|
www.tlab.it
Cadenas de Markov
Una cadena markoviana está constituida por una
sucesión (o secuencia) de eventos,
generalmente indicados como estados,
caracterizada por dos propiedades:
- el conjunto de los eventos y de sus posibles resultados
es finito;
- el resultado de cada evento depende sólo (o al máximo) del evento
inmediatamente anterior.
Con la consecuencia de que a cada transición de un evento a otro le corresponde un
valor de probabilidad.
En el ámbito científico, el modelo de las cadenas
markovianas se utiliza para analizar las sucesiones de eventos
económicos, biológicos, físicos, etc. En el ámbito de los estudios
lingüísticos sus aplicaciones tienen como objeto las posibles
combinaciones de las varias unidades de análisis en el eje de las
relaciones sintagmáticas (una unidad tras otra).
En T-LAB el
análisis de las cadenas markovianas concierne dos tipos de
secuencias:
" las relativas a las relaciones entre unidades lexicales
(palabras, lemas o categorías) presentes en el corpus en
análisis;
" las presentes en archivos externos predispuestos por el
usuario.
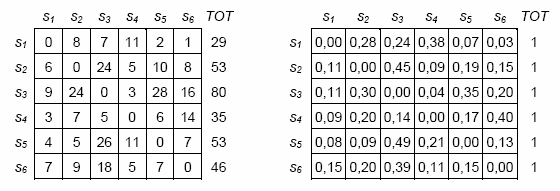
En ambos casos, en primer lugar se crean tablas cuadradas
en las que se representan las ocurrencias de las transiciones, o
sea cantidades que indican el número de veces en las que una unidad
de análisis precede (o sigue) a la otra. Sucesivamente, las
ocurrencias de las transiciones se transforman en valores de
probabilidad (ver imágenes siguientes).
Para más información véase el Análisis de Secuencias.
|


