|
www.tlab.it
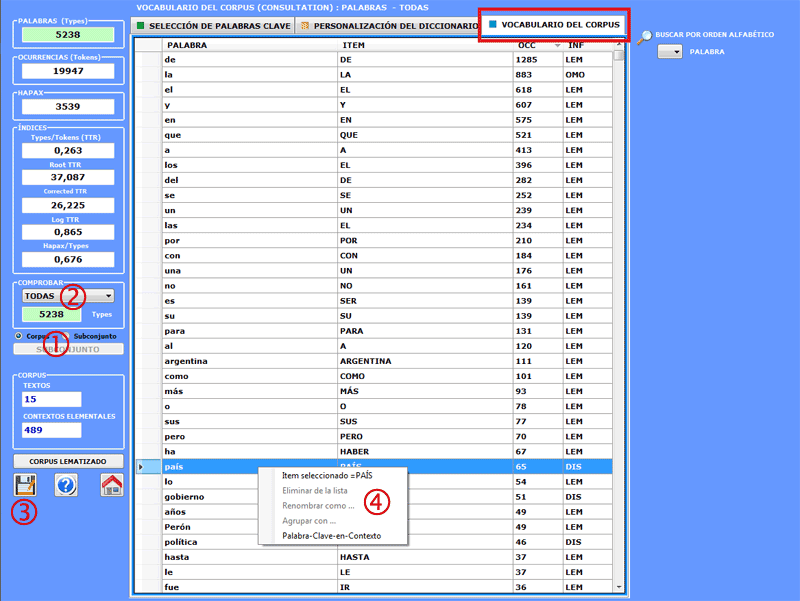
Vocabulario
Esta herramienta de T-LAB nos
permite comprobar el Vocabulario del corpus y de sus subconjuntos
(véase abajo la opción '1').
Por otra parte se proporcionan algunas medidas de riqueza léxica.
La tabla Vocabulario es una lista
que incluye todas las palabras distintas (es decir "word types"),
la cantidad de sus ocurrencias (es decir "word tokens"), los
lemas correspondientes y algunas
categorías usadas por T-LAB (véase Glosario/Lematización).
El usuario puede seleccionar (véase
abajo la opción '2') las unidades léxicas que pertenecen a cada
categoría, consultar la tabla correspondiente y exportarla como
archivo .xls (véase abajo la opción '3').
Además, usando el botón derecho del
ratón, es posible verificar las concordancias (Key-Word-in-Context) de cada
palabra (véase abajo la opción '4').
Las medidas de riqueza léxica son
cinco:
Type/Token ratio (TTR);
Root TTR (Guiraud, 1960), obtenida dividiendo el número de "types"
por la raíz cuadrada del número de "tokens";
Corrected TTR (Carroll, 1964), obtenida dividiendo el número de
"types" por la raíz cuadrada de dos veces el número de
"tokens";
Log TTR (Herdan, 1960), obtenida dividiendo el logaritmo del número
de "types" por el logaritmo del número de "tokens";
Hapax/Types ratio.
NOTA:
- Hapax (es decir Hapax Legomena) son las palabras que, en un
corpus, ocurren solamente una vez; - cuando se analiza un
subconjunto del corpus, todas las medidas de riqueza léxica no
incluyen las palabras vacias (e.j. los
artículos y las preposiciones).
|


