|
www.tlab.it
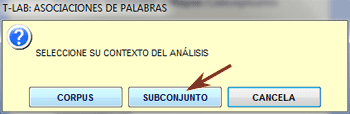
Corpus y
Subconjuntos
El corpus es una colección
de uno o más textos seleccionados para el análisis.
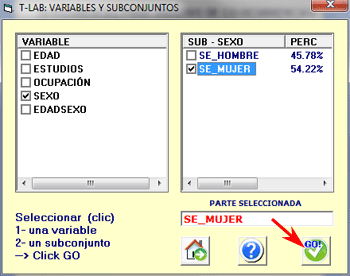
Cada subconjunto del corpus
se define por medio de una modalidad de
una variable.
T-LAB permite
explorar y analizar las relaciones entre las unidades de análisis
de todo el corpus o de sus
subconjuntos.
Algunos ejemplos de corpus:
- un solo texto o documento que trate cualquier
tema;
- un conjunto de artículos tomados de la prensa, referentes
al mismo tema;
- una o varias entrevistas realizadas en el mismo proyecto
de investigación;
- un conjunto de respuestas a una pregunta abierta de un
cuestionario;
- una lista de direcciones sacada de internet;
- uno o varios libros del mismo autor que afronten temas
similares;
- un conjunto de respuestas a una pregunta abierta de un
cuestionario;
- transcripciones de focus groups.
Algunos ejemplos de subconjuntos:
- unos o más capítulos de un libro
- unos o más artículos periodísticos publicados en el mismo
año;
- unas o más entrevistas con la misma categoría de
gente;
- un subconjunto de respuestas a una pregunta
abierta.
NOTA: Algunos subconjuntos del corpus son los
"clusters temáticos" de
documentos o de contextos elementales obtenidos usando las
herramientas correspondientes de T-LAB.
En el caso de un corpus compuesto por varios textos, para
hacer un conjunto correctamente analizable, se requiere que todas
sus piezas tengan dos características que las hagan
comparables:
a) una cierta homogeneidad temática y/o de contexto en el
cual se han producido, para obtener datos comparables;
b) relaciones equilibradas entre sus dimensiones, tanto
en términos de frecuencias como en términos de kilobytes, para no
incurrir en anomalías estadísticas.
En la lógica de T-LAB, el corpus es una base de datos organizada en registros y campos.
Más exactamente, los registros se componen de las entidades
registradas (textos, segmentos de texto, palabras) y los campos se
componen de las etiquetas usadas para clasificar las diversas
entidades (los autores del texto, los contextos de referencia, los
tipos de palabra, etc.).
Véase Preparación del
corpus.
|


