|
www.tlab.it
Preparar un Corpus (Corpus
Builder)
 NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. Además, esta herramienta incluye dos ulteriores
botones: a) uno para activar la opción Text Screening, en el caso de que el corpus
no supere los 20 MB, y b) otro que permite la importación inmediata de los materiales textuales
(véase imagen siguiente).
NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. Además, esta herramienta incluye dos ulteriores
botones: a) uno para activar la opción Text Screening, en el caso de que el corpus
no supere los 20 MB, y b) otro que permite la importación inmediata de los materiales textuales
(véase imagen siguiente).

Esta herramienta ha sido diseñada para facilitar tanto la
preparación de diferentes materiales textuales, como su
transformación en un único archivo corpus listo para la importación
en T-LAB.
De forma más concreta, esta herramienta permite ejecutar
rápidamente las siguientes operaciones:
1. Importar automáticamente distintas
tipologías de archivos;
2. Editar y modificar los textos
importados;
3. Gestionar el uso de variables
categóricas;
4. Guardar el resultado de un trabajo
en un archivo que pueda ser directamente importado por
T-LAB;
5. Verificar y modificar cualquier archivo corpus cuyo formato
sea compatible con T-LAB.
Si bien la manera de importar los archivos (véase arriba
'1') varia en base a los formatos que estos tengan, todas las demás
operaciones siguen el mismo procedimiento.
A continuación, se propone una breve descripción de las
maneras de importar las diferentes tipologías de
archivos.
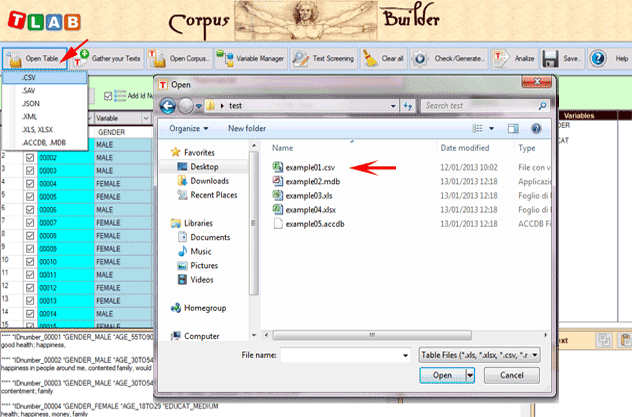
A - Importar un archivo en
formato de tabla (CSV, .SAV, .JSON, .XML, .XLS, XLSX,
.MDB, .ACCDB)
Para importar un único
archivo que incluya hasta 30.000 entradas se puede utilizar
tanto la opción 'Open Table' como el método drag and drop (NB:
cuando ningún texto supera los 2.000 caracteres, se extiende a
99.999 el número máximo de entradas que se pueden importar).
Dicho archivo puede estar compuesto por diferentes
columnas. Éstas pueden contener diferentes tipologías de datos:
- Variables categoriales (una por cada
columna, hasta un máximo de 50)
- Textos a analizar (sólo una
columna)
- IDnumbers. Es decir, identificativos
de unidades de contexto o sujetos/casos.
N.B.: La presencia de variables categóricas e IDnumbers
es opcional. Sin embargo, la presencia de por lo menos una columna
de texto es obligatoria.
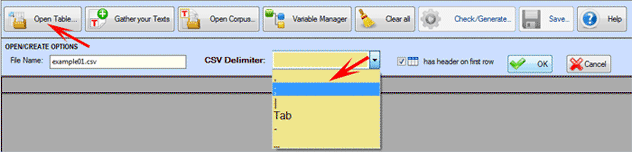
A la hora de importar un archivo en formato .CSV, es
necesario seleccionar de forma apropiada el delimitador a usar
(véase abajo).
Cuando se importan archivos Excel o Access, sólo se puede
seleccionar una tabla (véase abajo).

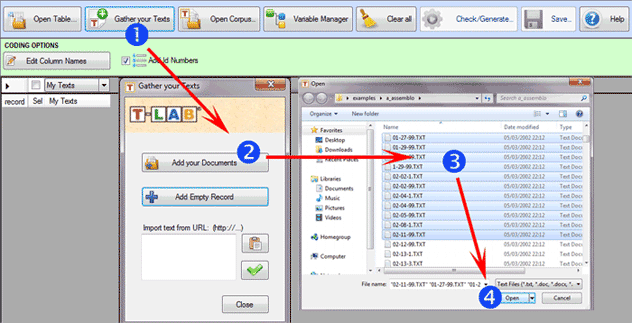
B - Importación de textos y
documentos (.TXT, .DOC, .DOCX, .PDF, .RTF, .HTML)
La opción 'Gather your Texts' (véase abajo) permite
importar hasta un máximo de 30.000 documentos, bien de forma
individual, bien mediante selección múltiple. Todo ello, mediante
3 posibles
procedimientos.
El primer procedimiento
('Add your Documents') prevé la importación automática de archivos
.TXT, .DOC, .DOCX, .PDF, .RTF.
El segundo procedimiento
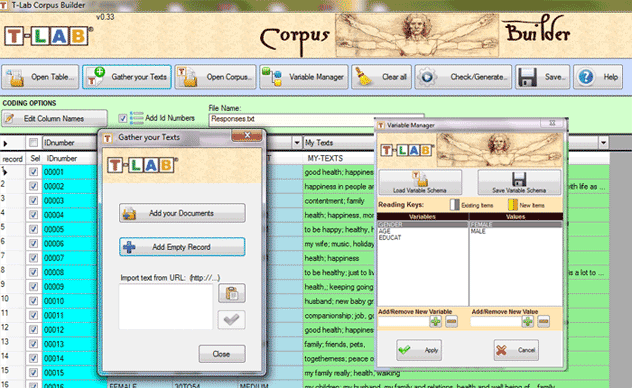
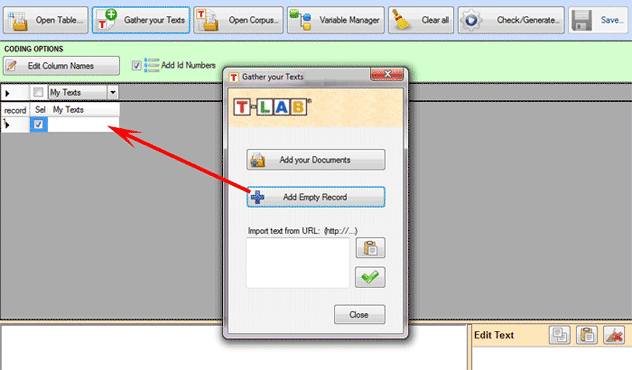
('Add EmptyRecord') permite importar records de forma individual.
En cada uno de ellos es posible copiar/pegar cualquier tipología de
texto (véase abajo).
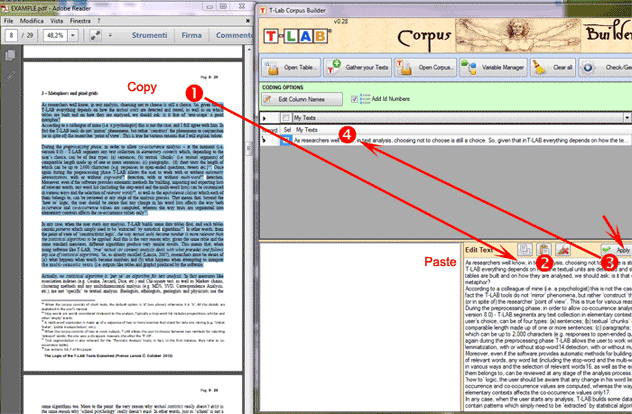
El tercer procedimiento
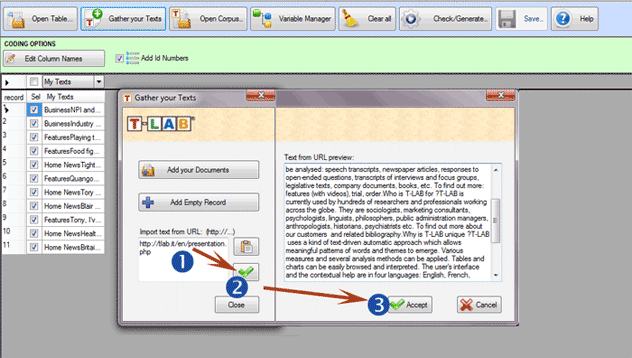
('Import Text from URL') permite descargar archivos HTML
directamente desde Internet. A la vez, permite editar el contenido
de estos archivos y, consecuentemente, importarlos a
T-LAB.
C - Importación de un
corpus ya codificado según los criterios de
compatibilidad con T-LAB.
El uso de la opción 'Open Corpus' está especialmente
pensado para los siguientes casos:
1 - Si el usuario quiere modificar la estructura de un
archivo corpus ya codificado (eje. Añadir otros textos mediante los
métodos presentados en la anterior sección 'B', modificar los
nombres de las variables, y/o de las modalidades, etc.);
2 - Si el usuario quiere verificar/corregir los eventuales errores
que pueda presentar una codificación del corpus realizada
manualmente (es decir, sin utilizar la herramienta Corpus
Builder);
3 - Si el usuario quiere importar un archivo corpus que tenga una
codificación "bruta" (véase imagen siguiente). Es decir un archivos
cuyas partes (documentos o entradas) están precedidas
exclusivamente de una línea de texto compuesta por 4 asteriscos
seguidos por un espacio ('**** ').

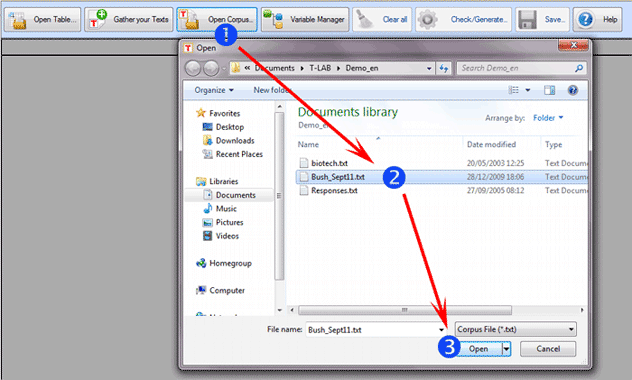
Para implementar cada una de las opciones recién descritas
es suficiente seleccionar un único archivo mediante la opción 'Open
Corpus'. También se puede arrastrar el archivo utilizando el método
drag and drop.
Operaciones posteriores a la
importación del archivo
Una vez finalizada la fase de importación de los archivos
mediante Corpus Builder, es posible escoger la opción 'Check
/Generate' y - sucesivamente - guardar el corpus a importar
T-LAB. Esto, tanto en el caso en que no se quiera utilizar
variables como en el caso en que ya se hayan efectuado las
operaciones de codificación.
Si el corpus contiene codificaciones es importante
acordarse de que, en cada uno de los 3 métodos de importación
descritos anteriormente ('A', 'B', 'C'), los datos se visualizan en
columnas diferentes. Éstas pueden tener distintas etiquetas:
- Variable, es decir
variables categóricas cuyo uso es necesario cuando se quieren
analizar las características de diferentes subconjuntos del corpus
y las relaciones entre dichos subconjuntos;
- IDnumber, es decir,
identificadores de casos/entradas y cuyo uso es opcional;
- My Texts, es decir textos a
analizar y cuyo uso, obligatorio, está vinculado a una única
columna;
- Exclude, se usa para indicar
a Corpus Builder que no se deben utilizar los datos contenidos en
la columna correspondiente.
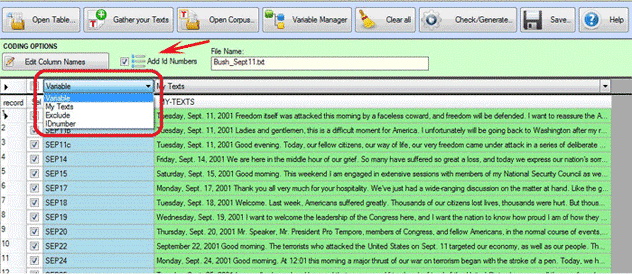
Para todos los casos, valen las siguientes
indicaciones:
- Para cada entrada, existe tanto la posibilidad de seleccionar
como de deseleccionar (véase abajo '1 ');
- Los IDnumber pueden ser añadidos de forma automática (véase abajo
'2');
- Los nombres de las variables pueden ser editados y modificados
(véase abajo '3');
- Cada valor de la variable puede ser editado y modificado (véase
abajo '4');
- Cada campo 'My Texts' puede ser editado y modificado (véase abajo
'5').
.
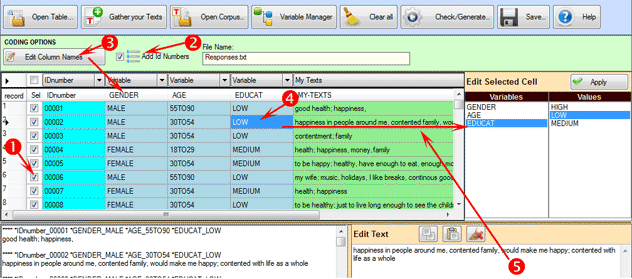
Otros aspectos a tener en cuenta son:
- El número máximo de columnas con variables categóricas es 50.
Además, cada una las variables debe tener un numero de valores
comprendido entre un mínimo de 2 y un máximo de 150;
- En el caso de utilizar los IDnumber, sus valores deben ser
progresivos y empezar por el 1 (eje. 1, 2, 3, etc.);
- Tanto en el caso de las variables como en el de las modalidades,
cada etiqueta debe tener una extensión no superior a los 25
caracteres alfanuméricos (min. 2) y no tener espacios;
- En el modulo Corpus Builder los errores se visualizan en el
cuadro abajo a la izquierda (véase abajo).
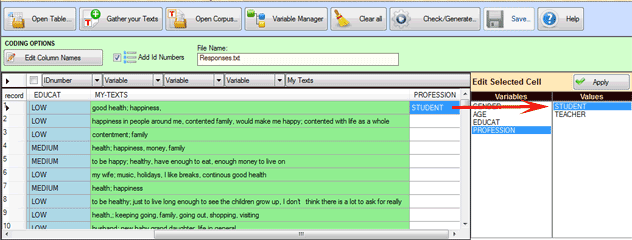
Uso de la herramienta Variable
Manager
La herramienta 'Variable Manager' permite construir, editar,
modificar y guardar cualquier esquema de codificación, incluso
aquellos provenientes de corpus diferentes.
Cada esquema incluye el elenco de las variables y de sus valores
correspondientes (véase abajo).
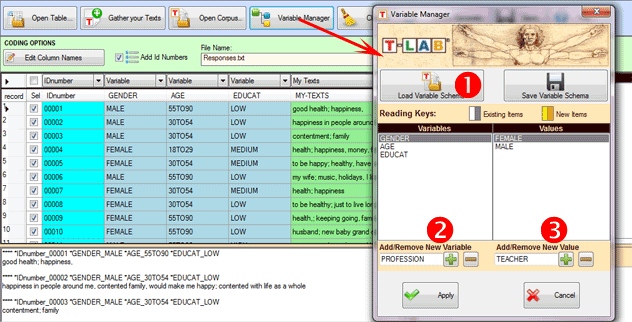
Para añadir las variables de otro corpus o de un esquema
guardado anteriormente, es necesario seleccionar la opción '1'
(véase arriba). Sin embargo, para añadir manualmente las variables
y sus valores, hay que utilizar las opciones '2' y '3'
consecutivamente. (véase arriba).
Para añadir los valores de las variables a las entradas
es necesario proceder manualmente en una única sesión de trabajo
(véase abajo).Esto es así, porque al guardar un esquema no se
incluyen las modificaciones aportadas a cada entrada. De esta
forma, en el caso en que el usuario tenga que codificar manualmente
un corpus que incluya un número considerable de entradas y/o
necesite más de una sesión de trabajo, se aconseja proceder de la
siguiente manera:
1 - Importar todos los archivos/records que se considera
se puedan codificar en una única sesión de trabajo;
2 - guardar el trabajo como corpus (véase opción 'Save' del menú
Corpus Builder).
Después, en la sesión siguiente, reimportar el corpus
anteriormente guardado (véase arriba, punto '2'), y añadir otros
records/archivos y continuar.
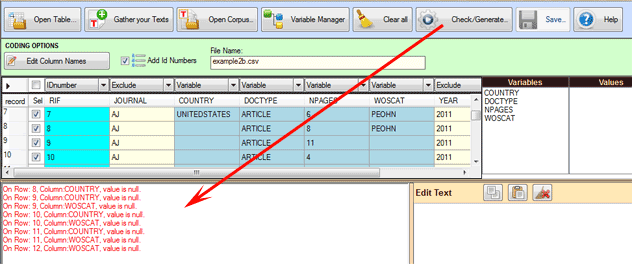
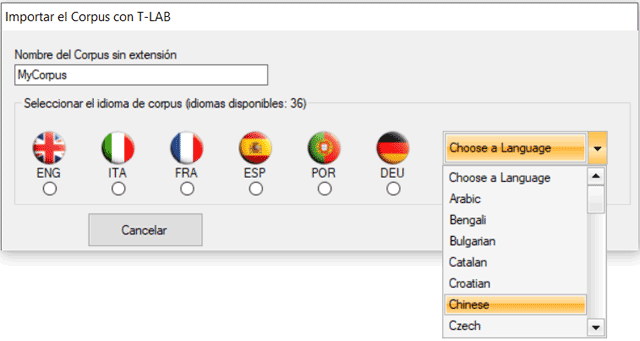
Una vez el usuario haya terminado las operaciones que
considere oportunas, éstas pueden ser chequeadas mediante la opción
'Check/Generate'. Si todo está bien hecho, ya es posible exportar (
A) o guardar (B) un corpus listo para la importación a
T-LAB.
En el primer caso (A - véase abajo), Corpus Builder crea una nueva
carpeta en el directorio ".. \ Mis documentos \ T-LAB PLUS\" y
empieza automáticamente la importación del corpus.
NB: En este caso, la nueva carpeta tiene el mismo nombre del
corpus.
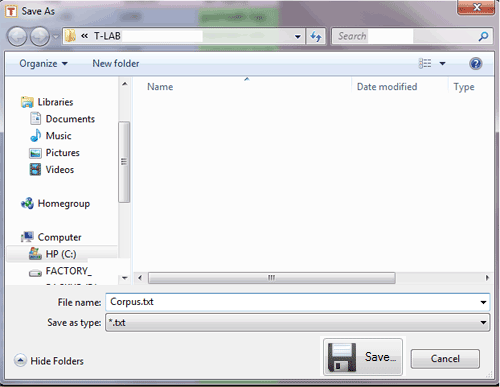
En el segundo caso (B - véase abajo) el usuario puede
guardar su corpus en cualquier carpeta desee. Sucesivamente, tiene
que utilizar la opción de T-LAB "Importar un
corpus".
NB: En este caso, se recomienda crear - todas las veces - una
carpeta de trabajo que contenga sólo el archivo a importar.
.
|


