|
www.tlab.it
Segmentación de
Palabras
Esta herramienta de T-LAB puede ser utilizada previamente a la
importación de cualquier texto escrito tanto tanto en chino como en japonés
(*). Todo ello, siempre y cuando el texto en cuestión no presente
delimitadores entre palabras (esto es, espacios y/o signos de
puntuación).
(*) El texto a procesar puede estar compuesto bien por un unico
documento o bien por un conjunto de documentos que incluyen
variables categoriales.
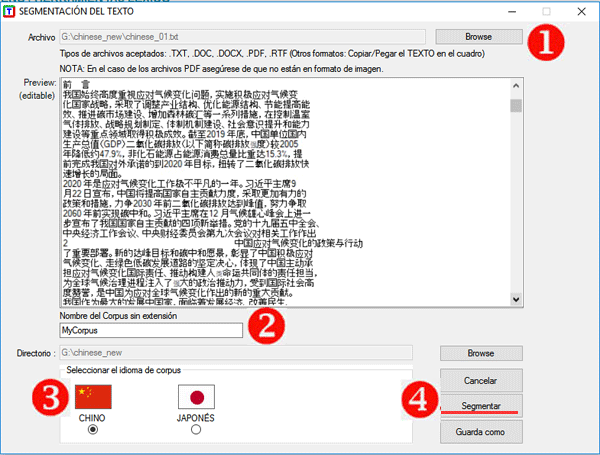
Su uso es muy sencillo y se articula
en 4 pasos (véase imagen abajo):
(1) seleccionar un archivo;
(2) escoger el nombre del proyecto;
(3) seleccionar la lengua del texto;
(4) seleccionar la opción 'Segmentar'.
Al final del proceso, el software habrá añadido espacios entre
palabras.
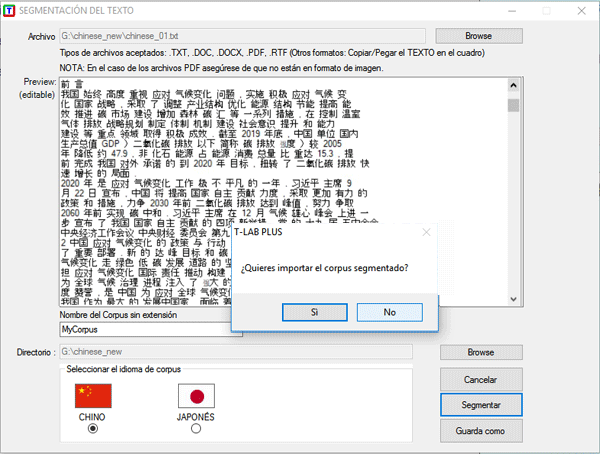
En el caso de que, sucesivamente, se
quiera proceder con la importación, será suficiente contestar 'Sí'
a la pregunta "quieres importar el corpus segmentado?" (véase
imagen abajo).
NOTA: En el caso de querer preparar
un corpus compuesto por diferentes textos que incluyan líneas de
codificación (esto es, variables categoriales), se aconseja
proceder de la siguiente forma:
1- ‘Fusionar’ los textos no segmentados (*) mediante la herramienta
Corpus Builder y, sucesivamente, guardar
el archivo 'corpus';
2 - Importar el corpus recién creado mediante la herramienta
Segmentación de Palabras.Luego, proceder según las
indicaciones expuestas anteriormente.
(*) Lo cual implica que, a la hora de preparar el corpus, no es
necesario segmentar previamente cada uno de los
archivos.
|


