|
www.tlab.it
Lematización
En los diccionarios lingüísticos que consultamos, cada
entrada corresponde a un lema que -
generalmente - define un conjunto de palabras con la misma raíz
lexical (el lexema) y que pertenece a la misma categoría gramatical
(verbo, adjetivo, etc.).
En general, la lematización
exige que las formas del verbo se pongan en infinitivo, los
sustantivos en singular, etcétera.
Por ejemplo, las formas
flexivas "hablan" y " hablando ", que resultan de la
combinación de una raíz única con dos
diversos sufijos (< - an > y < - ando >), se remiten al
mismo lema "habl-ar". Sin embargo, hay algunos casos en los que la
lematización no observa la regla de la raíz común; especialmente en
los verbos irregulares.
Durante la fase de importación del corpus, T-LAB consiente hacer un tipo
específico de lematización automática que sigue la lógica del árbol
siguiente .
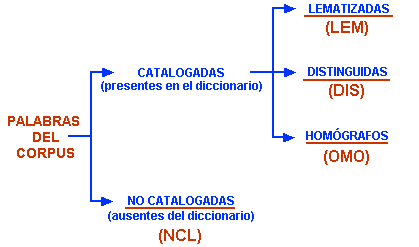
Obviamente, el diccionario de referencia es el que ha
sido realizado en T-LAB.
Las abreviaturas de las cuatro-categorías se utilizan en
muchas tablas, siempre en la columna "INF".
NOTA:
- la categoría "DIS " ("distinguir") significa que T-LAB no aplica la lematización estándar, para no
anular las diferencias de significado entre las diversas
palabras;
- a veces, para diferenciar homógrafos, T-LAB añade el carácter '_' (underscore) a su
lema.
|


