|
|
T-LAB 10.2 - AIUDA EN RED |
|
|
www.tlab.it
T-LAB: qué hace y qué permite hacer T-LAB es un software compuesto por un conjunto de herramientas lingüísticas, estadísticas y gráficas para el análisis de los textos. Dichas herramientas se pueden emplear en las siguientes prácticas de investigación: Análisis del Contenido, Sentiment Analisis, Análisis semántico, Análisis Temático, Minería de Textos, Mapas Perceptuales, Análisis del Discurso y Network Text Analysis.
En efecto, gracias a las herramientas de T-LAB, los investigadores pueden gestionar ágilmente actividades de análisis como las siguientes: - Explorar, medir y mapear las relaciones de co-ocurrencia entre
palabras-clave; La interfaz de T-LAB es muy
fácil de utilizar y los textos a analizar pueden ser de varios
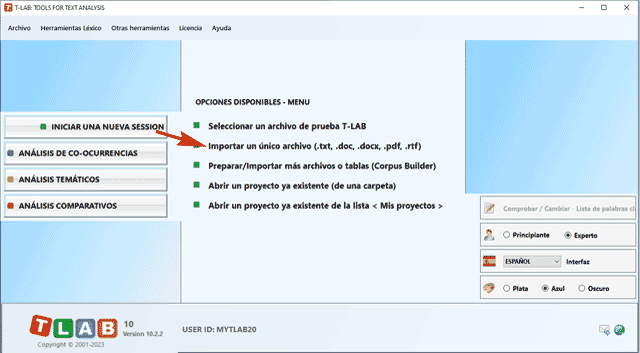
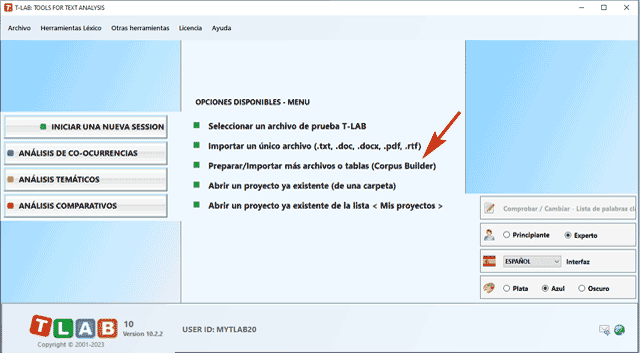
tipos: Todos los textos a analizar pueden ser codificados con variables categoriales y pueden incluir un identificativo (Unique Identifier) que corresponde a unidades de contexto o casos (ej. respuestas a preguntas abiertas). En el caso de un único documento (o corpus considerado como único texto), T-LAB no necesita nada más: es suficiente seleccionar la opción 'Importar un único archivo...' (véase abajo).
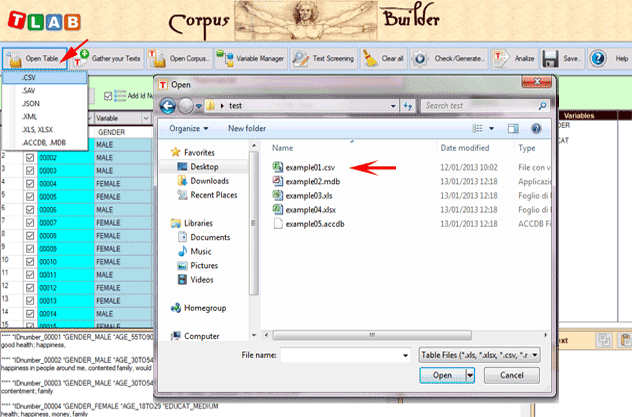
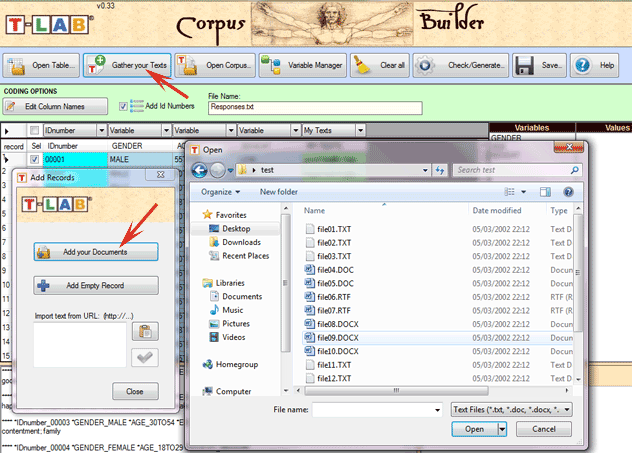
Cuando, en cambio, el corpus está compuesto por más textos y/o cuando se utilizan codificaciones que remiten al uso de alguna variable, la preparación del corpus requiere el uso del módulo Corpus Builder (véase abajo) que permite transformar diferentes materiales textuales (es decir hasta once formatos diferentes, incluyendo hojas de cálculo, archivos PDF y CSV) en un corpus codificado y listo para la importación.
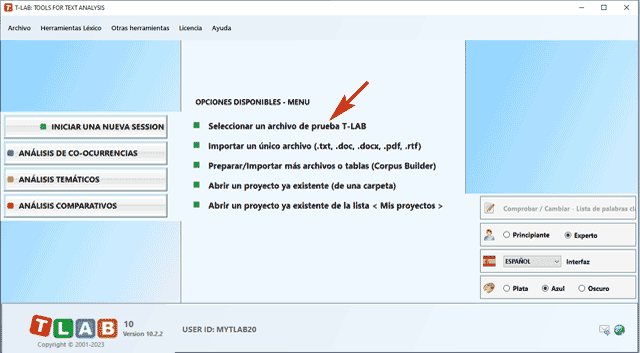
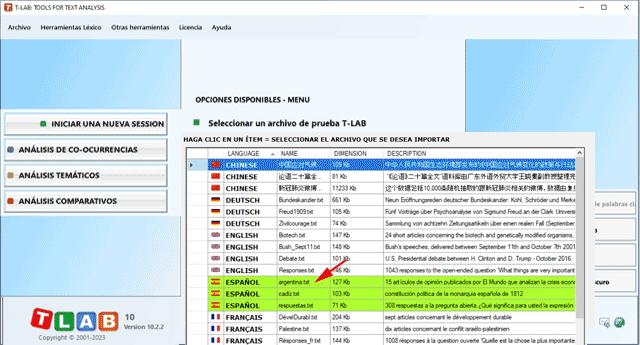
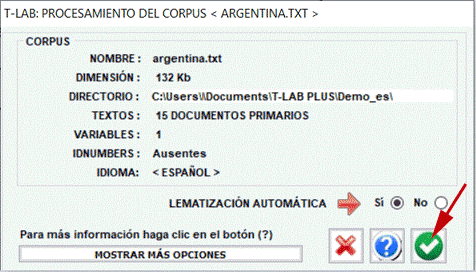
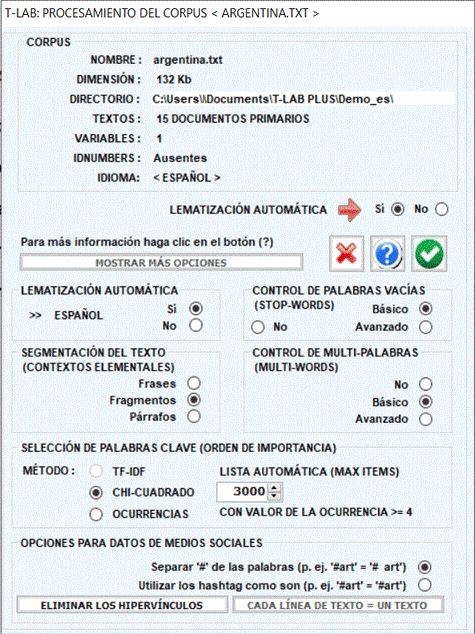
Nota: En el estado actual, T-LAB puede analizar archivos/corpus de hasta 90 MB de tamaño (es decir, aprox. 55000 páginas en formato texto), garantizando el uso integrado de las distintas herramientas. Para más informaciones, véase la sección Requisitos y Prestaciones del Help/Manual. Para verificar rápidamente las funciones del software son suficientes seis pasos: 1 - Pulsar la opción 'Seleccionar un archivo de prueba T-LAB'
2 - Seleccionar un corpus a analizar
3 - Pulsar "ok" en la ventana de Configuración
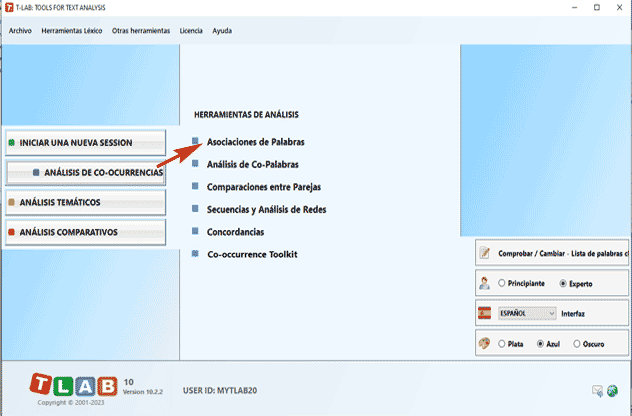
4 - Seleccionar una herramienta en uno de los submenús de "Análisis"
5 - Verificar los resultados
6 - Utilizar la ayuda contextual para interpretar gráficos y tablas.
Desde el punto de vista externo, el uso del software está organizado por la interfaz, es decir por el menú principal, los submenús y las funciones que lo componen. Desde el punto de vista lógico, además de la interfaz, el sistema T-LAB está organizado por dos componentes principales:
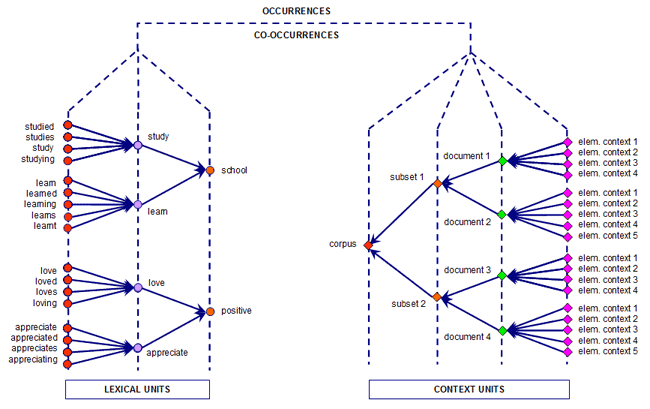
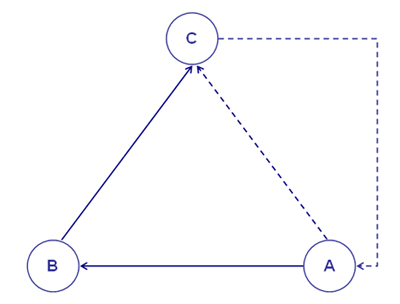
Para entender cómo funciona T-LAB y cómo puede usarse es muy importante tener claro qué unidades de análisis se archivan en su base de datos y cuáles algoritmos estadísticos se usan en los distintos análisis. En efecto, las tablas de datos analizadas están siempre constituidas por filas y columnas cuyos membretes corresponden a las unidades de análisis archivadas en la base de datos, mientras que los algoritmos regulan los procesos que permiten descubrir relaciones significativas entre los datos y extraer informaciones útiles. Las unidades de análisis de T-LAB son de dos tipos: unidades lexicales y unidades de contexto. A - las UNIDADES LEXICALES son palabras, simples o múltiples, archivadas y clasificadas en base a un cierto criterio. En particular, en la base de datos T-LAB, cada unidad lexical constituye un registro clasificado con dos campos: palabra y lema. En el primer campo (palabra) se enumeran las palabras así como aparecen en el corpus, mientras que en el segundo (lema), se enumeran las etiquetas atribuidas a grupos de unidades lexicales clasificadas según criterios lingüísticos (ej. lematización) o a través de diccionarios y plantillas semánticas definidas por el usuario. B - las UNIDADES DE CONTEXTO son porciones de texto en las que se puede dividir el corpus. En particular, en la lógica T-LAB, las unidades de contexto pueden ser de tres tipos: B.1 documentos primarios
correspondientes a la subdivisión "natural" del corpus (ej.
entrevistas, artículos, respuestas a preguntas abiertas, etc.), o
sea a los contextos iniciales
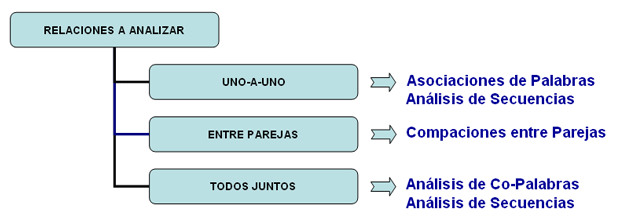
definidos por el usuario; El siguiente diagrama muestra las posibles relaciones que T-LAB nos permite analizar entre unidades lexicales y unidades de contexto.
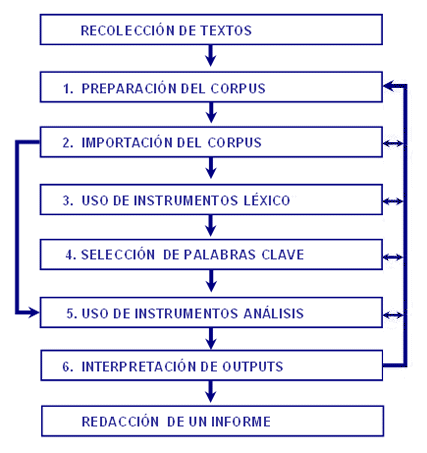
A partir de esta organización de la base de datos, T-LAB permite - automáticamente - explorar y analizar las relaciones entre las unidades de análisis de todo el corpus o de sus subconjuntos. En T-LAB, la elección de cualquier instrumento de análisis (clic del ratón) activa siempre un proceso semi-automático que, con pocas o simples operaciones, genera algunas tablas input, aplica algún algoritmo de tipo estadístico y crea algunos outputs (ver diagrama siguiente). Hipotéticamente, cada proyecto de trabajo en el que se usa T-LAB está constituido por el conjunto de actividades analíticas (operaciones) que tienen por objeto el mismo corpus y está organizado por una estrategia y por un plan del usuario. Por lo tanto, inicia con la recolección de textos a analizar y termina con la redacción de un informe.
NOTA: - Las seis fases numeradas, desde la preparación del corpus a la interpretación de los output, tienen el soporte de los instrumentos T-LAB y son siempre reversibles; - Por medio de las configuraciones automáticas T-LAB se pueden evitar dos fases (3-4); sin embargo, a los fines de la calidad de los resultados se recomienda la ejecución de las mismas. Intentamos ahora comentar, una tras otra, las distintas fases.
En el caso de un único texto (o corpus considerado como único texto), T-LAB no necesita nada más. Cuando, en cambio, el corpus está compuesto por más textos y/o cuando se utilizan codificaciones que remiten al uso de alguna variable, en la fase de preparación se hace necesario utilizar el modulo Corpus Builder que permite transformar los textos a analizar en un corpus codificado y listo para la importación. Todo ello, de forma rápida y automática. NOTA: 2 - LA IMPORTACIÓN DEL CORPUS consiste en una serie de procesos automáticos que transforman el corpus en un conjunto de tablas integradas en la base de datos T-LAB. Durante el proceso de importación, T-LAB realiza los tratamientos siguientes:
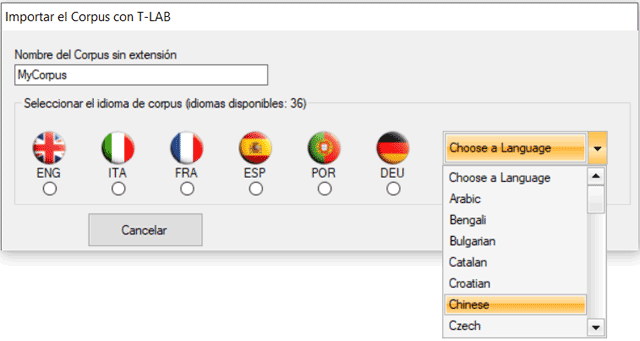
A continuación, se presenta el listado completo de los
idiomas para los cuales T-LAB prevé la posibilidad de
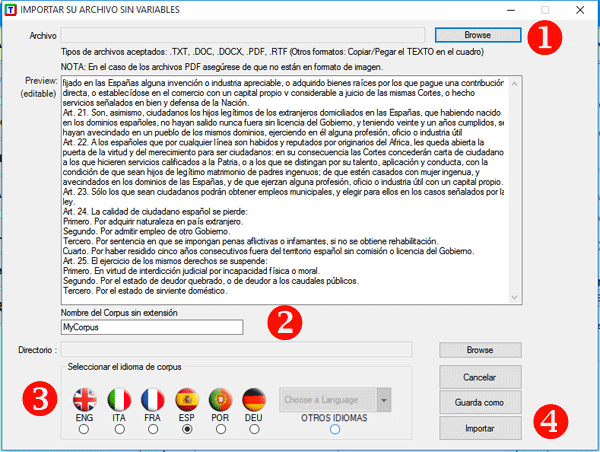
implementar procesos de lematización automática y de stemming. En cualquier caso, sin lematización automática y / o mediante diccionarios personalizados, el usuario puede analizar textos en todos los idiomas. Lo importante es que las palabras estén separadas por espacios y/o signos de puntuación.
Una vez seleccionado el idioma, la intervención del usuario será necesaria para definir las opciones indicadas en la ventana siguiente:
NOTA: Puesto que diferentes opciones determinan el tipo y la cantidad de unidades de análisis (es decir las unidades de contexto y las unidades lexicales), diversas opciones determinan diversos resultados de análisis. Por esta razón, todos los outputs de T-LAB (es decir gráficos y tablas) utilizados en el manual del usuario y en la ayuda en red son solo indicativos.
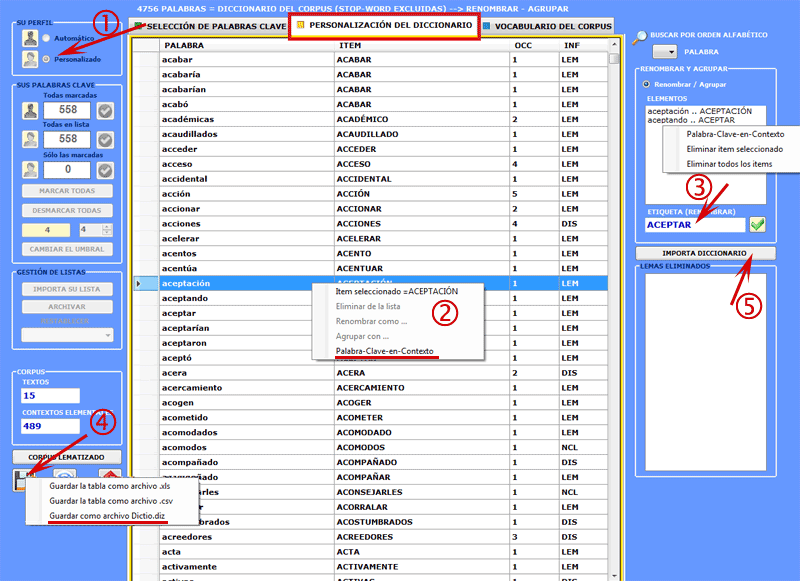
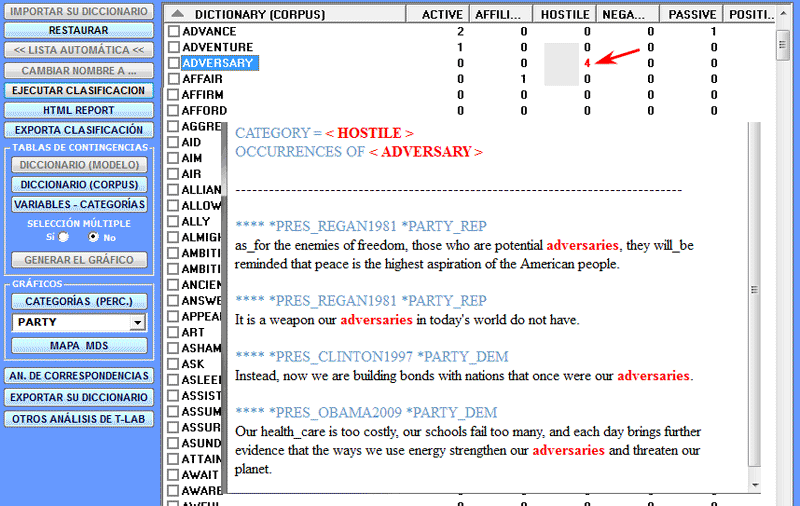
Las modalidades de las diversas intervenciones están descritas en las correspondientes voces de la ayuda (y del manual). En particular se redirecciona a la correspondiente voz de la ayuda (y del manual) para una descripción detallada del proceso Personalización del Diccionario. De hecho, cualquier modificación a las voces del diccionario (p. ej.: agrupación de dos o más ítems) incide tanto en el cálculo de las ocurrencias como en el cálculo de las co-ocurrencias).
Nota: Cuando el usuario quiere aplicar esquemas de codificación que agrupen diferentes palabras o lemas en unas pocas categorías (de 2 a 50), y sin perder ninguna información lexical, se aconseja utilizar la herramienta Clasificación basada en los Diccionarios incluido en el submenú Análisis Temáticos (véase abajo).
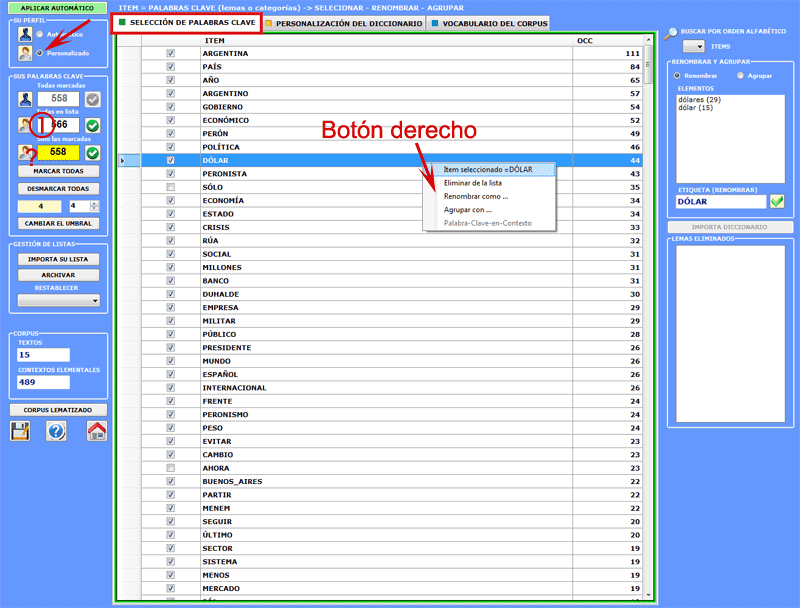
4 - LA SELECCIÓN DE LAS PALABRAS-CLAVE consiste en la predisposición de una o más listas de unidades lexicales (palabras, lemas o categorías) a utilizar para crear las tablas de datos a analizar. La opción configuración automática pone a disposición listas de palabras clave seleccionadas por T-LAB; sin embargo, dado que la elección de las unidades de análisis es muy relevante en relación a las sucesivas elaboraciones, se aconseja vivamente el uso de la configuración personalizada. De este modo el usuario podrá elegir la modificación de la lista sugerida por T-LAB y/o crear listas que correspondan mejor con sus objetivos de investigación.
En la creación de estas listas, son válidos los siguientes criterios: - verificar la relevancia
cuantitativa (total de las ocurrencias) y cualitativa (no banalidad
del significado) de los distintos términos; 5 - EL USO DE LOS INSTRUMENTOS DE ANÁLISIS está destinado a la producción de outputs (tablas y gráficos) que representan relaciones significativas entre las unidades de análisis y que permiten hacer inferencias. Actualmente T-LAB incluye quince diversas herramientas de análisis y cada una de ellas tiene su propia lógica; es decir, cada herramienta utiliza algoritmos específicos y produce output específicos. Consecuentemente, dependiendo de la tipología de textos que quiera analizar y de los objetivos que quiera alcanzar, el usuario debe decidir, cada vez que implemente una, qué instrumentos son más apropiados para su estrategia de análisis.
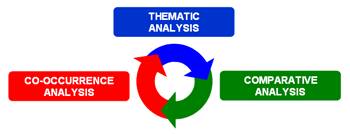
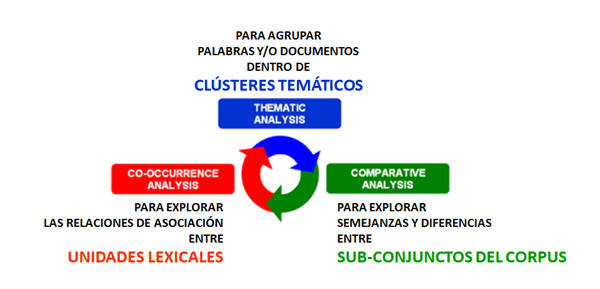
Para este propósito, además de la distinción entre instrumentos para análisis de co-ocurrencias, análisis comparativos y análisis temáticos, puede ser útil tomar en cuenta que algunos de estos nos permiten obtener nuevas unidades del análisis que se pueden incluir en otros procesos. Sin embargo, teniendo en cuenta que el uso de las herramientas T-LAB puede ser circular y reversible, podríamos escoger tres puntos de inicio (start points) que corresponden a los tres sub-menús de ANÁLISIS.
A : INSTRUMENTOS PARA ANÁLISIS DE CO-OCCURRENCIAS Estos instrumentos permiten analizar varios tipos de relaciones entre las palabras clave.
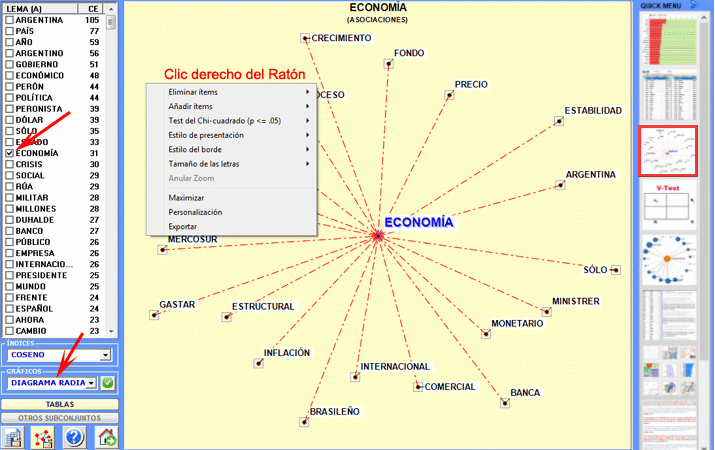
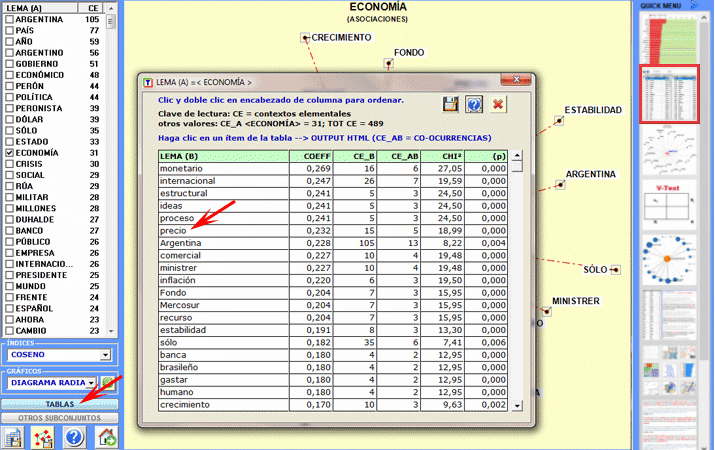
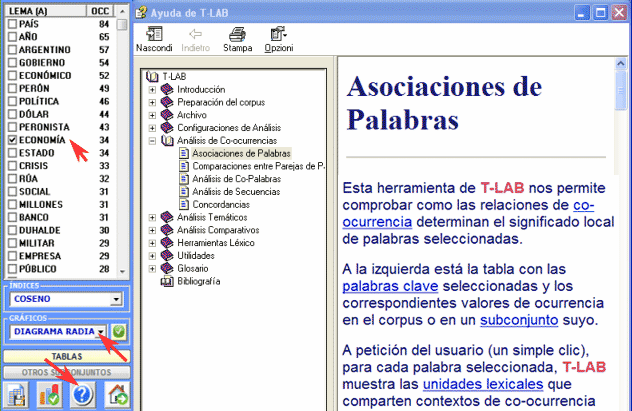
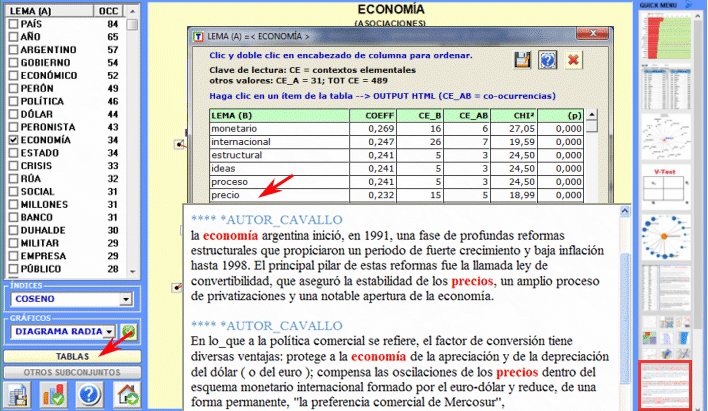
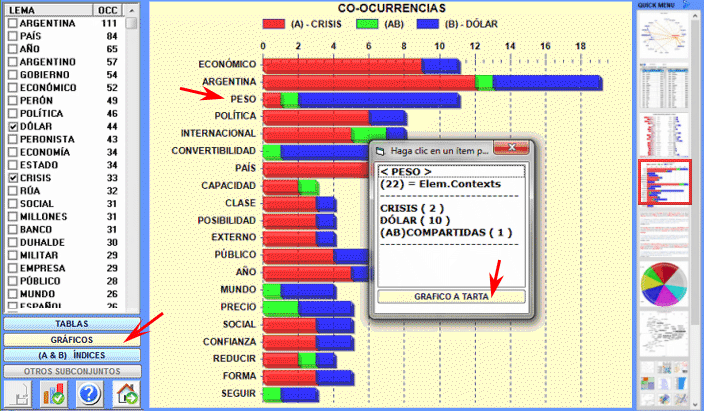
Aquí están algunos ejemplos (Nota: para más información sobre la interpretación de los resultados, véanse las secciones correspondientes en la guía/manual): Esta herramienta de T-LAB nos permite comprobar como las relaciones de co-ocurrencia determinan el significado local de palabras seleccionadas.
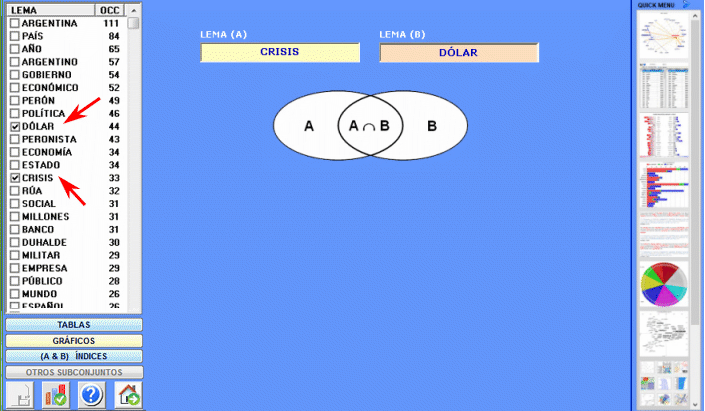
Esta herramienta de T-LAB nos permite comparar los conjuntos de contextos elementales (es decir contextos de co-ocurrencia) en los cuales los miembros de una pareja de palabras-clave están presentes.
Esta herramienta de T-LAB nos permite trazar mapas de co-ocurrencias entre conjuntos de palabras clave.
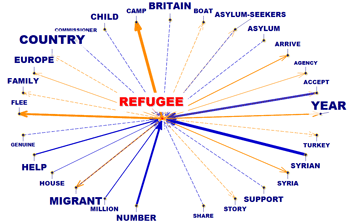
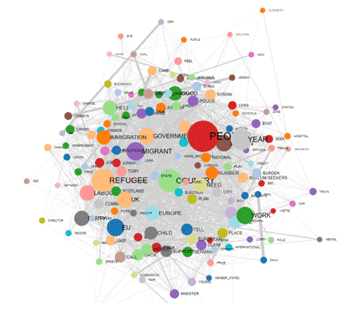
Esta herramienta de T-LAB tiene en cuenta las posiciones de las diferentes unidades lexicales dentro de las frases, permitiendonos así analizar y representar cualquier texto como si fuera una red de relaciones. Una vez implementado este tipo de analisis, el usuario podrá explorar las relaciones que existen entre nodos de la red (esto es, las palabras clave) a diferentes niveles: a) dentro de las relaciones del tipo uno-a-uno; b) dentro de un "ego network"; c) dentro de las comunidades a las que pertenecen; d) dentro de la red formada por el texto analizado.
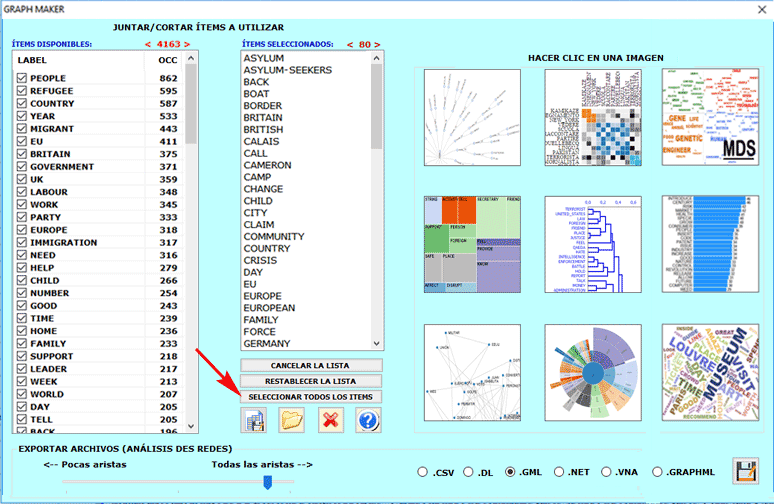
Además, cliqueando en la opción GRAPH MAKER el usuario podrá crear, en todo momento y a partir de los listados personalizados de palabras clave, diferentes tipos de graficos (véase abajo).
B : INSTRUMENTOS PARA ANÁLISIS COMPARATIVOS Estos instrumentos permiten analizar varios tipos de relaciones entre las unidades de contexto.
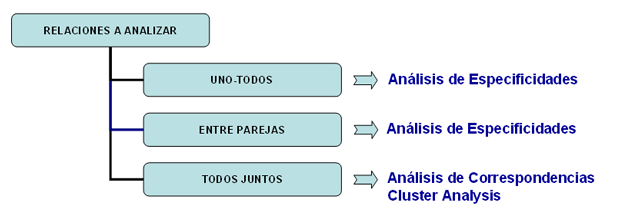
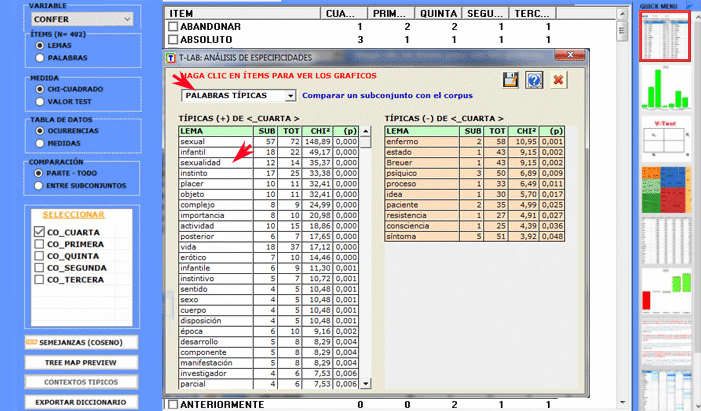
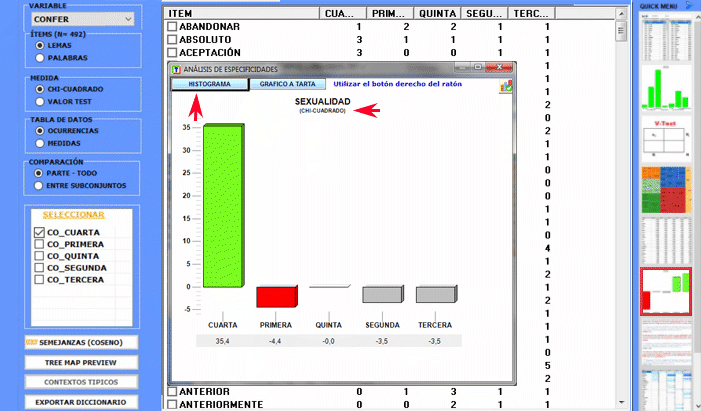
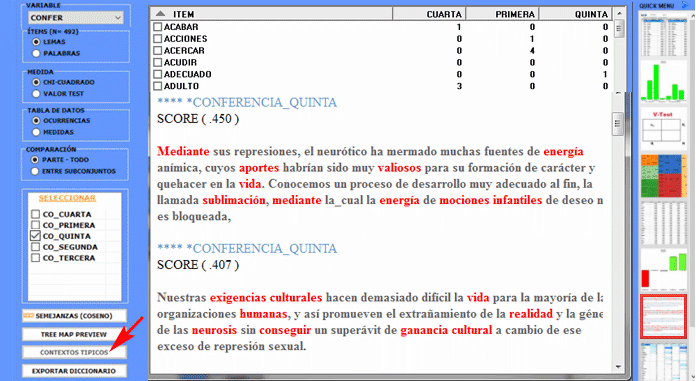
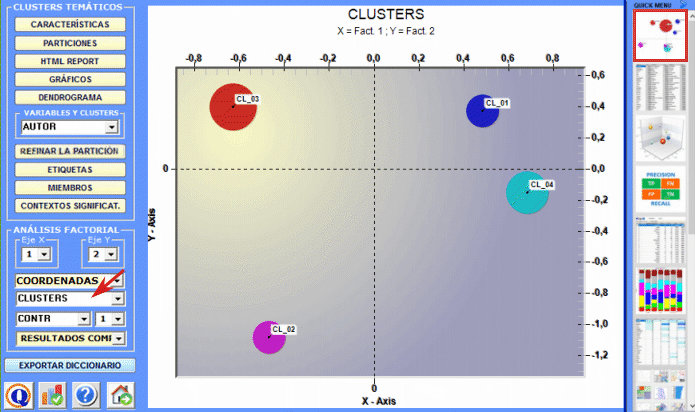
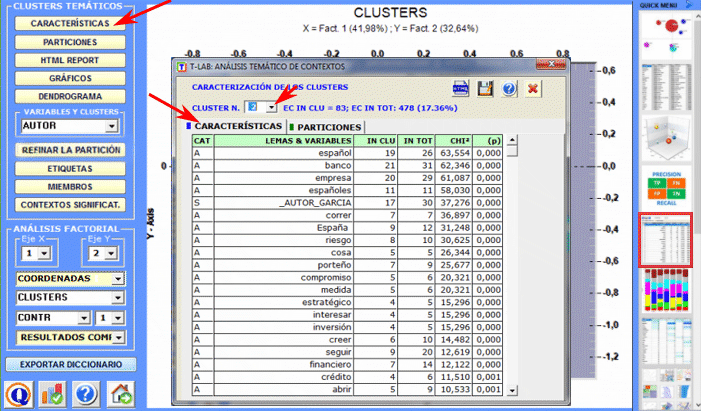
El Análisis de las Especificidades permite verificar cuáles palabras son "típicas" o "exclusivas" de cada subconjunto del corpus. Además, nos permite extraer los contextos típicos, es decir, los contextos elementales característicos, de cada uno de los subconjuntos analizados (p. ej.: las frases 'típicas' utilizadas por los líderes políticos).
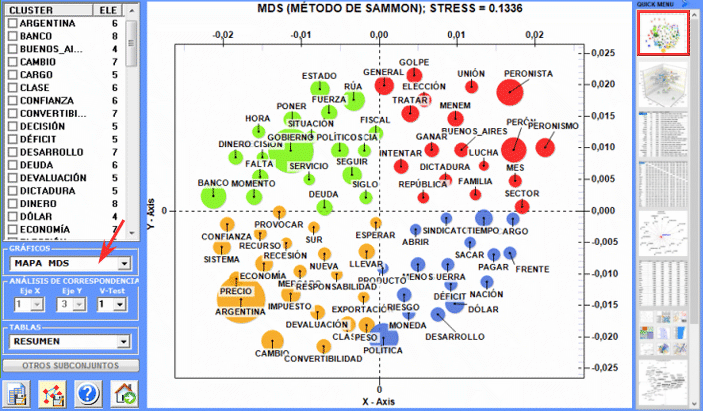
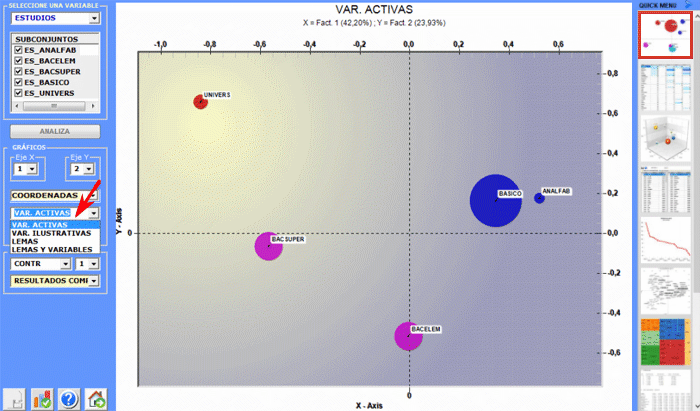
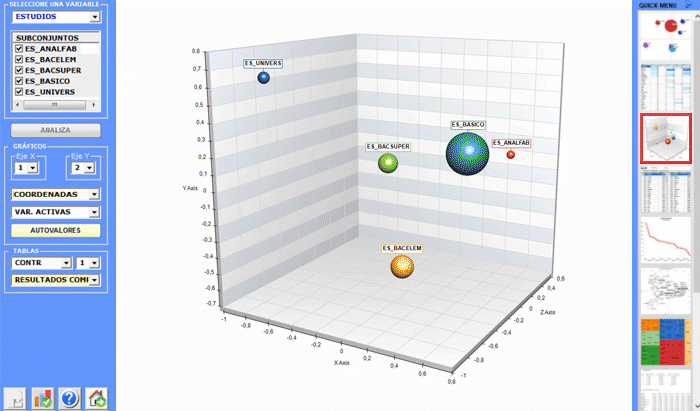
El Análisis de Correspondencias permite explorar varios tipos de relaciones (semejanzas y diferencias) entre grupos de unidades de contexto.
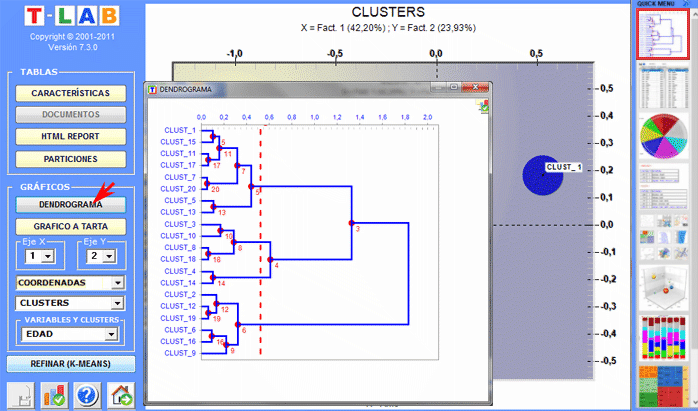
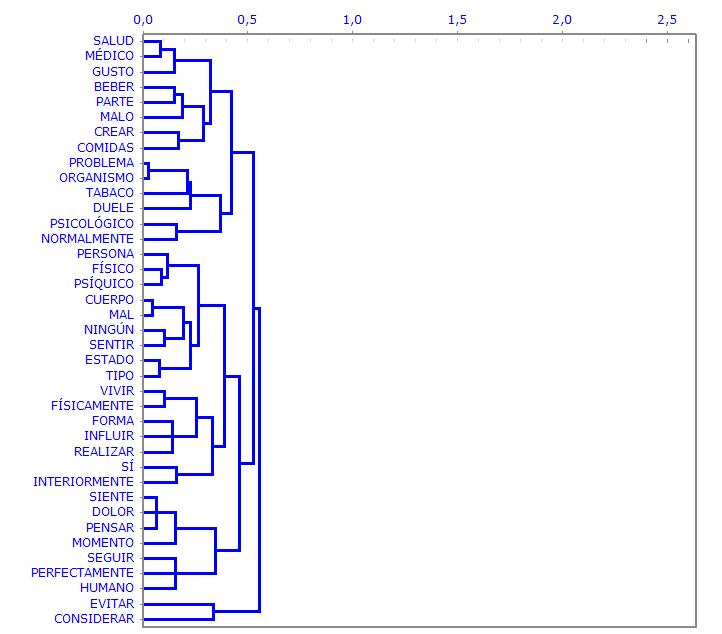
El Cluster Analysis permite encontrar grupos de unidades de texto que presentan dos características complementarias: máxima homogeneidad interna y máxima heterogeneidad entre cada clúster y todos los demás. Se puede implementar recurriendo a múltiples técnicas y requiere, previamente, un análisis de las correspondencias o un SVD.
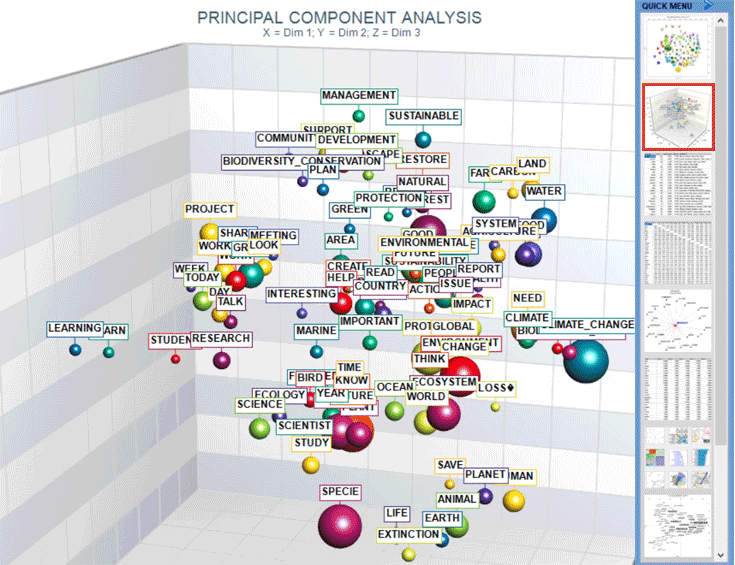
C : INSTRUMENTOS PARA ANÁLISIS TEMÁTICOS Estos instrumentos permiten individuar, examinar y trazar el mapa de los "temas" que emergen de los textos analizados. Puesto que Tema es una
palabra polisémica, cuando se usa software para análisis temático
es útil hacer referencia a algunas definiciones operativas. 1- un clúster temático de unidades de contexto caracterizados por los mismos modelos de palabras clave (ver los instrumentos Análisis Temático de Contextos Elementales y Clasificación Temática de Documentos); 2- un grupo temático de palabras-clave clasificadas en términos de pertenencia a una misma categoría (véase la herramienta Clasificación Basada en Diccionarios); 3- un componente de un modelo probabilista que representa cada unidad de contexto (contextos elementales o documentos) generado de una mezcla de "temas" (ver los instrumentos Modelización de los Temas Emergentes y Textos y Discursos como Sistemas Dinámicos; Por ejemplo, según el tipo de herramienta que estemos utilizando, un documento concreto puede ser analizado bien en términos de co-presencia de varios 'temas' en un único documento (véase 'A' abajo) o bien como parte de un conjunto de documentos que conciernen el mismo 'tema' (véase 'B' abajo). De hecho, en el caso 'A', cada tema puede corresponder a una palabra o frase mientras que, en el caso 'B', un tema puede representar una etiqueta asignada a un conjunto de documentos que presentan los mismos patrones de palabras-clave.
Más en detalle, T-LAB 'extrae' los temas utilizando las siguientes metodologías: 1 - tanto el Análisis Temático de Contextos Elementales como la Clasificación Temática de Documentos funcionan en la siguiente manera: a- realizan un análisis de
co-ocurrencias para obtener los clusters temáticos de
unidades de contexto;
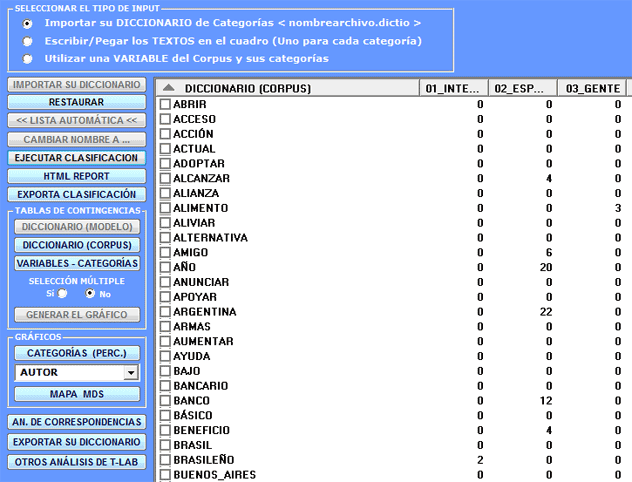
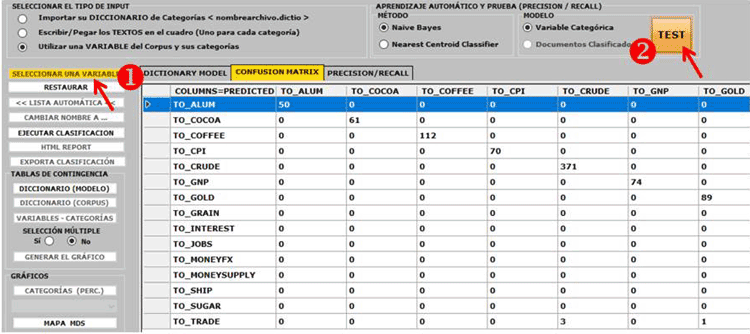
2 - a través de la herramienta Clasificación Basada en Diccionarios, podremos fácilmente construir/testar/aplicar modelos (p. ej.: Diccionarios de categorías) tanto para el análisis de contenido clásico como para el sentiment analysis. De hecho, esta herramienta nos permite implementar una clasificación automática de tipo top-down de las unidades lexicales (es decir, palabras y lemas) y también de las unidades de contexto (es decir, frases, párrafos y pequeños documentos).
3 - Mediante la herramienta Modelización de los Temas Emergentes (véase abajo), los componentes de la 'mixtura' temática pueden ser descritos a través de su vocabulario característico y pueden ser utilizados para construir tablas para el análisis cualitativo y/o para la clasificación automática de las unidades de contexto (es decir, contextos elementales o documentos).
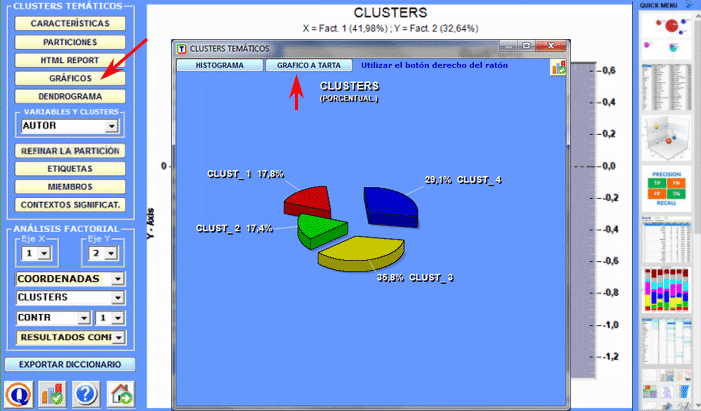
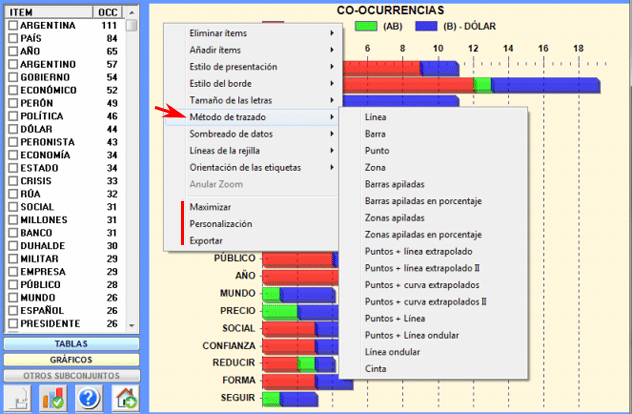
6 - LA INTERPRETACIÓN DE LOS OUTPUT consiste en la consulta de las tablas y de los gráficos producidos por T-LAB, en la eventual personalización de su formato y en el hacer inferencias sobre el significado de las relaciones en los mismos representados. En el caso de las tablas, según los casos, T-LAB permite exportarlas en filas con las siguientes extensiones: .DAT, .TXT, .CSV, .XLXS, .HTML. Esto significa que, utilizando cualquier editor de textos y/o de cualquier aplicativo de la suite Microsoft Office, el usuario puede, fácilmente, importarlos y reelaborarlos. Todos los gráficos y tablas
pueden ser maximizados (hacer clic con el botón izquierdo y
arrastre), personalizados y exportados en diferentes formatos
(hacer clic con el botón derecho del ratón para ver los pop up
menús).
En un paper citado en Bibliografía (Lancia F.: 2007) y disponible en el sitio www.tlab.it se mencionan algunos criterios generales para la interpretación de los outputs T-LAB. En el mismo se propone la hipótesis que los output de las elaboraciones estadísticas (tablas y gráficos) son un tipo particular de textos, es decir son objetos multi-semióticos caracterizados por el hecho que las relaciones entre los signos y los símbolos están ordenadas por medidas que redireccionan a códigos específicos. En otros términos, tanto en el caso de textos escritos en lenguaje natural como en los escritos en el lenguaje de la estadística, la posibilidad de hacer inferencias sobre las relaciones que organizan las formas del contenido está garantizada por el hecho de que las relaciones entre las formas de la expresión no son casuales (random); de hecho, en el primer caso (lenguaje natural) las unidades significantes se subsiguen ordenadas según un modo lineal (una tras otra en la cadena del discurso), mientras que en el segundo caso (tablas y gráficos) los principios de ordenación están constituidos por las medidas que determinan la organización de los espacios semánticos multidimensionales. Si bien los espacios semánticos representados en los mapas T-LAB son muy variados y cada uno de esos requiere procedimientos de interpretación específicos, se puede suponer que - en general - la lógica del proceso inferencial es la siguiente: A - sacar
cualquier relación significativa entre las unidades "presentes" en
el plano de la expresión (por ej. entre "datos" de tablas y/o entre
"etiquetas" de gráficos);
|