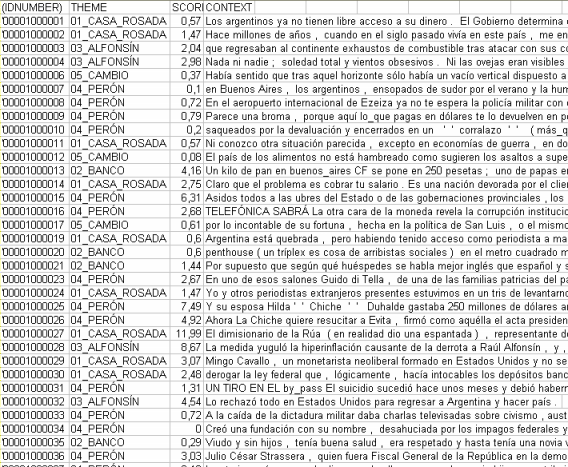
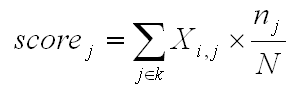|
|
T-LAB 10.2 - AIUDA EN RED |
|
|
www.tlab.it
Análisis Temático de Contextos Elementales
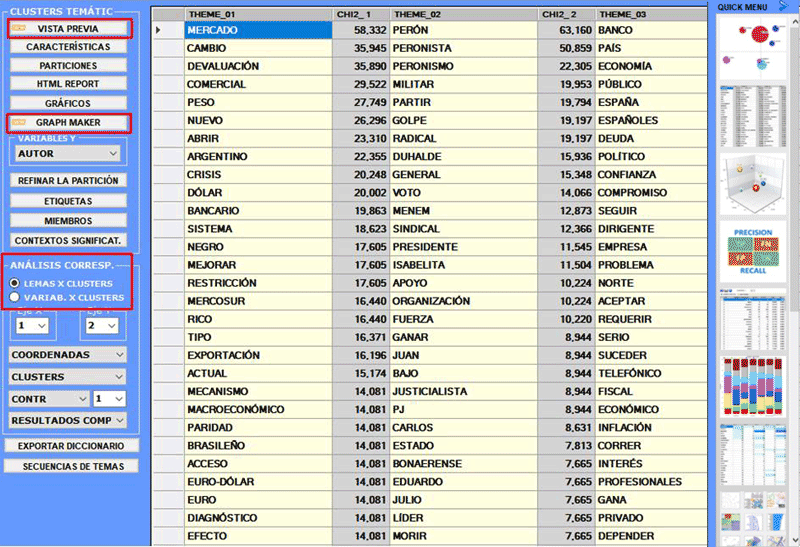
Esta herramienta de T-LAB nos permite obtener una representación de los contenidos del corpus mediante pocos y significativos clusters temáticos (de 3 a 50), de modo que cada uno de ellos: a) resulta constituido de un conjunto de contextos elementales (ej. frases, párrafos, fragmentos de texto, respuestas a preguntas abiertas) caracterizados por los mismos patrones (patterns) de palabras clave; b) puede ser descrito por las unidades lexicales (palabras, lemas o categorías) y por las variables (si presentes) que más caracterizan los contextos elementales de los cuales se compone. Por muchos motivos, los resultados del análisis se pueden interpretar como mapas de isotopías (iso = igual; topos = lugar), es decir como mapas de temas "genéricos" o "específicos" (Rastier, 2002: 204) caracterizados por la co-ocurrencia de componentes semánticos. El proceso de análisis puede ser implementado bien a través de un método de clustering 'no supervisado' (en el caso concreto, un algoritmo bisecting k-means) o bien a través de una clasificación 'supervisada' (es decir, el enfoque top-down). Si se elige el segundo procedimiento, (es decir, clasificación supervisada), se requiere la importación de un diccionario de las categorías, resultado de un anterior análisis T-LAB o de una elaboración del usuario.
En particular: - el parámetro (A) permite que el usuario fije el número
máximo de clusters que se incluirán en los outputs de
T-LAB; NOTA: En el caso de clustering no supervisado (opción por defecto), el proceso de análisis se compone de las siguientes etapas: a - construcción de una tabla unidades de contexto x
unidades lexicales (hasta 300.000 filas x 5.000 columnas), con
valores de tipo presencia-ausencia; NOTA : A partir de la versión de T-LAB Plus 2016 , el
agrupamiento no supervisado de las unidades de contexto (véase más
arriba elel paso 'c' más) puede ser realizado de dos maneras (1)
bien usando el algoritmo bisecting k-means o (2) bien usando una
versión no centrada del PDDP (es decir, Principal Direction
Divisive Partitioning) propuesto por D. Booley (1998) para
seleccionar los centroides de las diferentes bisecciones
K-means. Así, este procedimiento realiza un análisis de las co-ocurrencias (pasos a-b-c) y, a
continuación, un análisis comparativo
(e-f-g). En particular, el análisis comparativo utiliza como
columnas de las tablas de contingencia las modalidades (niveles o
categorías) de la "nueva variable" derivada del análisis de las
co-ocurrencias (modalidades de la nueva variable = clusters
temáticos). NOTA: Cuando el usuario decide repetir/aplicar los resultados de un análisis anterior (tanto Análisis Temático de Contextos Elementales como Modelización de los Temas Emergentes), T-LAB realiza sólo ejecuta un análisis comparativo (pasos e-f-g). Al término del análisis, el usuario puede efectuar
rápidamente las siguientes operaciones: En detalle: 1 - Explorar las características
de los clusters
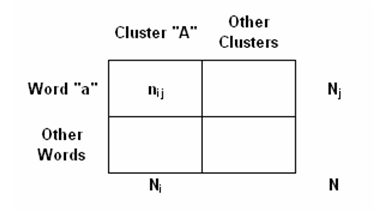
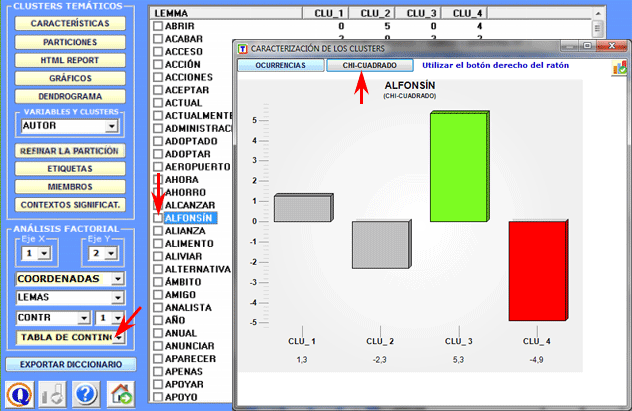
En el caso del chi cuadrado la estructura de la tabla analizada es la siguiente:
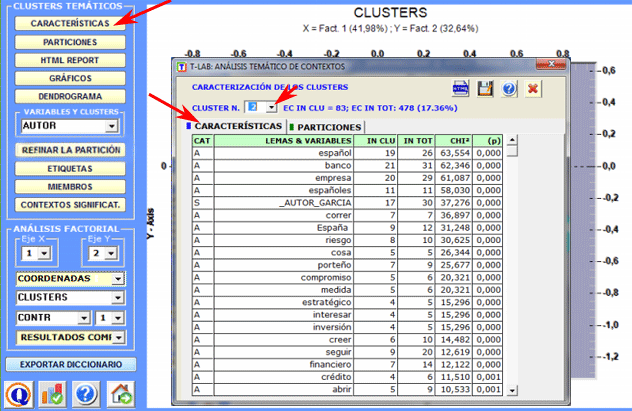
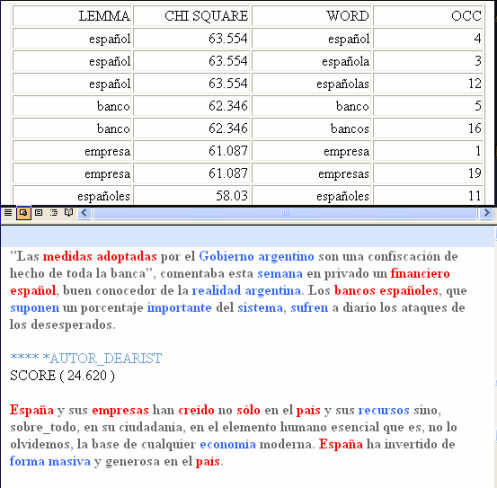
Un informe HTML (ver a continuación) permite verificar en detalle las características de los clusters. En éste, además de la lista de palabras típicas, se muestran los contextos elementales que más caracterizan el cluster seleccionado, ordenados de manera descendente según el respectivo peso (score).
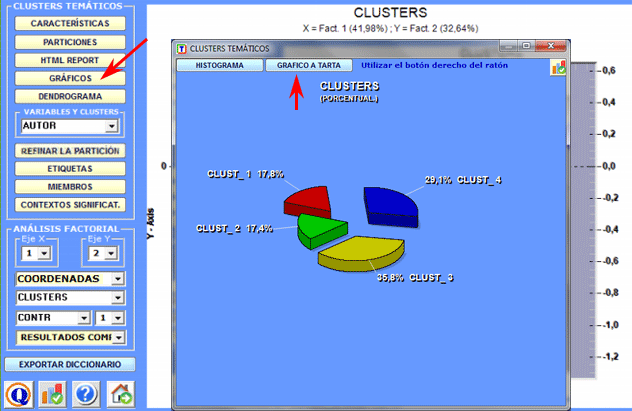
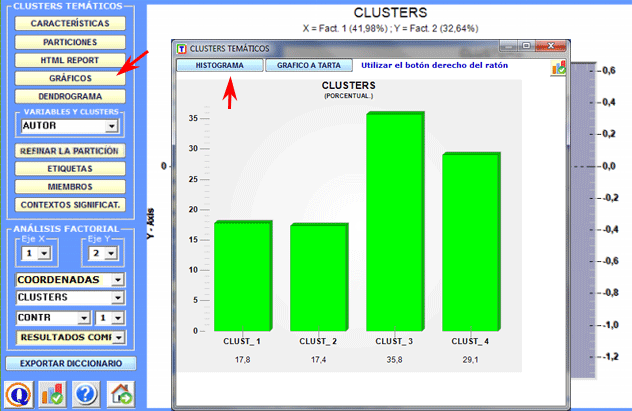
Gráficos a tarta y histogramas (véase abajo) permiten verificar el porcentaje de unidades de contexto que pertenece a cada cluster.
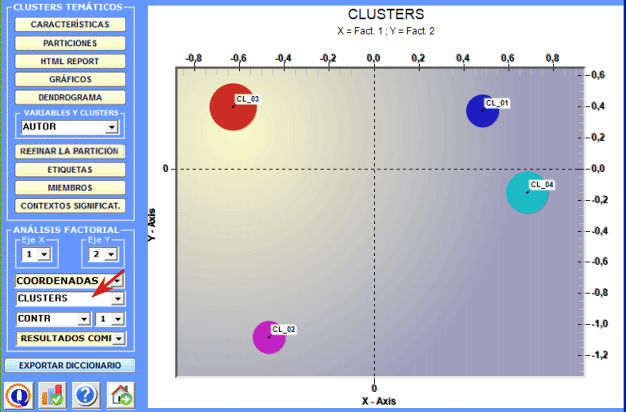
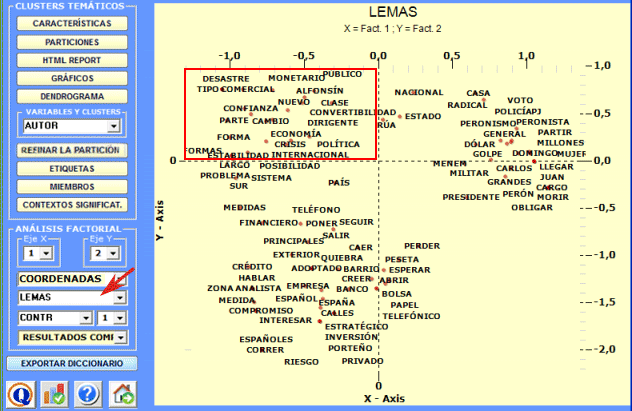
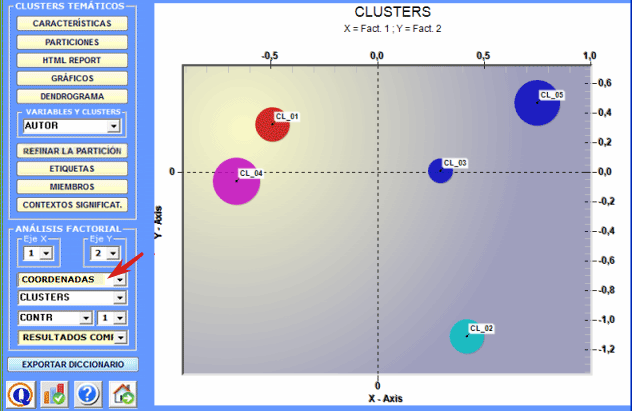
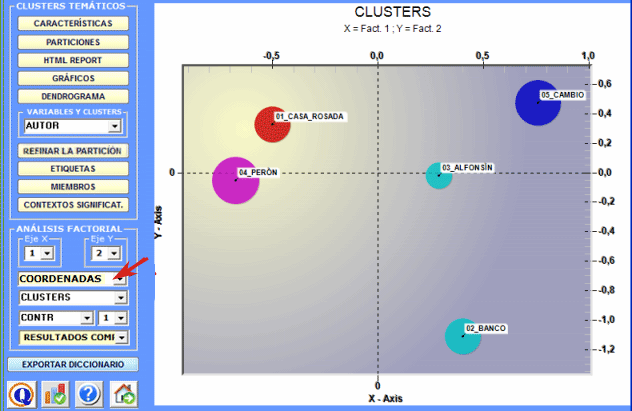
2 - Explorar las relaciones entre clusters Algunos gráficos, obtenidos por medio de Análisis de
Correspondencias, permiten explorar las relaciones entre
clusters en espacios bidimensionales.
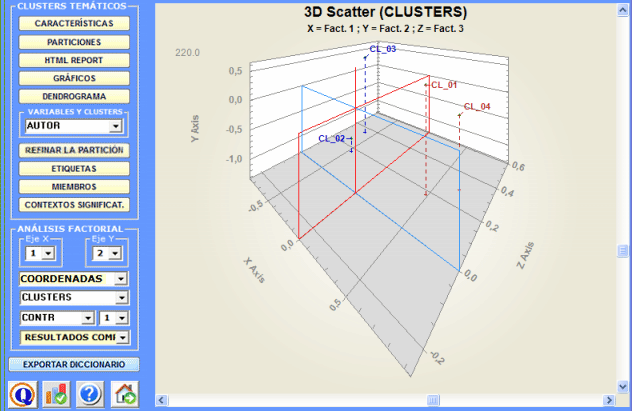
Todos los gráficos pueden ser personalizados usando el apropiado cuadro de diálogo (hacer clic en el botón derecho del ratón). Además cuando los clústers temáticos son más de tres, sus relaciones pueden ser exploradas en gráficos 3D (ver abajo).
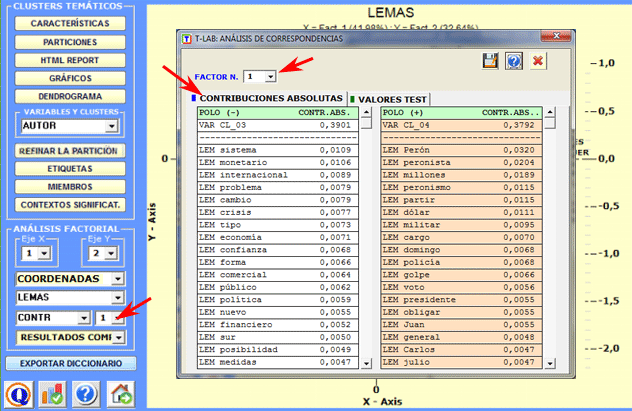
Las características de cada polo factorial pueden ser exploradas haciendo clic en los botones marcados en rojo.
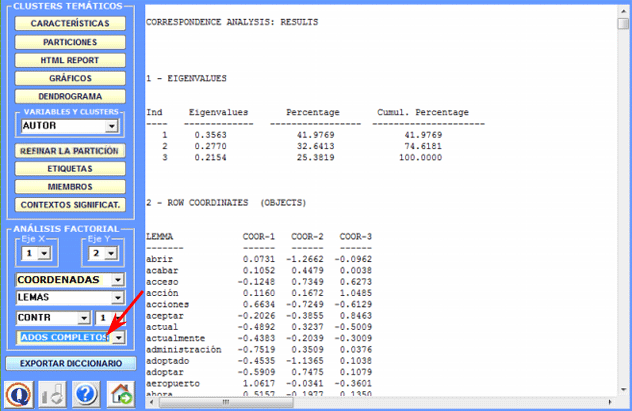
Un clic en el botón correspondiente permite que usted visione y guarde el archivo que contiene los resultados completos del análisis: valores propios, coordenadas, aportes absolutos y relativos, valores tes: valores propios, coordenadas, aportes absolutos y relativos, valores test.
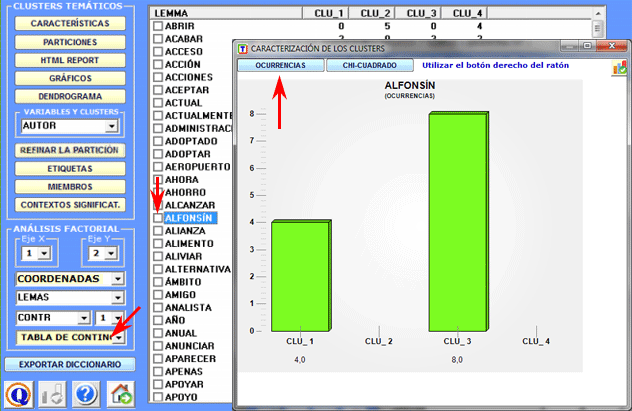
Una opción específica
(véase más abajo) nos permite visualizar/exportar la tabla de contingencia y crear gráficos que
muestran la distribución de cada palabra dentro de los
clusters. NOTA: Esta tabla incluye
tanto las palabras clave activas ("A") como aquellas suplementarias
('S').
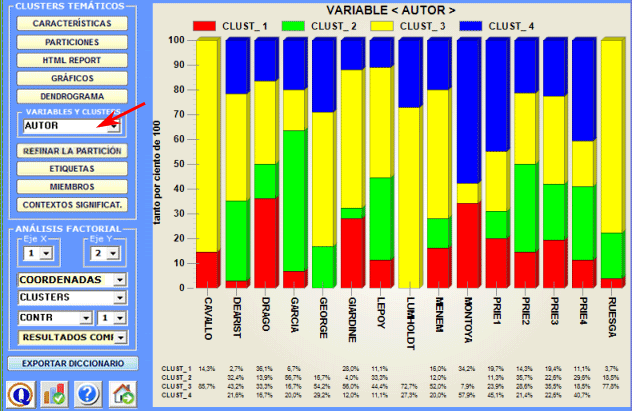
3 - Explorar las relaciones entre clusters y variables Algunos histogramasnos permiten verificar las relaciones entre los clusters y las variables.
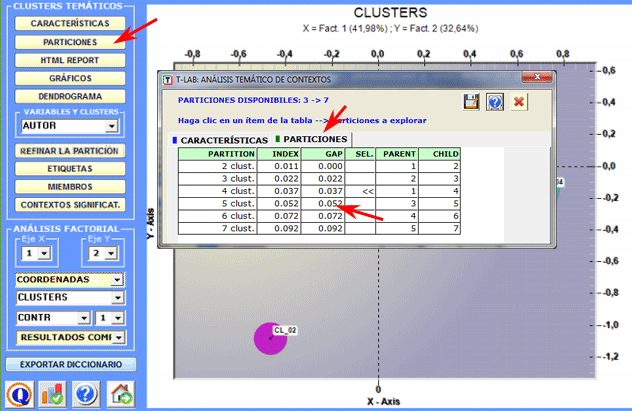
Además es posible explorar ulteriores relaciones entre clusters y variables con las opciones disponibles en la sección Análisis factorial" (ver más arriba). 4 - Explorar las diversas particiones de los clusters Posto que el
algoritmo usado produce una clusterización jerárquica, el usuario
puede explorar fácilmente diferentes soluciones del análisis:
particiones de 3 a 50 clusters. La opción particiones permite explorar las características de las soluciones disponibles (clic en los ítems de la tabla).
Además, la opción dendrograma (véase abajo) permite dos posibilidades: A) verificar el árbol de las diferentes bisecciones de los clústeres;
B) verificar el árbol de las palabras características de cada clúster.;
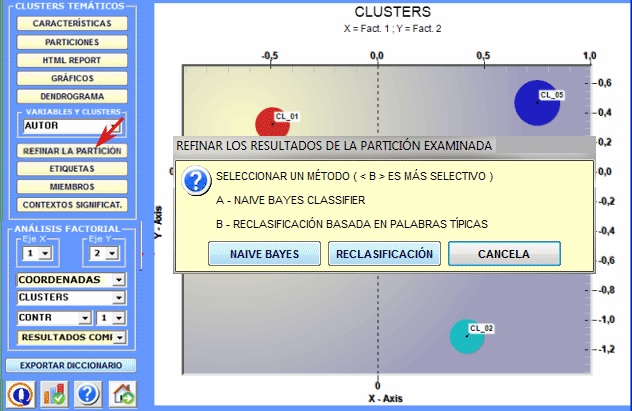
5 - Refinar los resultados de la partición elegida Después de haber explorado diversas soluciones, el usuario puede refinar los resultados de la partición elegida y, si es necesario, repetir unos pasos antedichos (1,2,3). Para alcanzar este objetivo, hay dos métodos disponibles (véase imagen siguiente).
Cuando se elige el método 'A' (es decir, el Naïve
Bayes Classifier), esta opción de T-LAB
permite que el usuario suprima del análisis todas las unidades del
contexto cuya pertenencia a un cluster no satisface los criterios
siguientes: Por otro lado, en el caso del método 'B' (es decir, Re-clasificación basada en las Palabras Típicas), T-LAB considera las características de los clústeres, eso es, las palabras que presentan valores significativos de Chi-Cuadrado, como ítems de un diccionario de las categorías y ejecuta las tres fases de la 'clasificación supervisada' descritas al encomienzo de esta sección. Consecuentemente, si el usuario está interesado en volver a aplicar los diccionarios y en comparar los resultados, se recomienda vivamente utilizar este método. Todos los resultados de este cómputo están en una tabla exportada por T-LAB (véase abajo), la cuál contiene los valores de probabilidad expresados en términos porcentuales.
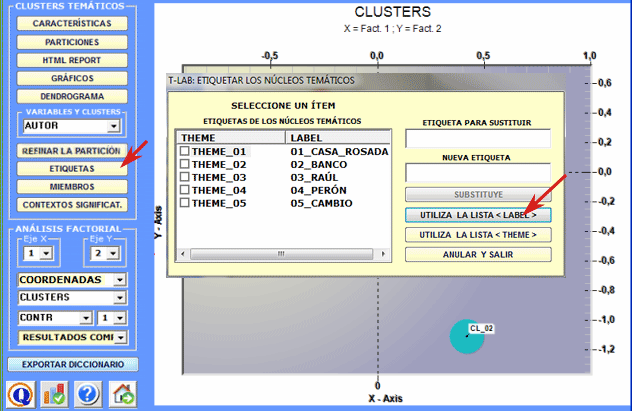
6 - Asignar etiquetas a los clusters Una función de T-LAB
permite atribuir etiquetas a los clusters.
Las etiquetas atribuidas a los distintos clusters pueden ser visualizadas en los distintos gráficos disponibles (ver a continuación).
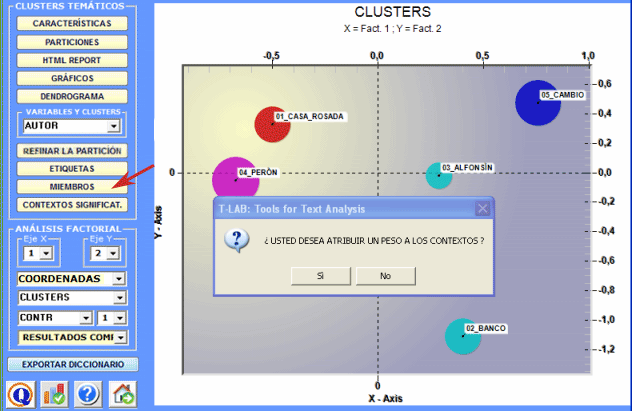
7 - Verificar qué
contextos elementales pertenecen a qué clusters;
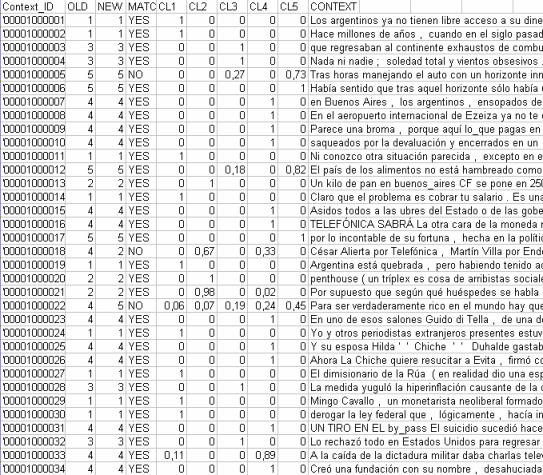
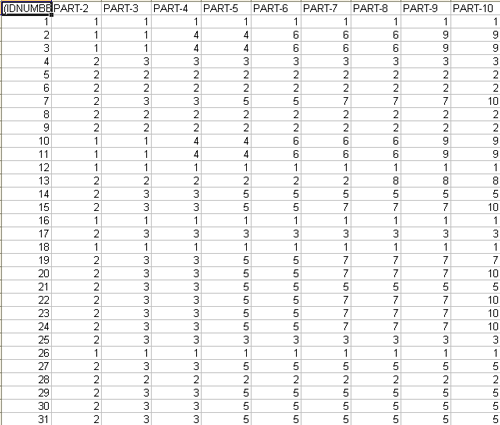
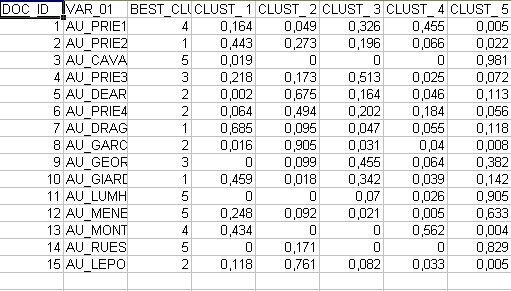
De hecho el botón Miembros permite exportar tres tipos de tablas en formato MS Excel: a - " Cluster_Partitions.xls " (véase abajo) con todas las correspondencias de unidad de contexto x cluster en el interior de las distintas particiones;
b - Themes-Contexts.xls (véase abajo) con las
correspondencias de unidad de contexto x cluster en el interior de
la partición seleccionada.
En particular, el valor de importancia (score) asignado a
cada contexto elemental (j) que pertenece al racimo (k) viene de la
fórmula siguiente:
Donde: c - " Ec_Document_Classification.xls " (proporcionado solamente cuando el cluster se compone por lo menos de 2 documentos primarios y éstos no son textos breves como las respuestas a preguntas abiertas) enumera las pertenencias mezcladas de cada documento (véase abajo).
En este caso los valores derivan de la fórmula antedicha
(véase "b") sumando los scores de los contextos elementales que
pertenecen a cada documento y aplicando un cálculo de
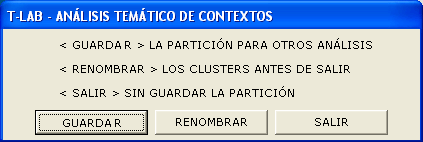
porcentaje. 10 - Archivar la partición seleccionada para explorarla con otras herramientas T-LAB A la salida de la función de Análisis temático de los Contextos elementales, algunos mensajes recuerdan que es posible explorar la partición seleccionada con otras herramientas T-LAB.
Seleccionando la opción Guardar, la variable < CONT_CLUST > (cluster de contextos elementales) queda disponible sólo en algunos tipos de análisis (por ej. Secuencias de Temas, Asociaciones de Palabras, Comparación entre Parejas, Análisis de Co-Palabras) y hasta que el usuario modifica su lista de palabras clave. 11 - Exportar un diccionario de las categorías Cuando se selecciona esta opción, T-LAB genera dos archivos: - un archivo diccionario, con extensión .dictio, que puede ser importado directamente a través de una de las herramientas disponibles para el análisis temático. En dicho diccionario, cada clúster corresponde a una categoría descrita mediante sus palabras características, es decir, mediante todas las palabras de este clúster que presentan un Chi-Cuadrado significativo; - un archivo MyList.diz listo para la importación mediante la función Configuración Personalizada. Este archivo contiene el listado, ordenado alfabéticamente, de todas las palabras que presentan un valor significativo de Chi cuadrado, es decir, de todas aquellas palabras que determinan las diferencias entre clústeres temáticos. Así pues, su uso permite repetir determinados análisis siguiendo una perspectiva aún más selectiva y discriminante. 12 - Verificar la calidad de la partición elegida y la coherencia semántica entre los diferentes temas
Al hacer clic sobre el icono Índices de Calidad (véase arriba), T-LAB genera un archivo HTML que contiene
diferentes medidas. 13 - Explorar secuencias de temas Al contrario de la herramienta Secuencias de temas , incluida en un submenú T-LAB de análisis de las co-ocurrencias, esta opción ha sido generada específicamente para integrar el análisis temático de los contextos elementales. Más en concreto, su uso adquiere sentido sólo cuando el corpus entero se considera como un discurso y/o cuando sus diferentes secciones (por ejemplo: capítulos de libro, partes de una entrevista, intervenciones de diferentes participantes en una conversación o en un debate, etc.) se alternan siguiendo un preciso orden temporal. En este caso, las relaciones analizadas son aquellas que se instauran entre contextos elementales (hasta un máximo de 100.000) a lo largo de la cadena lineal del corpus. Cada uno de ellos - tanto si son 'predecesores' como si son 'sucesores' - viene tratado como una unidad de análisis que pertenece a un clúster temático (o no clasificado). Todos los resultados proporcionados permiten al usuario
explorar las relaciones secuenciales entre 'temas', bien de forma
'estática' o bien de forma 'dinámica'. Más en concreto, el usuario
puede verificar cuándo las personas abarcan temas específicos
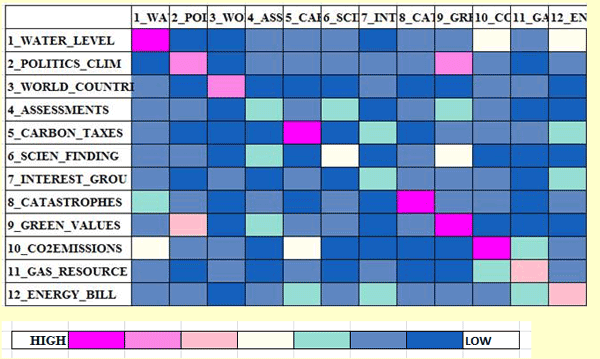
(véanse, por ejemplo, en las imágenes a continuación, los puntos
presentes en la diagonal de las matrices) y cuándo pasan de un tema
central a otro. Todo ello, contemplando la dinámica temporal de las
secuencias a través de gráficos animados. A continuación se proporciona, paso a paso, una breve descripción de las diferentes opciones disponibles. (N.B.: Todos los resultados contenidos en el ejemplo se han obtenido a partir de un análisis temático del libro The Politics of Climate Change de Antony Giddens publicado en el sitio web de T-LAB). Una vez habilitado el botón Secuencias de Temas, cliqueando el mismo se vuelve visible y activo el siguiente 'player'.
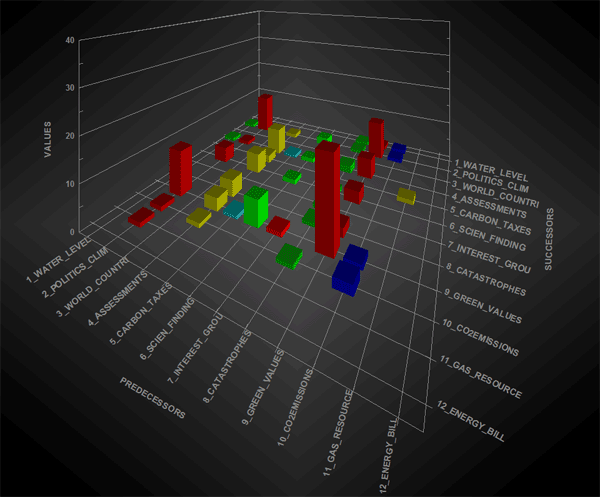
La opción '1' (véase arriba) hace referencia a la tipología de gráfico escogida para la visualización de las secuencias, tanto dentro del corpus entero como dentro de una parte del mismo (véase arriba la opción '2'). La opción 'matriz' devuelve un grafico en 3D que sintetiza las relaciones entre predecesores y sucesores mediante barras de colores ubicadas en los respectivos cruces. Respecto a los gráficos animados en 3D, cabe destacar que el aumento de longitud de las barras implica el aumento del número de ocurrencias dentro de las secuencias correspondientes (véanse relaciones binarias entre 'predecesores' y 'sucesores' en el grafico siguiente).
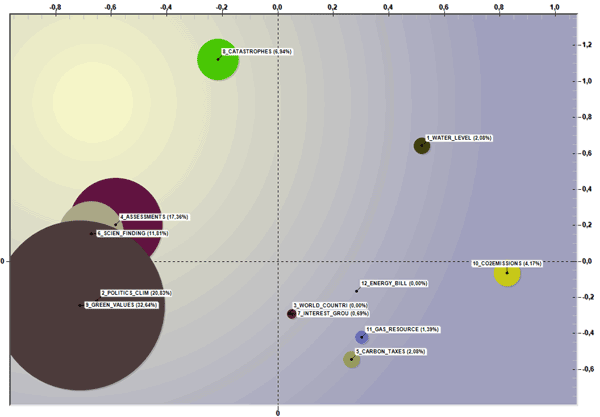
La opción 'espacio' genera un grafico en 2D en el que las dimensiones (es decir, los porcentajes) y las relaciones entre grupos temáticos están representadas en un plano compuesto por dos ejes factoriales escogidos por el usuario. En este caso, a la hora de visualizar gráficos animados, las dimensiones de las 'burbujas' - que vienen constantemente ajustadas a un total del 100% - indican cómo los porcentajes relativos a cada clúster varían en el tiempo. Al mismo tiempo, el movimiento de las flechas indica el orden según el cual se van alternando los temas.
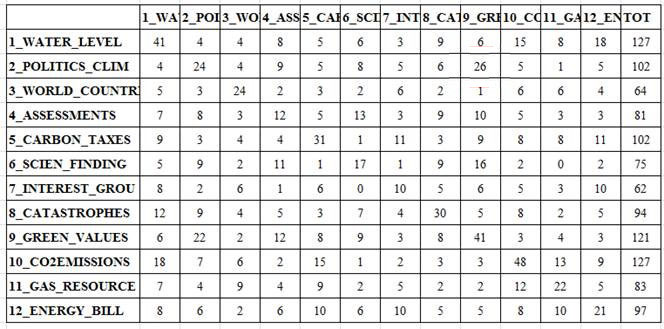
En cada una de las situaciones recién descritas es posible, tras haber parado el video (véase botón 'pausa'), visualizar dos resultados ulteriores: A - tablas html que resumen las relaciones entre predecesores y sucesores (véase abajo);
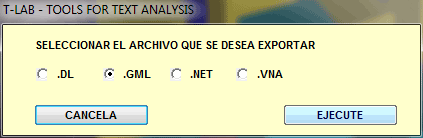
B - archivos gráficos que pueden ser importados por programas para el análisis de redes.
N.B.: El grafico anterior, que hace referencia al tercer
capitulo del libro de Giddens, ha sido creado tramite el programa
Gephi (véase https://gephi.org/).
|