|
www.tlab.it
Asociaciones de
Palabras
 NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. Además: a) hay una nueva opción que permite al
usuario trazar un Mapa MDS con las
palabras más relevantes; b) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; c) cliqueando con el
botón derecho del ratón sobre las tablas que incluyen las palabras
clave se accede al listado de las opciones avanzadas. Por ejemplo,
al seleccionar la opción 'muestra elementos del ítem seleccionado'
es posible visualizar las concordancias a ello asociadas con un
simple clic del ratón; d) una galería de imágenes de acceso rápido
que funciona como un menú adicional permite cambiar entre varias
salidas con un solo clic.
NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. Además: a) hay una nueva opción que permite al
usuario trazar un Mapa MDS con las
palabras más relevantes; b) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; c) cliqueando con el
botón derecho del ratón sobre las tablas que incluyen las palabras
clave se accede al listado de las opciones avanzadas. Por ejemplo,
al seleccionar la opción 'muestra elementos del ítem seleccionado'
es posible visualizar las concordancias a ello asociadas con un
simple clic del ratón; d) una galería de imágenes de acceso rápido
que funciona como un menú adicional permite cambiar entre varias
salidas con un solo clic.
Algunas de estas nuevas características se destacan en la imagen de
abajo
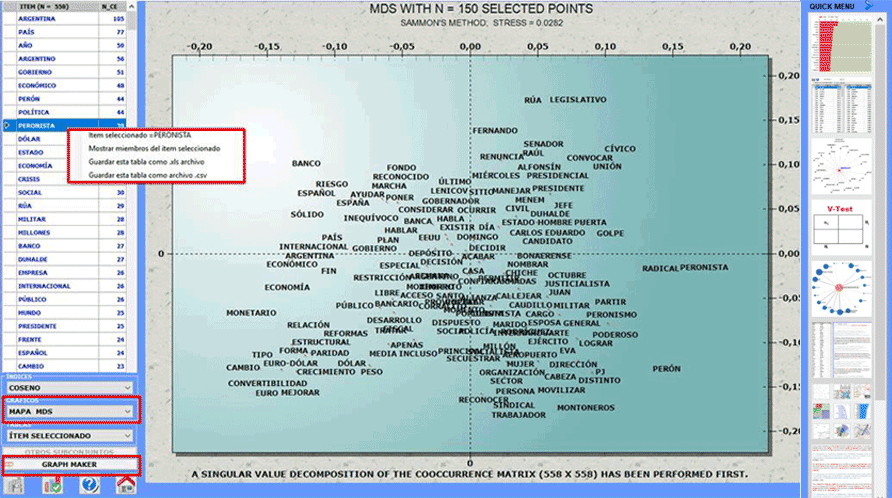
Esta herramienta de T-LAB permite
comprobar las relaciones de co-ocurrencia
y de semejanza que, dentro del corpus
o de sus sub-conjuntos, determinan el significado local de las
palabras clave seleccionadas por el usuario.
Dicha comprobación puede hacerse mediante las
opciones predeterminadas (A) o
mediante las opciones personalizadas
por el usuario (B).
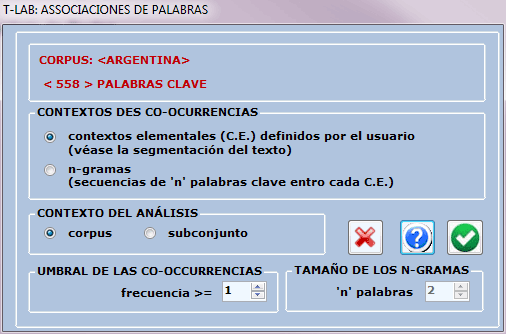
En el primer caso (A: opciones predeterminadas) las
co-ocurrencias de las palabras se calculan dentro de los contextos elementales seleccionados durante la
importación del corpus (ejemplo: frases, fragmentos, párrafos,
etc.). En el segundo caso (B: opciones personalizadas), las
co-ocurrencias pueden ser calculadas también dentro de las
secuencias de palabras que presentan longitud variable (es decir,
los n-gramas, véase sección del glosario
correspondiente). En este último caso, también es posible decidir
el umbral mínimo (es decir, la frecuencia) a partir del cual
considerar las co-ocurrencias.
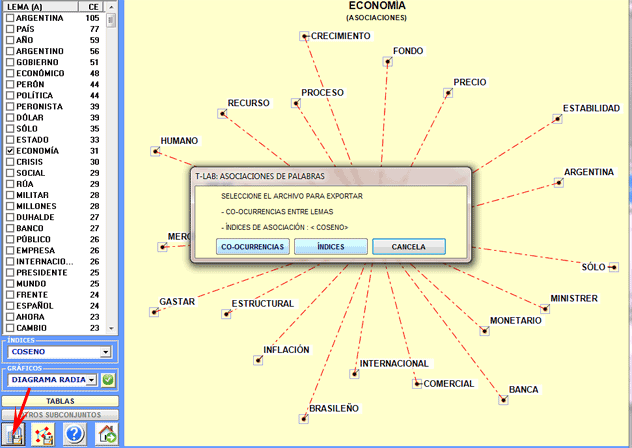
Una vez calculadas las co-ocurrencias entre todas las
palabras escogidas por el usuario aparece la ventana de trabajo
(véase abajo).
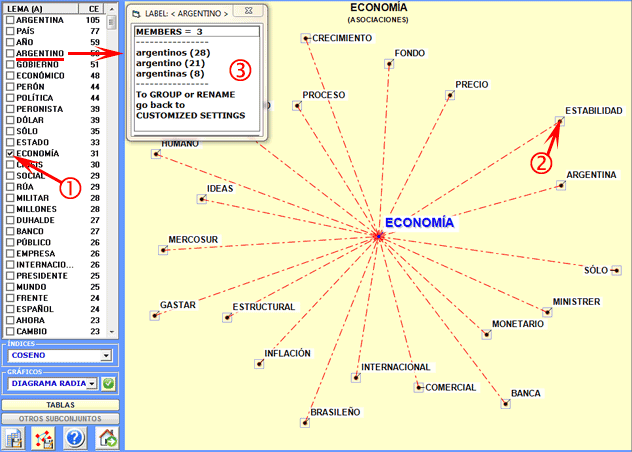
En la parte izquierda de la ventana se ubica una
tabla. Dicha tabla contiene las palabras y los valores numéricos
que indican la cantidad de contextos elementales o de n-gramas en
los que aparecen dichas palabras.
Simplemente con cliquear en los ítems de la tabla
(véase arriba, opción 1) o en los puntos de los gráficos (opción
2), se hace posible comprobar las asociaciones de cada una de las
palabras objetivo. Por otra parte, si se cliquea en las etiquetas
incluidas en la tabla (opción 3), es posible verificar los ítems
incluidos en cada lema.
En cada paso, la selección de las palabras asociadas se realiza
bien calculando un Índice de Asociación
(véase el glosario en la sección correspondiente) o bien utilizando
un índice de semejanza de segundo
orden. En el primer caso, hay seis índices a disposición
(Coseno, Dice, Jaccard, Equivalencia, Inclusión y Información
Mutua), cuyo calculo es de rápida ejecución. Sin embargo, en el
caso de los índices de segundo orden, el análisis puede tardar
algunos minutos, especialmente si el corpus tiene una extensión
elevada. Además, es importante considerar que, en el caso de los
índices de segundo orden, la fiabilidad de los resultados aumenta
al aumentar las palabras incluidas en la lista.
Para cada pregunta, T-LAB produce
gráficos y tablas.
Tanto las tablas como los gráficos pueden ser guardados utilizando
los apropiados botones.
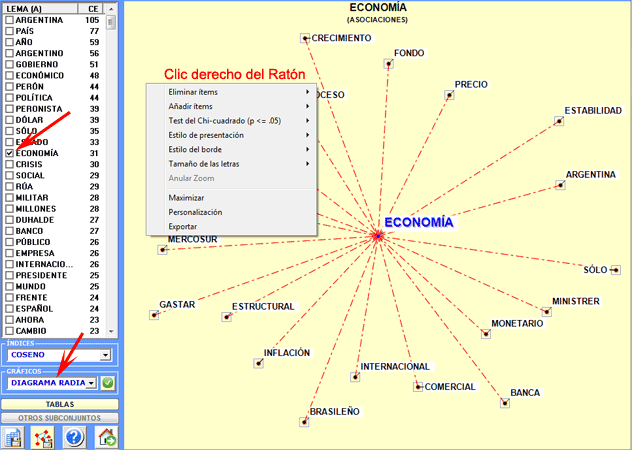
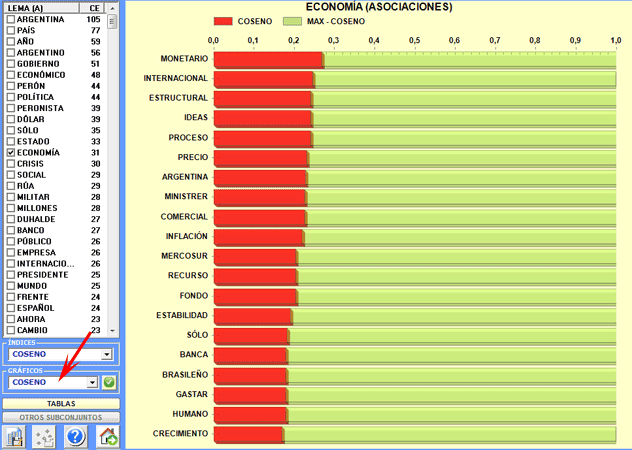
En el diagrama radial
(véase abajo), el lema
seleccionado está en el centro. Los otros se distribuyen alrededor
de él, cada uno a una distancia proporcional a su grado de
asociación. Por tanto, las relaciones significativas son del tipo
uno a uno, entre el lema central y cada uno de los otros.
NOTA: Cada clic en un punto produce un nuevo
gráfico y, usando el botón derecho del ratón, es posible abrir una
caja de diálogo que permite varias personalizaciones.
Las tablas contienen
datos que permiten verificar las relaciones entre ocurrencias y
co-ocurrencias de las palabras que presentan la asociación más
fuerte con aquella seleccionada (máximo 50).
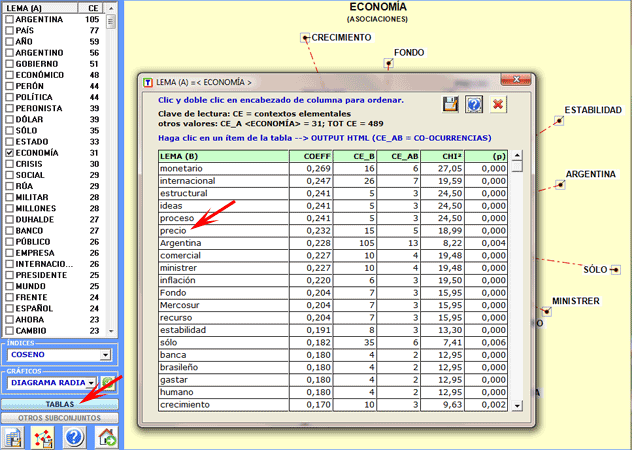
Las llaves de lectura son las
siguientes:
- LEMA (A) = lema seleccionado;
- LEMA (B) = lemas asociados al LEMA (A);
- COEFF = valor del índice de asociación
seleccionado;
- TOT CE = total de los contextos elementales (CE) o de los
n-gramas analizados;
- CE_A = total de los CE en los que está presente el lema
seleccionado (A);
- CE_B = total de los CE en los que está presente cada lema
asociado (B);
- CE_AB = total de los CE en los que los lema "A" e "B"
están asociados (co-ocurrencias);
- CHI2 = valor del chi cuadrado para verificar la
significación de las co-ocurrencias;
- (p) = probabilidad asociada a cada valor del chi-cuadrado
(def=1).
En el caso del chi cuadrado, para
cada pareja de lemas ("A" y B") la estructura de la tabla analizada
es la siguiente:
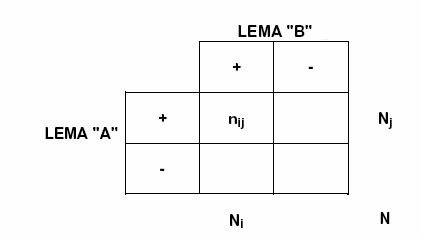
En la que : nij = CE_AB ; Nj = CE_A
; Ni = CE_B ; N = TOT CE.
Un clic en cada etiqueta (ej. "precio") de la tabla
permite de guardar un archivo con todos los contextos elementales donde empareja con la
palabra seleccionada (ej. co-ocurrencias de "economía" y "
precio").

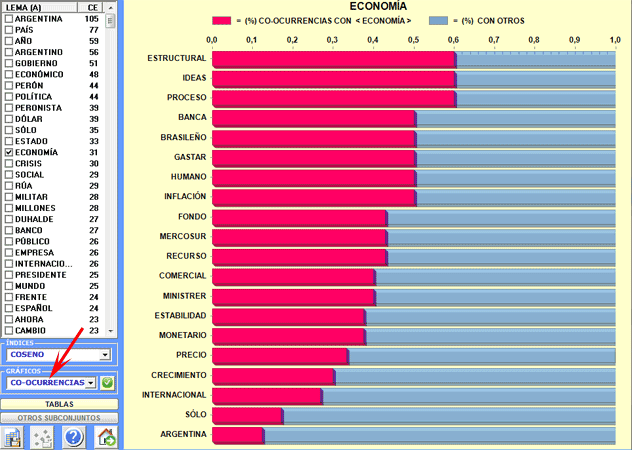
Ulteriores gráficos (Histogramas) permiten apreciar
los valores del coeficiente utilizado y los porcentajes de
co-ocurrencias (véase abajo).
Haciendo clic en el botón de abajo a la izquierda,
el usuario puede exportar diferentes tipologías de tablas (véase
imagen siguiente).
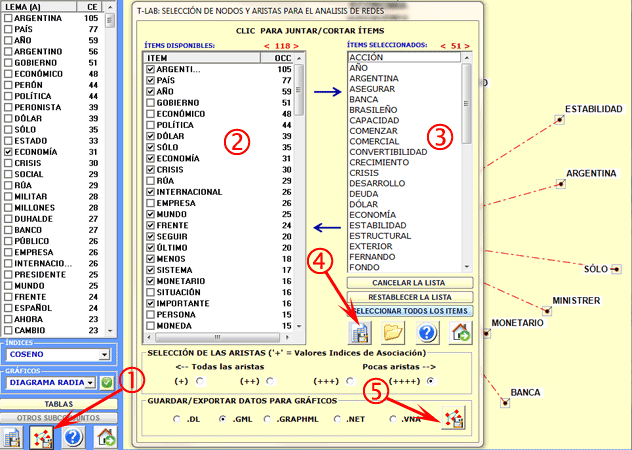
Otra ventana de T-LAB (véase
imagen siguiente, paso 1) permite crear archivos gráficos que se
pueden editar mediante los softwares para el network analysis, como
Gephi, Pajek, Ucinet, yEd y otros. En este caso, los nudos de la
red están formados por las palabras asociadas con la palabra
objetivo. Las tres opciones disponibles son: seleccionar los ítems
(es decir, los nudos) a insertar en los gráficos (véase abajo,
pasos 2 y 3), exportar la matriz de adyacencia correspondiente
(véase abajo, paso 4), exportar el tipo de archivo grafico
seleccionado (véase abajo, paso 5).
NOTA: En T-LAB 10
la ventana que se muestra a continuación ha sido sustituida por la
herramienta Graph Maker.
Por ejemplo, los archivos en formato .GML
exportados por T-LAB
permiten realizar gráficos como los siguientes.
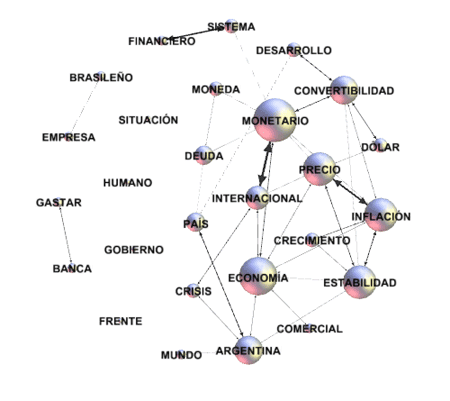
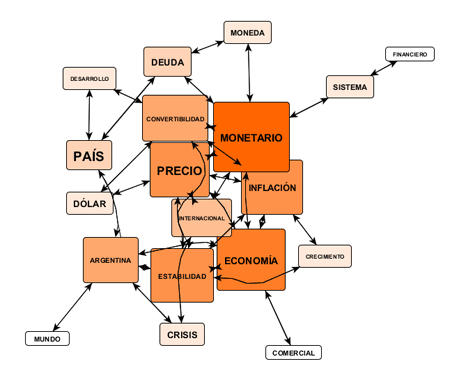
N.B.: El primero de los gráficos se ha creado por
medio de Gephi (https://gephi.org/ ), el segundo por medio
de yEd (http://www.yworks.com/en/products_yed_download.html/
), ambos softwares disponibles como descarga gratuita.
Las modalidades de cálculo de los diferentes
índices de asociación (o proximidad)
están indicadas en la sección correspondiente del Manual/Aiuda
(véase glosario). Tal y como se podrá observar, todos estos índices
se obtienen mediante una normalización de los valores de
co-ocurrencia vinculados a las parejas de palabras.
Consecuentemente, en los cálculos de primer
orden, dos palabras que no co-ocurren obtendrían un índice
de asociación igual a '0'. Sin embargo, los índices de segundo orden evidencian fenómenos de semejanza
relacionados con el uso (y, por ende, con el significado) de las
palabras que no dependen directamente de sus co-ocurrencias. De
hecho, en este caso, dos palabras que no co-ocurren pueden llegar a
tener un índice de asociación muy elevado.
Utilizando algunos conceptos de la Lingüística Estructural, podemos
afirmar que, mientras los índices de 'primer orden' permiten
destacar fenómenos asociados al eje sintagmático (combinación y
proximidad 'in praesentia', es decir, palabras que dentro de una
frase concreta están 'una al lado de la otra'), los índices de
'segundo orden' destacan fenómenos vinculados al eje paradigmático
(asociación y semejanza 'in absentia', es decir relaciones de
casi-sinonimia entre dos o más términos usados por el mismo
autor).
Para comprender la manera con la que T-LAB calcula
los índices de 'segundo orden' es útil recordar que los índices de
'primer orden' pueden usarse para construir matrices de proximidad
como la siguiente (A).
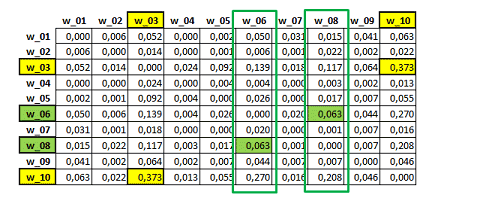
Matriz 'A': semejanza de primer orden.
En esta matriz simétrica (A), el valor 0.373 (en
amarillo) coincide con el índice de 'primer orden' más alto, e
indica la asociación entre las palabras 'w_03' y 'w_10'. Más en
concreto, se trata de un índice de equivalencia obtenido dividendo
el cuadrado de sus co-ocurrencias entre el producto de sus
ocurrencias (360^2/627*553).
A partir de la matriz recién descrita (A), T-LAB
construye una segunda matriz (B). Para ello, se calculan los
cosenos de las comparaciones entre todas las columnas que incluyen
los índices de 'primer orden' (véase matriz A). Observando la tabla
'B', es posible constatar cómo el valor de 'semejanza' más elevado
es aquel que caracteriza la relación entre las palabras 'w_06' e
'w_08'. Esto quiere decir que los vectores correspondientes (véanse
las dos columnas en verde de la matriz 'A') son muy parecidos entre
sí (coseno = 0.905), pese a que la asociación de 'primer orden'
entre las dos palabras en cuestión es bastante baja
(0.063).
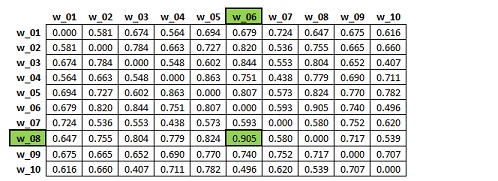
Matriz 'B': semejanza de segundo orden.
Dicho de otro modo, un índice de primer orden se obtiene a partir de una fórmula
que incluye valores de co-ocurrencia y ocurrencia, mientras que un
índice de segundo orden se obtiene
multiplicando dos vectores normalizados.
Más allá de las modalidades de cálculo, cabe recordar que en los
dos casos ('A' e 'B') subyacen dos fenómenos distintos. En el
primer caso ('A') nos centramos en las co-ocurrencias mientras que,
en el segundo caso ('B'), y independientemente de las
co-ocurrencias, nos centramos en la semejanza entre 'perfiles'
cuyos datos hacen referencia al uso de palabras por parte de los
autores de los textos analizados.
A modo de ejemplo, se considera el análisis de primer orden de
Pinocho, donde el término 'hada' está principalmente asociado
(véanse co-ocurrencias) con 'buena' y 'pelo turquesa'. Sin embargo,
en el análisis de segundo orden el término que resulta ser más
parecido a 'hada' es 'mamá'. Todo ello, pese a que las
co-ocurrencias entre los términos 'hada' y 'mamá' son, dentro del
cuento de Collodi, prácticamente irrelevantes (sólo 3).
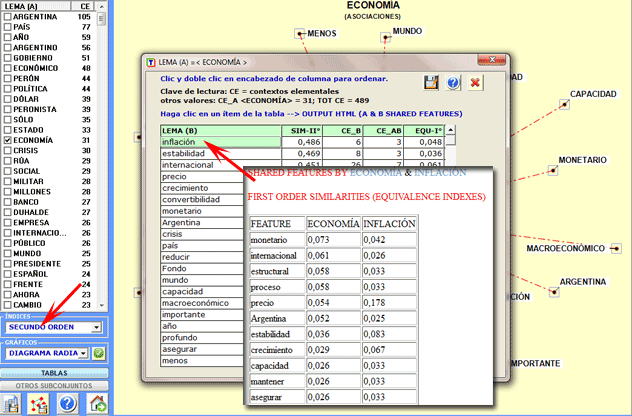
Las tablas visualizadas por T-LAB permiten
verificar tanto las semejanzas de segundo orden (véase abajo
columna SIM-II°), como los índices de primer orden (EQU-I°, es
decir, índices de equivalencia).
Además, cliqueando en cada ítem de esta tabla, es posible abrir
unos archivos HTML que permiten verificar qué características
('features') determinan las semejanzas de segundo orden entre cada
pareja de palabras. Por ejemplo, en la siguiente tabla se observa
como la semejanza de segundo orden entre 'economia' y 'inflación'
está determinada principalmente por características compartidas
como 'monetario', 'internacional', 'estructural', etc..
|


