|
www.tlab.it
Ocurrencias y
Co-ocurrencias
En análisis de textos, estos dos conceptos son de
importancia fundamental.
Las ocurrencias, en efecto,
son las cantidades que resultan del cómputo de cuántas veces
(frecuencias) cada unidad lexical (LU,
lexical unit) se repite dentro del corpus
o dentro las unidades de contexto (CU,
context units) que lo constituyen.
Su distribución se puede representar en tablas de
contingencia como la siguiente
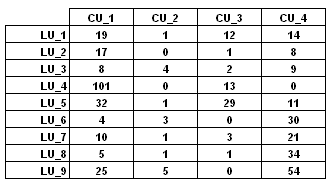
Las co-ocurrencias son
las cantidades que resultan del cómputo del número de veces que dos
o más unidades lexicales están presentes contemporáneamente en los
mismos contextos elementales (EC,
elementary context).
Su distribución se puede representar en tablas como la
siguiente
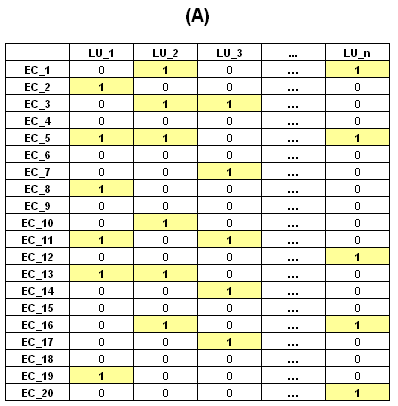
Con una simple
transformación, las tablas del tipo "A" (rectangular) pueden
transformarse en tablas del tipo "B" (cuadradas y simétricas) en
las que para cada pareja de unidad lexical está indicada la
cantidad de sus co-ocurrencias, es decir el total de contextos
elementales en los que están contemporáneamente presentes.
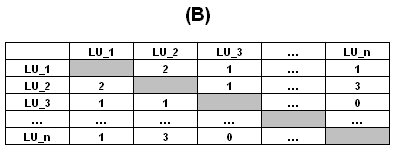
En gran medida - en T-LAB - el análisis de textos se realiza
mediante el estudio de las relaciones entre ocurrencias y entre
co-ocurrencias, tanto con índices de
asociación específicos, o con el uso de técnicas estadísticas
multidimensionales como el cluster
análisis y el análisis de
correspondencias.
|


