|
www.tlab.it
Índices de
Asociación
En T-LAB los índices de asociación
(o de similitud) se utilizan para analizar las co-ocurrencias de
las unidades lexicales (LU,
lexical units) en el interior de los contextos elementales (EC, elementary
contexts), es decir datos binarios del tipo
presencia/ausencia.
Por ejemplo, dadas dos LU y diez EC, se
puede crear el siguiente ejemplo
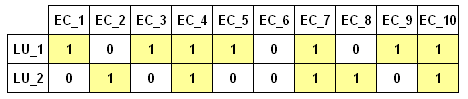
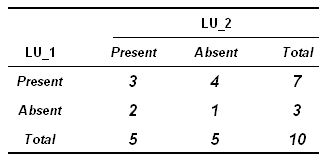
Los mismos datos se pueden representar del
siguiente modo:
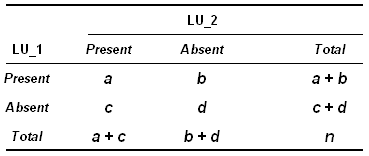
Generalizando y usando las letras del
alfabeto:
Las fórmulas correspondientes a los seis índices de
asociación usados por T-LAB son las siguientes:
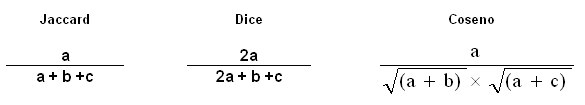
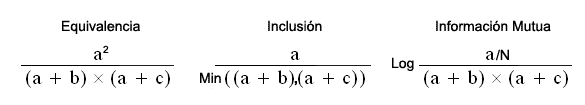
Suponiendo que se han obtenido los coeficientes de
las relaciones entre diez LU, podemos crear unatabla como la
siguiente:
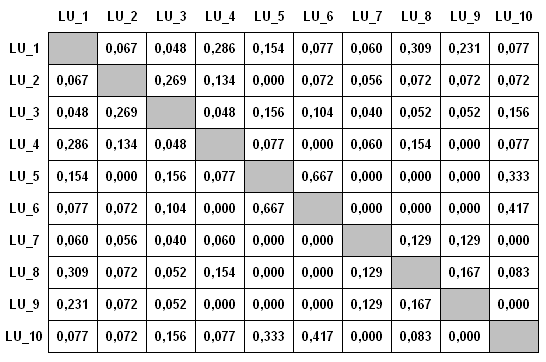
De hecho, T-LAB crea y analiza tablas
análogas de dimensiones N x N (en la que N puede corresponder a
varios centenares de columnas), tanto con Multidimensional Scaling como con Cluster Analysis.
Las mismas tablas se utilizan también para calcular
los índices de semejanza de segundo
orden asociados a las parejas de palabras claves (véase
herramienta de Asociaciones de
Palabras).
|


