|
www.tlab.it
Análisis de
Correspondencias
 NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. Además: a) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; b) el uso del
botón derecho del ratón sobre las
tablas que incluyen las palabras clave permite acceder a otras
opciones; c) dos nuevos botones nos permiten verificar las
especificidades de cada valor de variable utilizando la prueba de
chi-cuadrado o el valor test; d) se incluye un botón que permite
implementar un análisis de clúster y que
utiliza las coordenadas de los objetos (unidades lexicales o de
contexto) relativas a los primeros ejes factoriales (hasta un
máximo de 10); e) se pueden visualizar las tablas de contingencia
en modalidad 'head-map'; f) las palabras pueden ser representadas
en los gráficos utilizando un tamaño de letras proporcional a la
cantidad de ocurrencias que las caracterizan; g) una galería de
imágenes de acceso rápido que funciona como un menú adicional
permite cambiar entre varias salidas con un solo clic.
NOTA: Las imagenes contenidas en este apartado hacen referencia a
una versión anterior de T-LAB, ya que el interfaz de T-LAB 10
cambia ligeramente. Además: a) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; b) el uso del
botón derecho del ratón sobre las
tablas que incluyen las palabras clave permite acceder a otras
opciones; c) dos nuevos botones nos permiten verificar las
especificidades de cada valor de variable utilizando la prueba de
chi-cuadrado o el valor test; d) se incluye un botón que permite
implementar un análisis de clúster y que
utiliza las coordenadas de los objetos (unidades lexicales o de
contexto) relativas a los primeros ejes factoriales (hasta un
máximo de 10); e) se pueden visualizar las tablas de contingencia
en modalidad 'head-map'; f) las palabras pueden ser representadas
en los gráficos utilizando un tamaño de letras proporcional a la
cantidad de ocurrencias que las caracterizan; g) una galería de
imágenes de acceso rápido que funciona como un menú adicional
permite cambiar entre varias salidas con un solo clic.
Algunas de estas nuevas características se destacan en la imagen de
abajo.
Esta herramienta de T-LAB tiene
como finalidad la de destacar las semejanzas y diferencias entre unidades del contexto.
En particular, en T-LAB, el
Análisis de Correspondencias permite
analizar tres tipos de tablas:
(A) tablas palabras
por categorías de variables con los
valores de ocurrencias;
(B) tablas contextos elementales por palabras con los
valores de de co-ocurrencias;
(C) tablas documentos por
palabras con los valores de de ocurrencias.
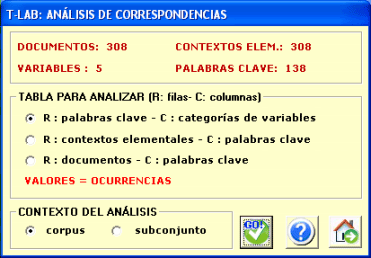
Para analizar las tablas (A) lemas (o palabras) por variables, el
corpus se debe componer de un mínimo de tres textos o debe ser
codificado con algunas variables (no
menos de tres categorías).
Las variables son enumeradas en un box apropiado y pueden
ser usadas de una en una.
Después de cada selección, en secuencia, se muestra la tabla de
contingencia y hay que hacer clic en el botón analiza (véase abajo).
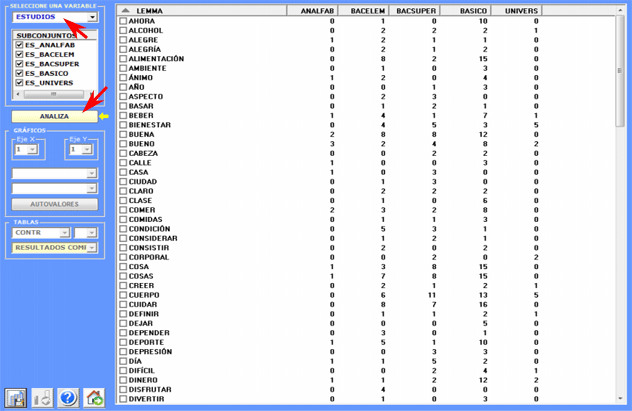
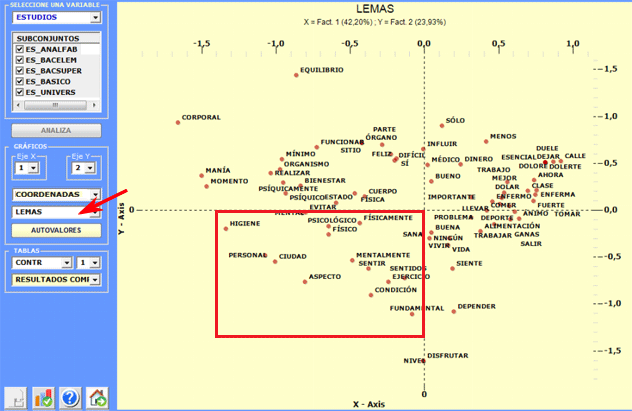
Como resultado del análisis se obtienen tablas, a partir
de las cuales se pueden producir los gráficos que - en planos
cartesianos - muestran las relaciones entre los subconjuntos del
corpus y entre las unidades lexicales (palabras o lemas).
En particular, según los casos, los tipos de gráficos disponibles
muestran las relaciones entre variables
activas, entre variables
ilustrativas, entre lemas o entre lemas y variables.
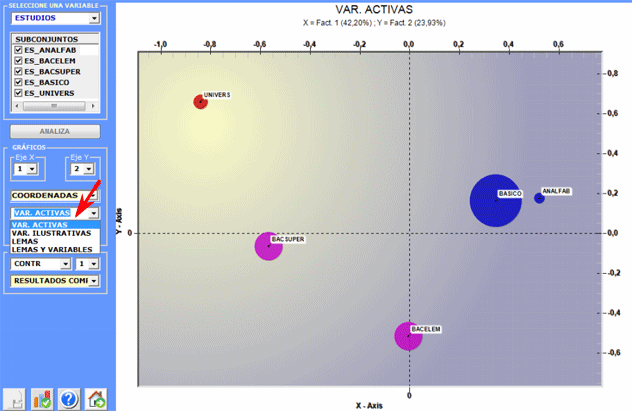
Además, cuando la tabla a analizar es parte de la
tipología "documentos x palabras", es posible visualizar los puntos
(máximo 3000) correspondientes a cada documento.
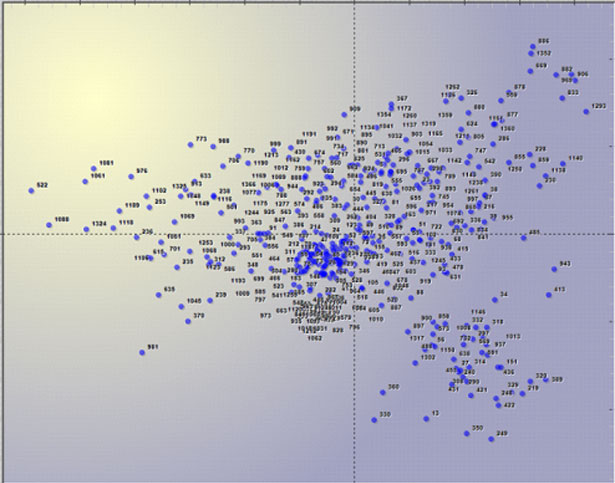
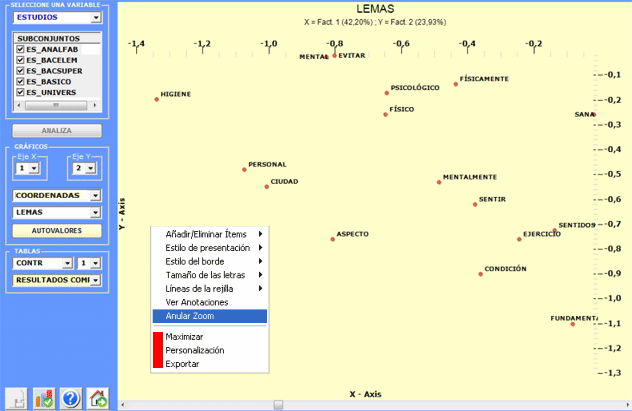
Todos los gráficos pueden ser maximizados y
personalizados usando la caja de diálogo apropiada (botón derecho
del ratón). Por otra parte, cuando las categorías variables son 3 o
más, sus relaciones se pueden explorar en 3D (véase abajo).
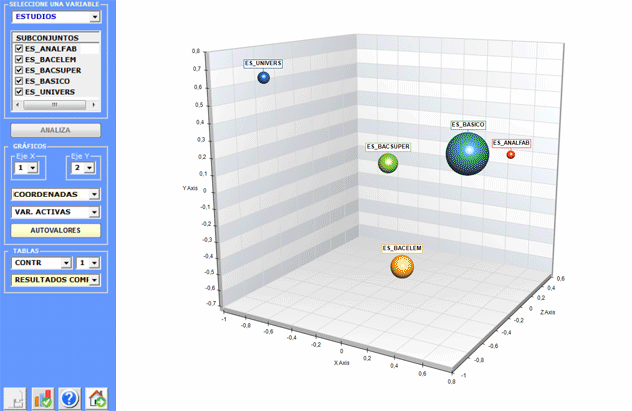
Para explorar las varias combinaciones de los ejes
factoriales, es suficiente seleccionarlos en los boxes apropiados
("Eje X", "Eje Y").
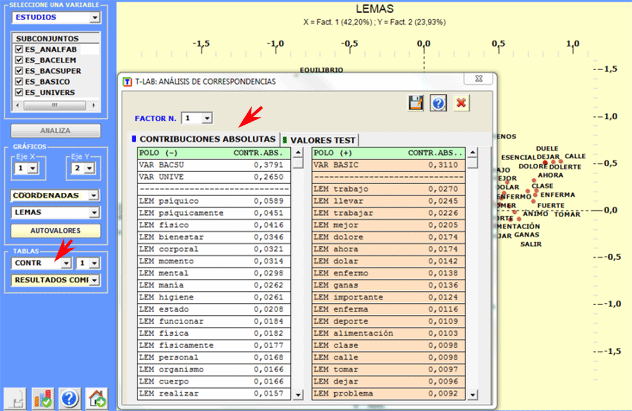
En T-LAB las características de
cada polo factorial (las oposiciones
mostradas en los ejes de los gráficos) se marcan usando dos
medidas: las Contribuciones
Absolutas, cuyo umbral
es 1/N (N = filas de la tabla analizada) y los Valores Test ("Valeur Test"), cuyo umbral es +/-
1.96.
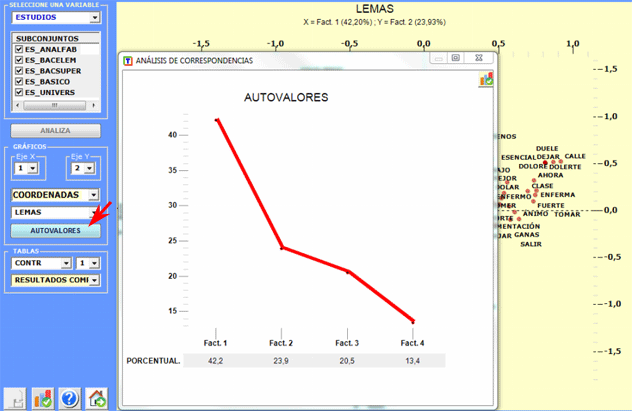
Usando el gráfico "autovalores" es posible apreciar la
importancia relativa de cada factor, es decir el porcentaje de
variancia que explican.
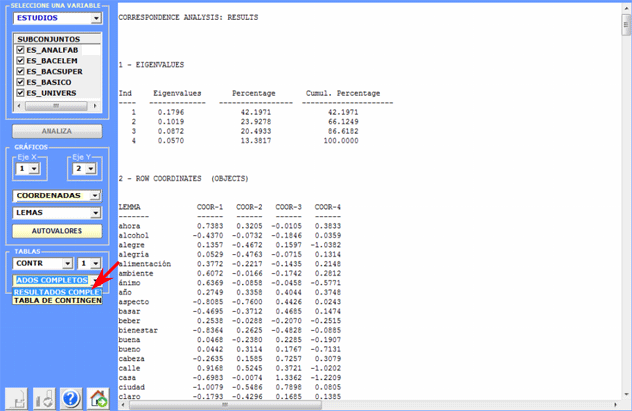
Finalmente, un clic en el botón "Resultados Completos"
permite que usted visione y guarde el archivo que contiene todos
los resultados del análisis: valores propios, coordenadas,
contribuciones absolutas y relativas, valores
test.
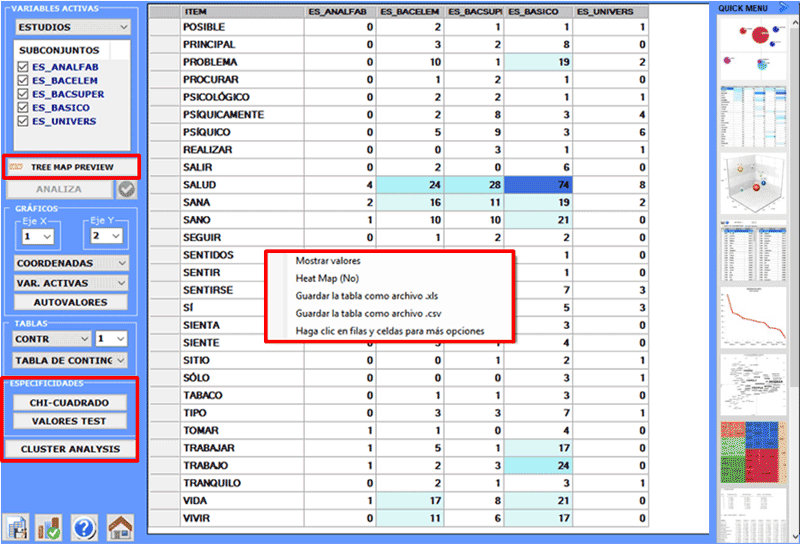
Todas las tablas de contingencia pueden ser fácilmente
exploradas y nos permiten crear varios tipos de gráficos. Además, haciendo clic en específicas
células de la tabla (véase abajo), es posible crear un archivo HTML que incluye todos los contextos
elementales en que la palabra en la fila está presente en el
subconjunto correspondiente.
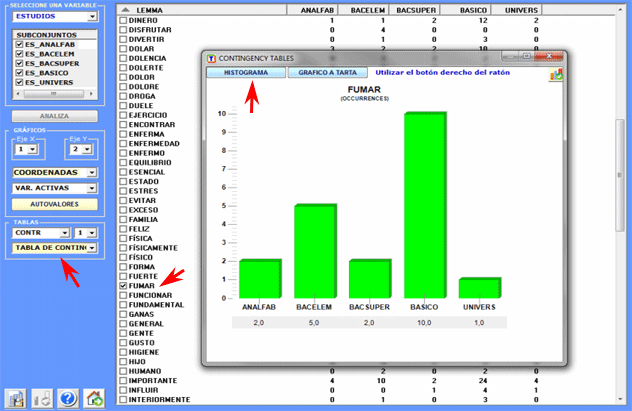
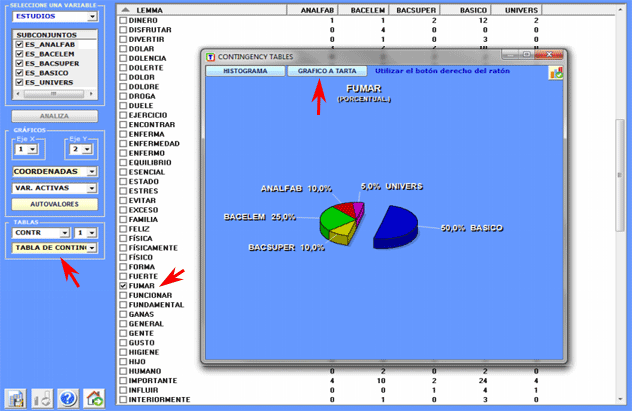
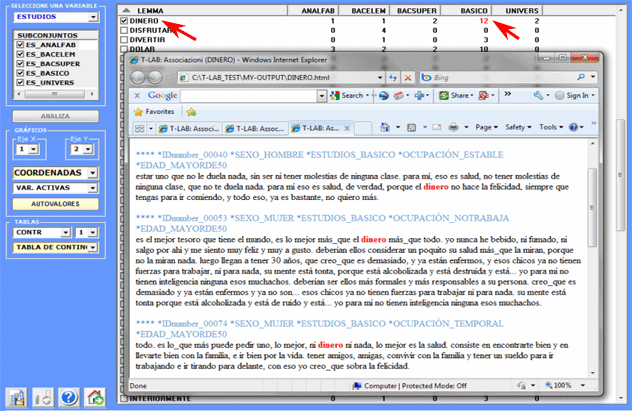
Además, sucesivamente es posible efectuar una Cluster Analysis.
En los análisis de tablas (B) y (C),
esas están constituidas por tantas líneas como las unidades de
contextos (max 10.000) y tantas columnas como palabras clave
seleccionadas (max 3.000).
El algoritmo de
cálculo y los output son análogos a los del análisis unidades
lexicales por variables, sólo que - en este caso - para limitar el
tiempo de elaboración, T-LAB se limita a extraer los 10
primeros factores: un número más que suficiente para resumir la
variabilidad de los datos.
|


