|
www.tlab.it
Concordancias
Esta herramienta de T-LAB nos permite
comprobar los contextos de ocurrencia de cada unidad
lexical.
Las búsquedas del tipo KWIC (Key-Word in Context)
pueden ser realizadas tanto por palabras que por lemas (véase abajo la opción '2'). Además, dichas
búsquedas peuden ser implementadas bien en todo el corpus o bien sólo en un subconjunto del (véase abajo la opción
'1').
Además es posible definir la gama de las
ocurrencias a visualizar (véase abajo la opción
'3').
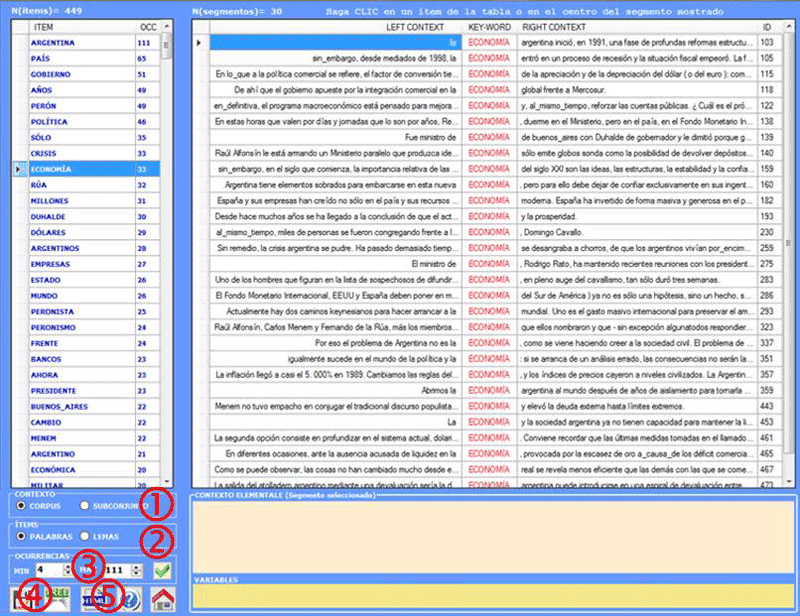
Para cada unidad lexical del corpus, con un simple
clic en la columna correspondiente, es posible comprobar cuáles son
sus contextos de ocurrencia (los contextos
elementales); además, es posible crear un Word Tree dinámico (véase abajo la '4') o guardar
un archivo HTML con todos los contextos seleccionados (véase abajo
la la opción '5').


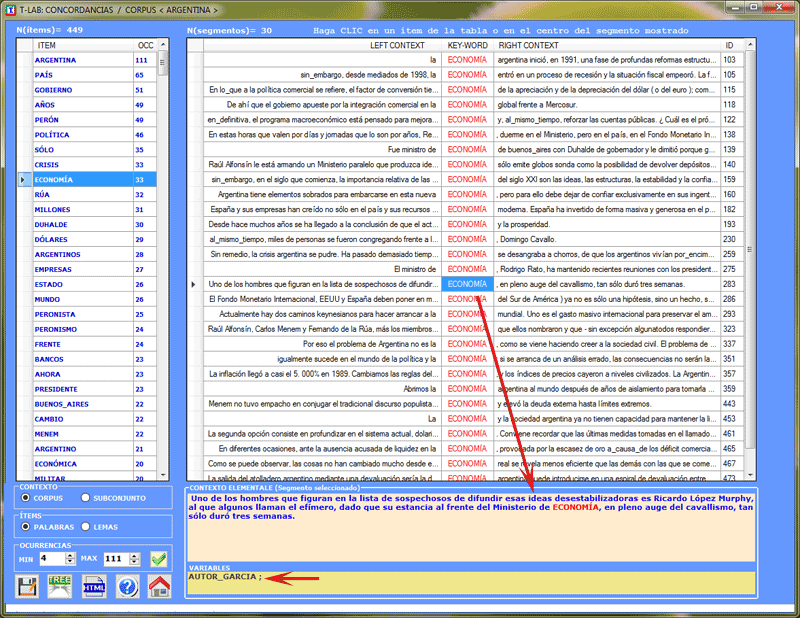
Por otra parte, chascando el centro de un segmento es posible
visualizar su contenido y comprobar los categorías usadas en sus
líneas de codificación (véase abajo).
|


