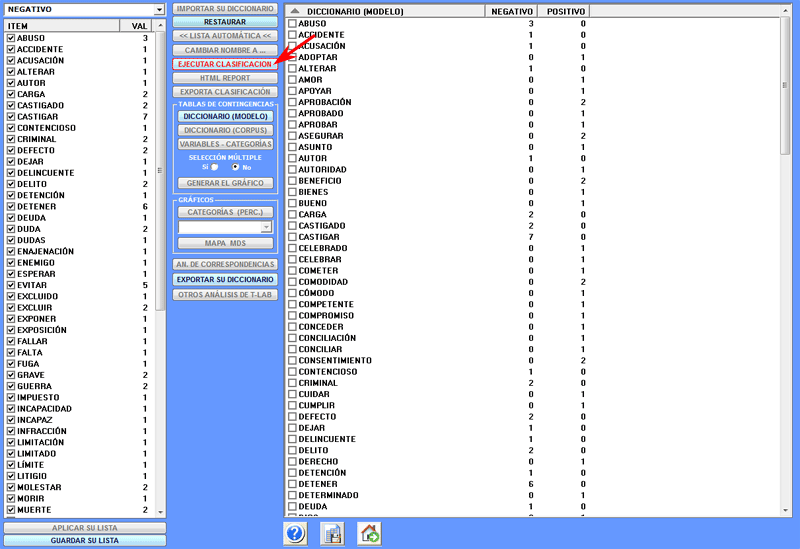
Después de haber seleccionado la opción 'Ejecutar
Clasificación' (véase arriba), el usuario puede elegir, según el
tipo de corpus que esté analizando, entre las siguientes
opciones.
En este punto, si el usuario decide clasificar las palabras, no hay ulteriores
opciones disponibles. De hecho, en este caso, las ocurrencias de
cada palabra (es decir, los word tokens) simplemente se enumeran
como ocurrencias de la categoría correspondiente. Pongamos el caso
de que en nuestro diccionario exista la categoría 'religión', y que
ésta incluya las palabras 'fe' y 'oración'. A la hora de analizar
un documento que contenga ambas palabras, T-LAB se limitaría a juntar sus ocurrencias.
Por ejemplo, 2 ocurrencias de la palabra 'fe' y 3 ocurrencias de la
palabra 'oración', se convertirían en 5 ocurrencias de la categoría
'religión'.
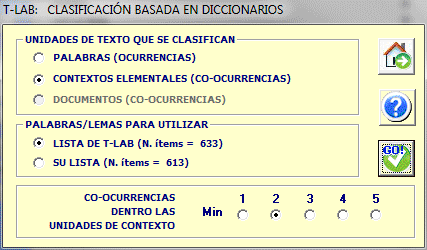
Por otro lado, si el usuario decide clasificar las unidades de contexto (es decir
'contextos elementales', como frases y párrafos, o 'documentos'),
T-LAB considera tanto las
categorías del diccionario como las unidades de contexto a
clasificar en términos de perfiles de co-ocurrencia (es decir, term
vectors), y calcula sus medidas de semejanza. Para ello, se pueden
filtrar los perfiles de co-ocurrencia bien a través de una 'lista
de T-LAB' (es decir una lista que incluya todas aquellas
palabras-clave que tengan valores de ocurrencia mayores o iguales
al umbral mínimo de 4), bien mediante una lista personalizada (es
decir, un listado de palabras-clave elegidas por el usuario).
Dichas listas, sin embargo, pueden a veces resultar iguales.
Además, en estos casos, T-LAB
permite excluir del análisis las unidades de contexto que no
incluyan un número mínimo de palabras-clave (véase arriba el
parámetro 'co-ocurrencias dentro de las unidades de
contexto').
Cuando, como en el caso recién descrito, los 'objetos' a
clasificar son las unidades de contexto, T-LAB procede de la siguiente forma:
a) Normaliza los vectores correspondientes a las 'k'
categorías (perfiles columna) del diccionario utilizado;
b) Normaliza los vectores correspondientes a las unidades de
contexto que hay que analizar;
c) Calcula medidas de semejanza (coseno) y diferencia (distancia
euclidiana) entre cada uno de los 'i' vectores, correspondientes a
todas de las unidades de contexto, y cada uno de los 'k' vectores,
correspondientes a todas las categorías del diccionario
utilizado;
d) Asigna cada unidad de contexto ('i') a la clase o categoría
('k') con la que mantiene la relación de semejanza más alta. (Nota:
En todos los casos, para cada pareja 'unidad de contexto' /
'categoría', el valor máximo del coseno y el valor mínimo de la
distancia euclidiana deben coincidir. De no ser así,
T-LAB considera la unidad de
contexto 'i' como 'no clasificada').
En otras palabras, en el caso recién descrito, T-LAB utiliza algo parecido a un método
K-means , donde los 'k' centroides se definen a priori y no vienen
actualizados durante el proceso de análisis.
Debido a que, en este caso, la clasificación es de tipo top-down,
la calidad de los resultados obtenidos depende, básicamente, de dos
factores:
1 - La 'pertinencia' del diccionario utilizado (véase relación
entre léxico del corpus y diccionario de las categorías),
2 - La capacidad 'discriminante' de cada una de las categorías
(véase relación entre las categorías del diccionario).
De hecho, cuando estos dos factores alcanzan el nivel óptimo, ambos
parámetros de 'precision' y 'recall' (véase
http://en.wikipedia.org/wiki/Precision_and_recall) toman valores
comprendidos entre 80% y 95%.
Cabe recordar que, de momento, T-LAB no tiene en consideración las fórmulas
de negación. Consecuentemente, si a la hora de implementar una
sentiment analysis, una frase como 'No odies tu enemigo' podría ser
clasificada con tonalidad 'negativa'. Los usuarios expertos pueden
gestionar este problema mientras se importa el corpus (véase el uso
de listas para stop-words y multi-words). Por ejemplo, la expresión
'no odies' se puede transformar en 'no_odies' y, si se considera
oportuno, se puede incluir en la categoría
'positivo'.
C) - EXPLORACIÓN DE LOS DATOS
En el uso de esta herramienta, toda actividad de
exploración hace referencia a tablas de
contingencias que, según los casos, pueden incluir tanto los
datos de input (por ejemplo, un diccionario de categorías) como los
de output (por ejemplo, los resultados del proceso de
clasificación).
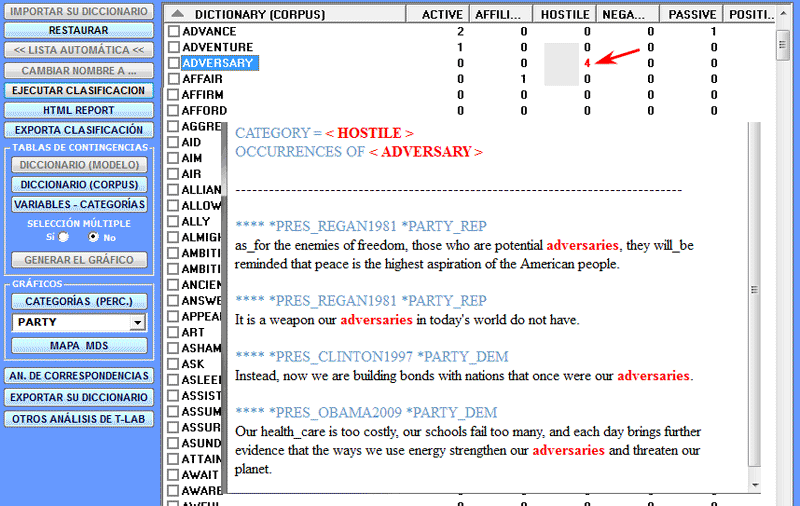
Más en concreto, concerniente a los resultados del
análisis, y dependiendo del tipo de unidad textual clasificada -
(a) 'palabras', (b) 'contextos elementales' o (c) 'documentos' -
las celdas de las tablas visualizadas pueden contener los
siguientes valores:
a) El total de las ocurrencias de cada palabra que, dentro del
corpus analizado o de un subconjunto del corpus, ha sido
clasificada como perteneciente a una categoría predefinida (es
decir, a la 'j' columna de la respectiva tabla de contingencia).
Cabe destacar que, en este tipo de clasificación, las palabras que
pertenecen simultáneamente a dos o más categorías tienen los mismos
valores repetidos en las columnas correspondientes;
b) El total de los contextos elementales asociados a una categoría
determinada (es decir, la 'j' columna) donde está presente la
palabra en la línea 'i' correspondiente;
c) Total de las ocurrencias de cada palabra (véanse líneas de la
relativa tabla de contingencia) dentro de los documentos asociados
a cada categoría (véanse columnas de la tabla de contingencia)
.
Haciendo clic en los check-box correspondientes a los
diferentes ítems puestos en las líneas de la tabla, es posible
obtener gráficos que se pueden personalizar de distintas maneras.
Además, en el caso de la clasificación de tipo 'b' (véase arriba),
si se hace clic en los valores contenidos en las celdas, es posible
visualizar los contextos de ocurrencia de cada palabra.
A continuación, se presentan los output de un análisis en
el que se han aplicado algunas categorías de un diccionario
'clásico' en el análisis del contenido (Harvard IV-4) a los
discursos inaugurales de los presidentes de EEUU.
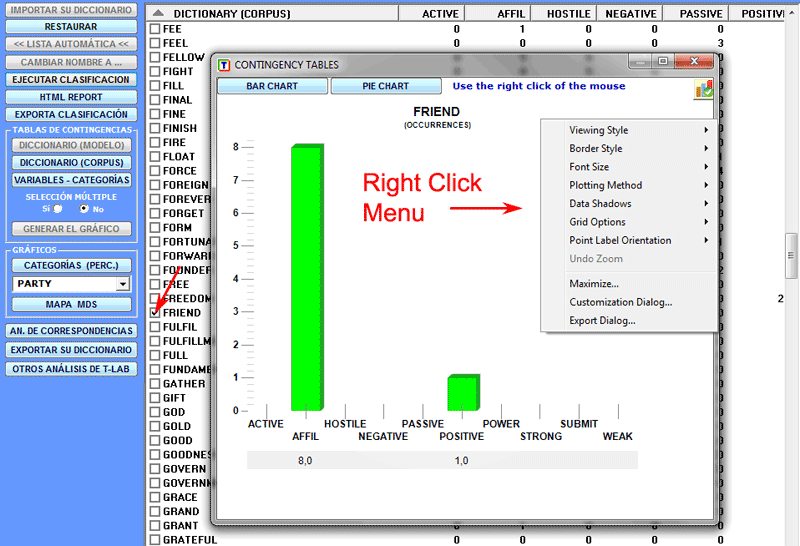
Para realizar gráficos con diferentes series de datos, a
las cuales corresponderán diferentes líneas de las tablas de
contingencia, es suficiente escoger la opción 'selección múltiple'
(opción 'SÍ'), seleccionar los elementos deseados, hasta un máximo
de 20, y hacer clic en el botón 'Generar Gráfico' (véase
abajo).
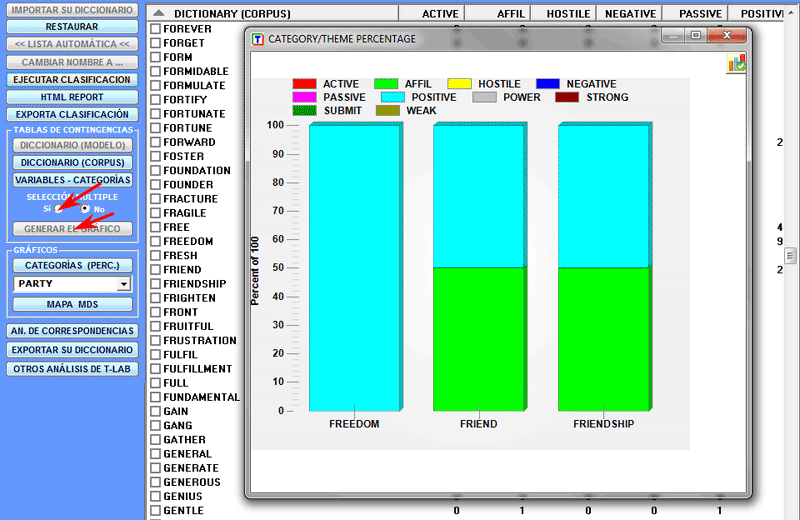
Las dos opciones recién mencionadas, también están
disponibles para las tablas que incluyen los valores de las
variables.
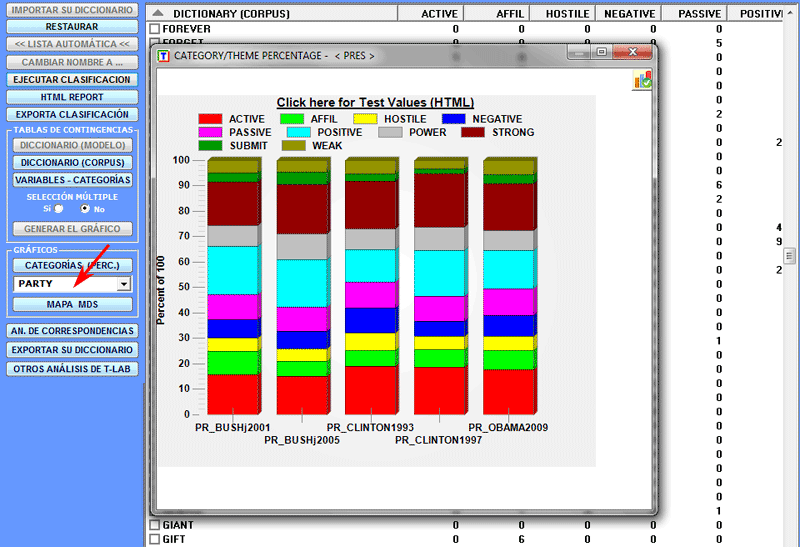
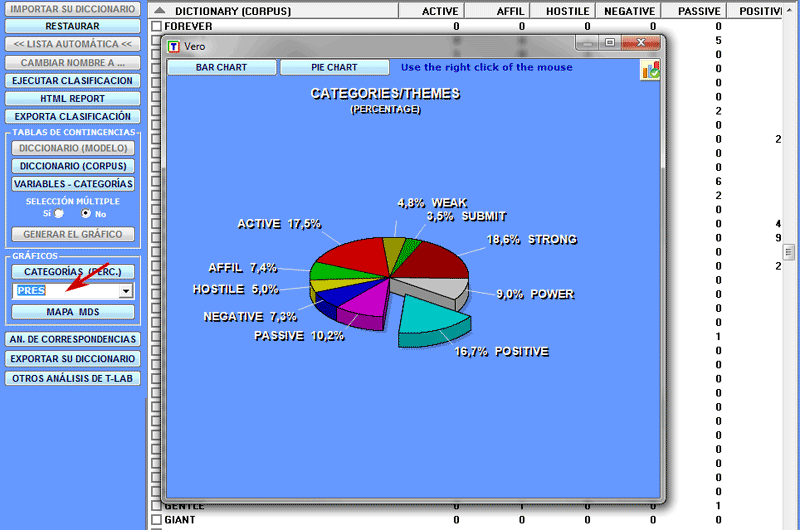
Existen distintas maneras de verificar los porcentajes de las
diferentes categorías (véase abajo).
Para explorar la estructura entera de los datos incluidos
en las tablas de contingencia se puede utilizar tanto la opción
'MDS' como la opción 'Análisis de Correspondencias' (véase
abajo).
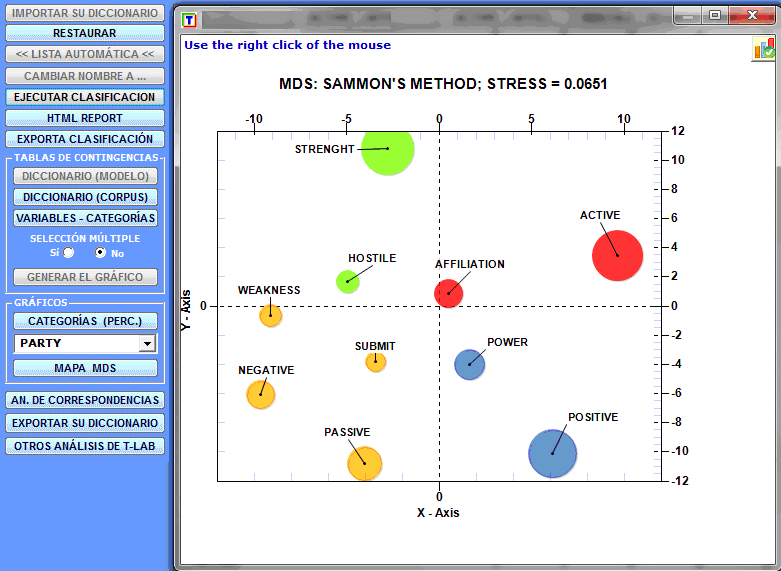
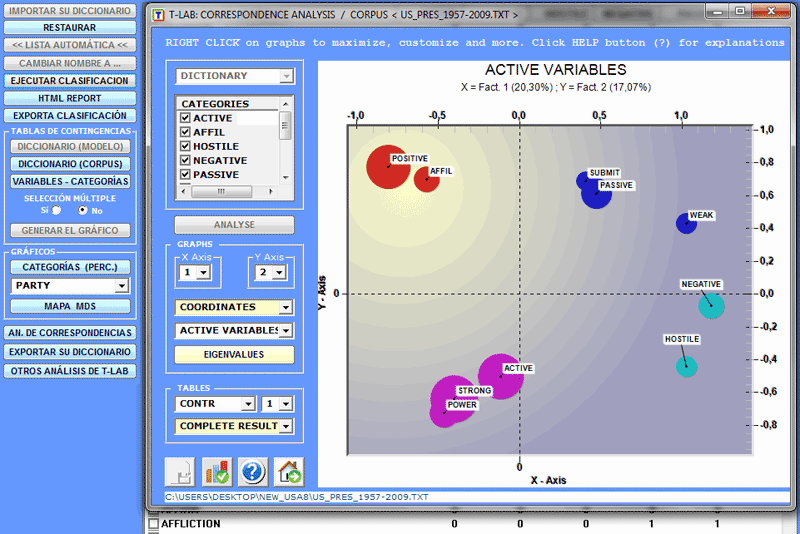
Sólo en el caso en que las unidades de contexto hayan
sido clasificadas, es posible visualizar y exportar otros output
con sus datos correspondientes. Además, en este caso, también se
pueden guardar los resultados de los análisis en una variable
nueva, y así seguir la exploración con otras herramientas del menú
T-LAB.
Más en concreto, haciendo clic en el botón 'HTML Report', es
posible visualizar algunos de los resultados del proceso de
clasificación en el que se asigna una puntuación de semejanza
(coseno) a todos los 'contextos elementales' o 'documentos' que
pertenecen a las diferentes categorías (Nota: Las imágenes que
siguen se refieren a un corpus de documentos que contienen breves
descripciones de empresas).
 . .
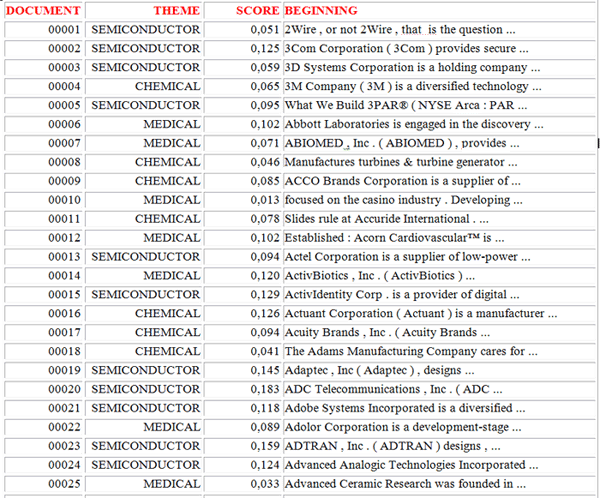
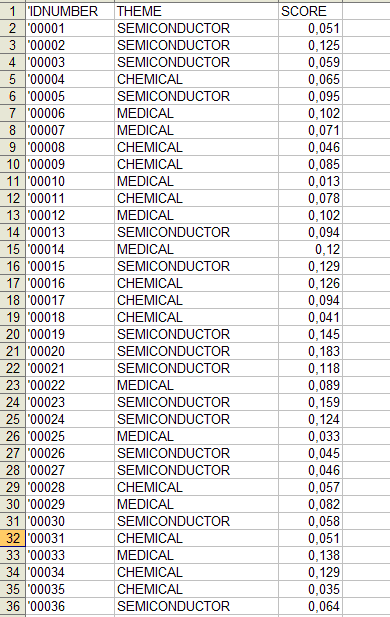
Datos parecidos pueden ser exportados en archivos XLS
(véase abajo) que contienen todas las informaciones inherentes a
los contextos elementales ('Context_Classification.xls') o los
documentos ('Document_Classification.xls') clasificados
correctamente;
(1) - Context_Classification.xls
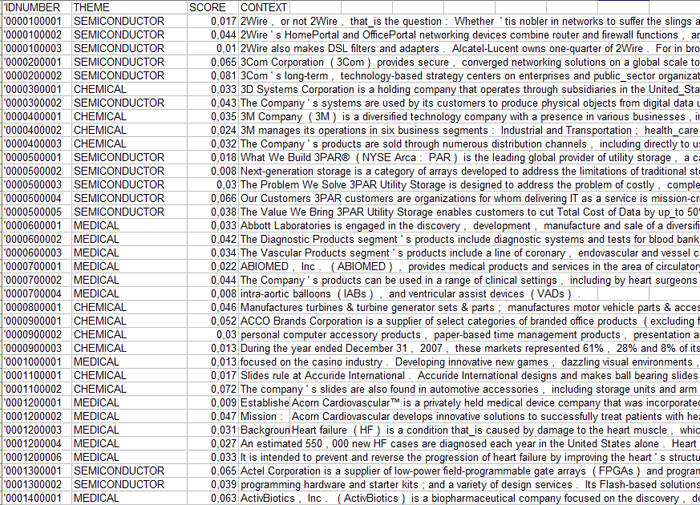
(2) - Document_Classification.xls
D) - FASES POSTERIORES DEL PROCESO DE
ANÁLISIS
Una vez que el proceso de clasificación haya producido
sus output, existen dos opciones disponibles:
-- 'Exportar su diccionario', que genera un diccionario
listo para ser importado y utilizado en otras herramientas de
T-LAB para los análisis
temáticos;
- 'Otros análisis de T-LAB', que, en función de la estructura del
corpus analizado, del tipo de clasificación implementado y del
número de categorías aplicadas, produce una nueva variable que
puede ser utilizada por otros instrumentos de T-LAB (véase abajo).
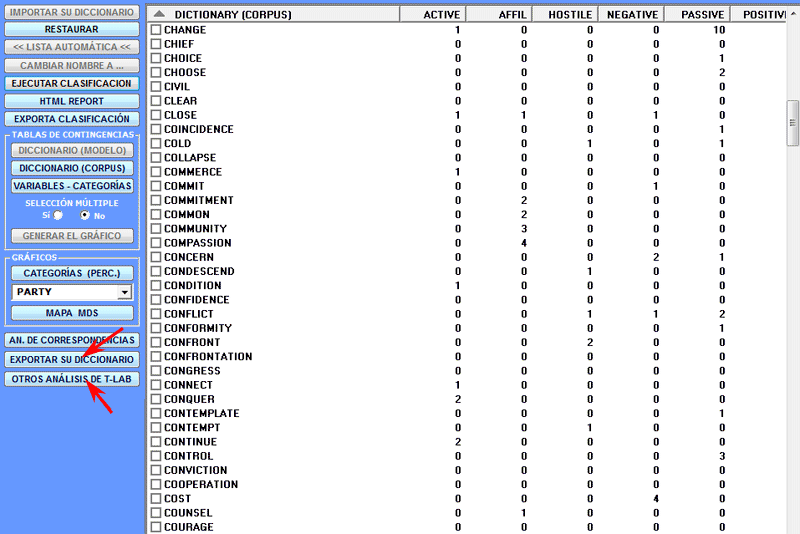
A continuación se muestra un ejemplo construido a través del
análisis de un 'subconjunto' de contextos clasificados por la
herramienta 'Asociaciones de Palabras'
(véase el menú principal T-LAB).
E) - FORMATO INPUT/OUTPUT DE LOS DICCIONARIOS T-LAB
Se presentan aquí todas las informaciones acerca de los
formatos de diccionarios que pueden
ser importados por esta herramienta de T-LAB:
- Todos los diccionarios deben ser archivos de texto
(ASCII/ANSI) con extensión 'dictio.' (ej. Mycategories.dictio);
- Todos los diccionarios creados por herramientas T-LAB para los análisis temáticos, incluidos
los creados por la herramienta 'Clasificación basada en
Diccionarios', están listos para la importación, sin necesidad de
posteriores modificaciones por parte del usuario;
- Otros diccionarios, tanto estándar como personalizados, deben de
ser creados siguiendo las presentes indicaciones:
1 - Cada diccionario se compone de 'n' líneas y no puede
superar las 100.000 record ;
2 - Cada línea del diccionario incluye dos o tres 'cadenas'
separadas por el signo de punto y coma (ejemplo: económico;
crédito);
3 - Para cada línea, la primera cadena debe ser una 'categoría', la
segunda una 'palabra' (o lema) y la tercera - si la hay - debe ser
un numero real positivo (es decir, un numero entero), comprendido
entre '1' y '999', y que representa el 'peso' de cada palabra
dentro de la categoría correspondiente;
4 - El tamaño máximo de una cadena (palabra, lema o categoría) es
de 50 caracteres y no debe contener ni espacios vacios ni
apóstrofos;
5 - Cuando el diccionario incluye multi-words (ej. Gobierno
Federal), los espacios deben ser sustituidos por el carácter '_'
(ej. Gobierno_Federal);
6 - En cada diccionario, el número de categorías utilizadas puede
variar de un mínimo de 2 a un máximo de 50. Cuando el numero de
categorías es superior a 50, se aconseja utilizar un diccionario de
diferente formato e importarlo a través de la herramienta Personalización del diccionario (véanse
'Herramientas de Léxico' en el menú T-LAB). Cabe recordar que, en este caso, cada
palabra debe tener una correspondencia unívoca con una sola
categoría.
A continuación se presentan dos extractos de archivos
.dictio, con dos y tres cadenas por línea respectivamente:
a) Caso con dos cadenas (es decir 'parejas' de categorías
y palabras)
...
negativo;catastrófico
negativo;nocivo
...
positivo;fantástico
positivo;satisfecho
...
b) caso con tres cadenas (es decir, categorías, palabras
y números)
...
negativo;catastrófico;10
negativo;nocivo;8
...
positivo;fantástico;9
positivo;satisfecho;7
|


