|
www.tlab.it
Multidimensional Scaling (MDS,
Escalamiento Multidimensional)
Conjunto de técnicas estadísticas que permiten analizar
matrices de semejanza para proporcionar una representación visual
de las relaciones entre los datos dentro uno espacio de dimensiones
reducidas.
En T-LAB un tipo de MDS (método de Sammon)
se utiliza para representar las relaciones entre las unidades
lexicales o entre los núcleos temáticos (véase Análisis de Co-Palabras y Modelización de Temas Emergentes).
Las tablas de input se constituyen de matrices cuadradas
que contienen los valores de proximidad (desemejanzas) derivados
del cálculo de un índice de
asociación.
Los resultados obtenidos, como los del análisis de correspondencias, nos permiten
interpretar las relaciones entre los "objetos" y las dimensiones
que organizan el espacio en el cual se representan.
El grado de correspondencia entre las distancias,
entre los puntos obtenidos por el mapa de MDS y aquellos de la
matriz input, es medido (inverso) por una función de stress. Cuanto menor es el valor de lo stress
(e.g. < 0,10), tanto mayor es la calidad del ajuste
obtenido.
La fórmula de stress es la
siguiente:
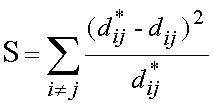
Donde 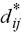 representa las
distancias entre los puntos (ij) de la matriz input y
representa las
distancias entre los puntos (ij) de la matriz input y 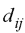 representa las
distancias entre los mimos puntos en el mapa MDS.
representa las
distancias entre los mimos puntos en el mapa MDS.
|


