|
www.tlab.it
Palabras Asociadas y Mapas
Conceptuales
 NOTA: Las imagenes contenidas en este apartado hacen
referencia a una versión anterior de T-LAB, ya que el interfaz de
T-LAB 10
cambia ligeramente. Además: a) si se escoge la opción 'selección
automática de las palabras clave', los diferentes clústeres de
elementos vienen representados en los mapas MDS con colores diferentes; b) se ha agregado la
técnica de visualización llamada t-SNE (t-Distributed Stochastic
Neighbor Embedding); c) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; d) el uso del
botón derecho del ratón sobre las
tablas que incluyen las palabras clave permite acceder a las las
opciones avanzadas; e) una galería de imágenes de acceso rápido que
funciona como un menú adicional permite cambiar entre varias
salidas con un solo clic. NOTA: Las imagenes contenidas en este apartado hacen
referencia a una versión anterior de T-LAB, ya que el interfaz de
T-LAB 10
cambia ligeramente. Además: a) si se escoge la opción 'selección
automática de las palabras clave', los diferentes clústeres de
elementos vienen representados en los mapas MDS con colores diferentes; b) se ha agregado la
técnica de visualización llamada t-SNE (t-Distributed Stochastic
Neighbor Embedding); c) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; d) el uso del
botón derecho del ratón sobre las
tablas que incluyen las palabras clave permite acceder a las las
opciones avanzadas; e) una galería de imágenes de acceso rápido que
funciona como un menú adicional permite cambiar entre varias
salidas con un solo clic.
Algunas de
estas nuevas características se destacan en la imagen de
abajo.
Esta herramienta T-LAB permite analizar dos tipos de relaciones
concernientes las co-ocurrencias de
palabras:
A - entre las palabras-clave seleccionadas (lemas o categorías), si
sus cantidad no excede los 500 elementos (mínimo
10);
B - entre (y dentro) clusters (es
decir Núcleos Temáticos), si la cantidad
de palabras-clave seleccionadas excede
los 100 elementos (máximo 3.000).
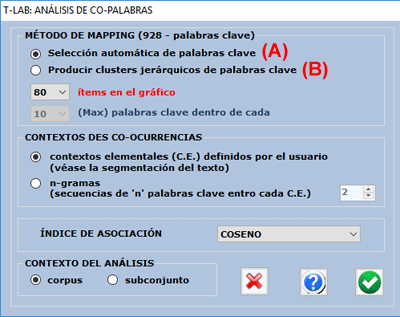
El usuario puede seleccionar el índice de asociación a ser utilizado y, sólo en
el caso de la opción B, puede seleccionar tanto la cantidad máxima
de clusters a obtener (de 50 a 100) como la cantidad máxima de
palabras clave por cluster.
El proceso de cálculo empleado prevé
los pasos siguientes:
1-
construcción de una matriz de co-ocurrencias (palabra x palabra);
2- cálculo de los índices de asociación seleccionados (Coseno,
Dice, Jaccard, Equivalencia, Inclusión, Información
Mutua);
3-
clustering jerárquico de la matriz de la
desemejanza;
4- construcción de una segunda matriz de co-ocurrencias (cluster x
cluster);
5- representación gráfica de las relaciones a
través del multidimensional scaling y del
análisis de
correspondencias.
N.B:
- en el caso 'A' (véase arriba), el usuario puede revisar y
personalizar la selección de las palabras-clave (véase imagen
siguiente) y T-LAB
no implementaría las fases 3 y 4;
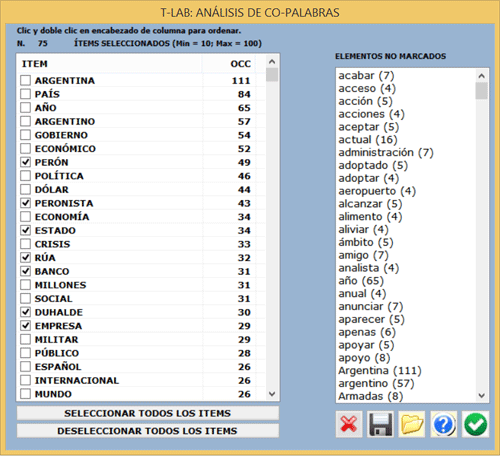
- la calidad de resultados depende de una cuidadosa
selección de palabras clave;
- puesto que las multi-palabras
(multiwords) no catalogadas por T-LAB son casos específicos de
co-ocurrencia y que la opción "B" trata esos como unos pequeños
racimos (ej. "Twin" + "Towers"), se aconseja de resolver estos
casos durante la fase de importación.
En todo caso, sin la repetición de la importación del corpus, es
posible realizar cambios por medio de la función Personalización del Diccionario (ej. asignando
la etiqueta "Twin_Towers" a los dos diversos items "Twin" +
"Towers");
- haciendo clic sobre los botones apropiados todas las tablas de
datos pueden ser comprobadas (véase abajo).
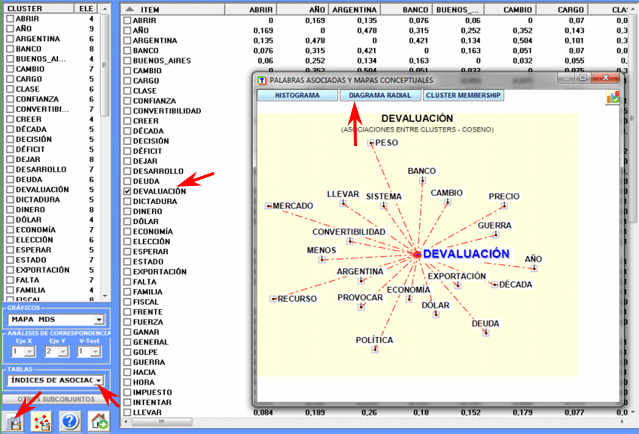
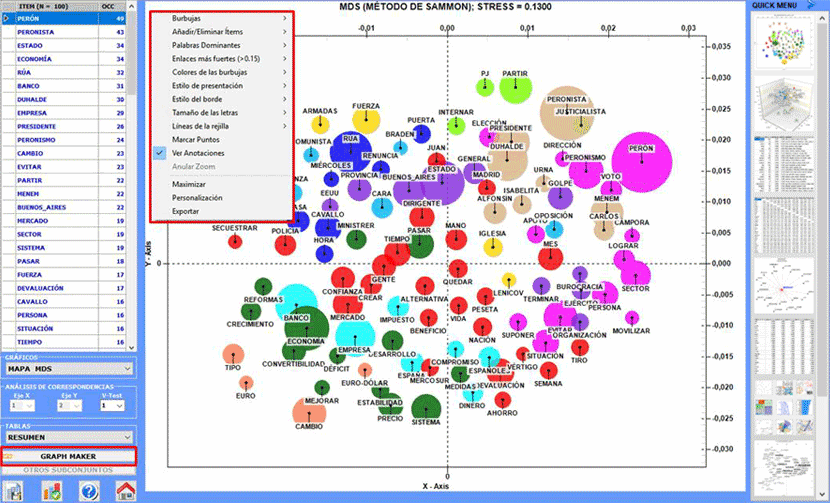
Al término del análisis automático, están
disponibles cuatro tipos de gráficos que pueden ser personalizados
utilizando el botón derecho del ratón.
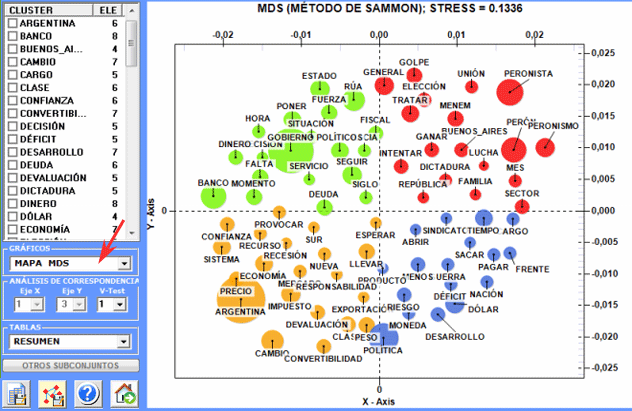
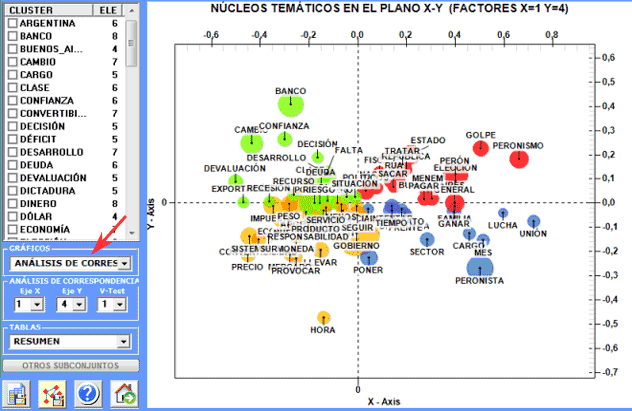
1 - Mapa MDS
2 - Análisis Factorial de
Correspondencias
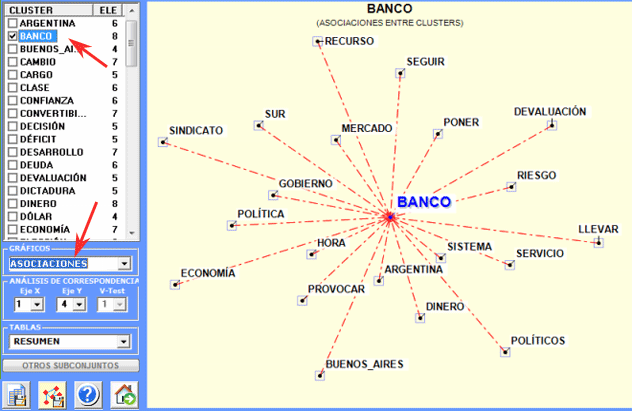
3 - Diagrama de Asociaciones
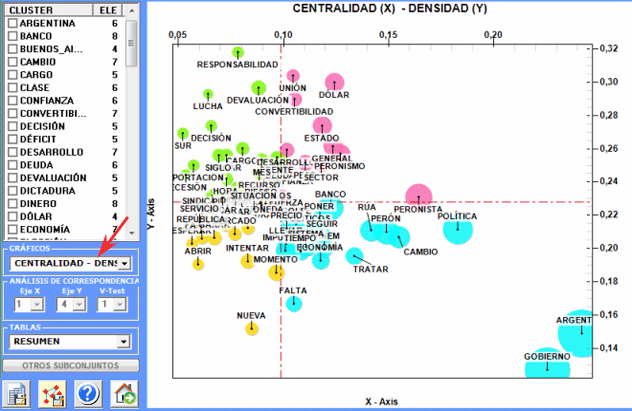
4 - Mapa con las medidas de Centralidad y
Densidad (solo después de un cluster análisis)
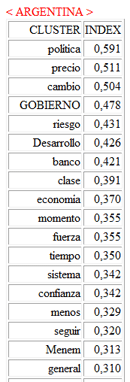
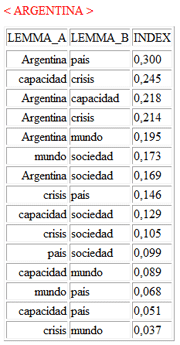
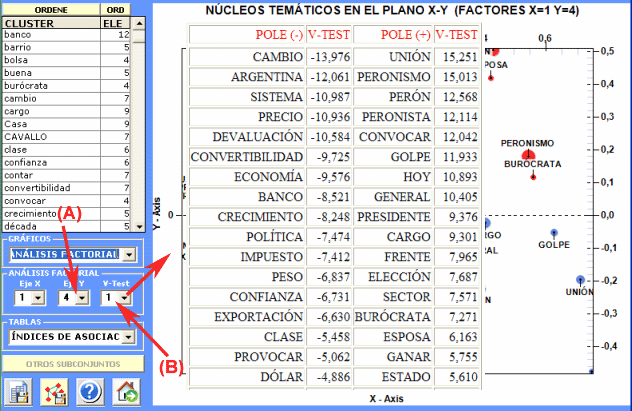
En detalle, los resultados obtenidos por
el
Análisis de
Correspondencias se pueden
visualizar usando las coordenadas de los primeros diez ejes (véase
"A" abajo). Puesto que T-LAB nos permite
verificar los Valores Test de cada factor
(véase "B" abajo), esto tipo de output se puede utilizar para una
cuidadosa interpretación de las relaciones entre clusters y/o entre
palabras clave.
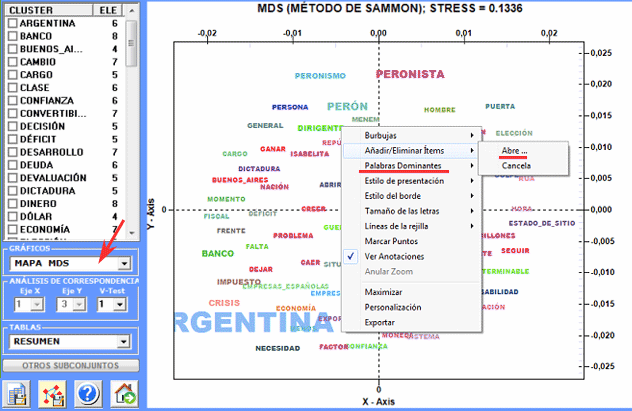
Los gráficos pueden ser explorados y modificados de
las maneras siguientes:
|
ACCIÓN
|
RESULTADO
|
|
clic en un ítem de la tabla o en un punto del
gráfico
|
diagrama de las asociaciones
correspondientes
|
|
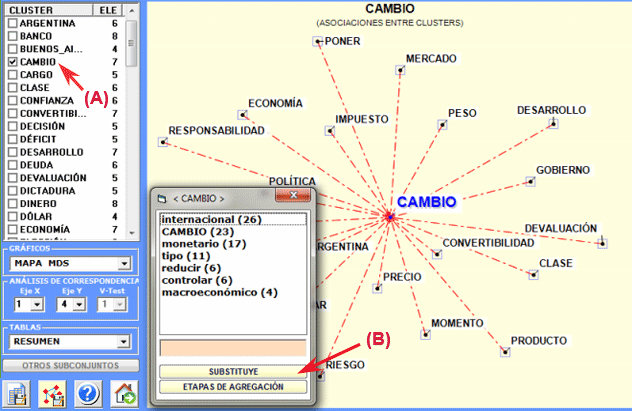
clic en una etiqueta de la columna "CLUSTER"
(véase "A" abajo)
|
lista con los elementos del cluster
|
|
clic en el botón "Substituye" (véase "B"
abajo)
|
nueva etiqueta atribuida al cluster
|
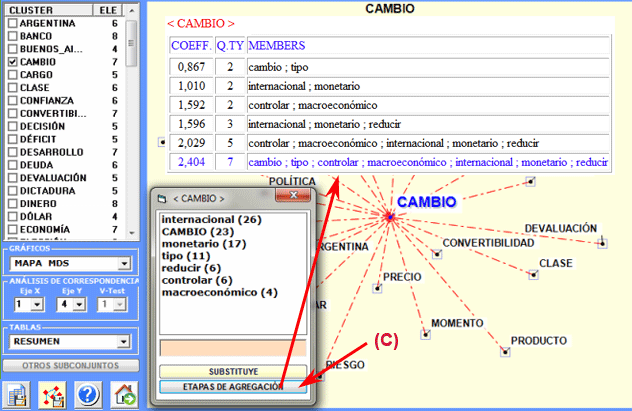
|
clic en el botón "Etapas de agregación" (véase
"C" abajo)
|
agregaciones en el cluster
|
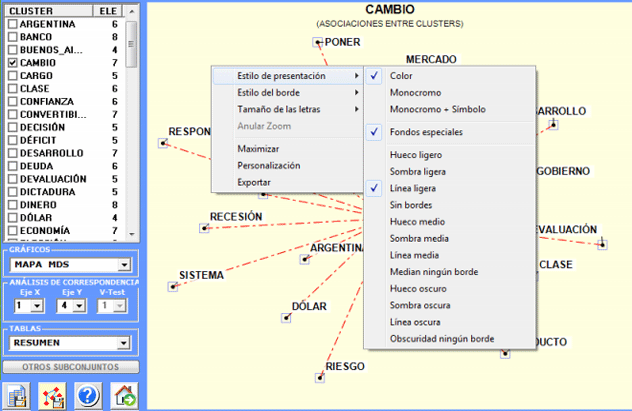
|
clic en botón derecho del ratón
|
caja de diálogo para personalizar los
gráficos
|
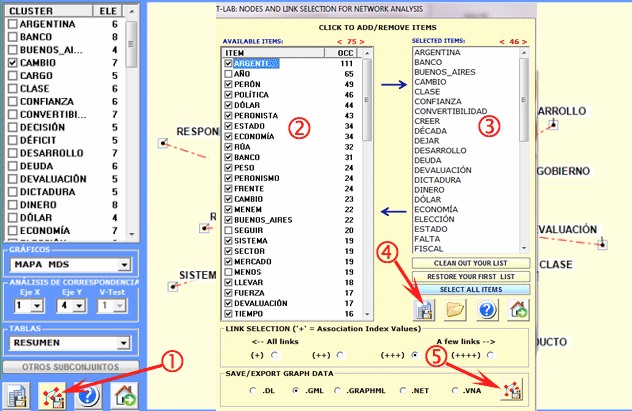
Otra ventana T-LAB (véase
ventana siguiente, paso 1) permite crear archivos gráficos que
pueden ser editados mediante los softwares para el network analysis, como Gephi, Pajek,
Ucinet, yEd entre otros. En este caso, las opciones disponibles son
las siguientes: seleccionar los ítems (es decir, los nudos) a
insertar en los gráficos (véase abajo, pasos 2 y 3), exportar la
matriz de adyacencia correspondiente (véase abajo, paso 4),
exportar el tipo de archivo seleccionado (véase abajo, paso
5).
NOTA: En T-LAB 10
la ventana que se muestra a continuación ha sido sustituida por la
herramienta Graph Maker.
Por ejemplo, un archivo en formato .GML exportado
por T-LAB permite
realizar un grafico como el siguiente.

Hay tres tipologías de tablas exportables a través
de esta herramienta de T-LAB:
1 - la tabla "Miembros" se refiere a la agregación
jerárquica de palabras dentro de cada cluster;
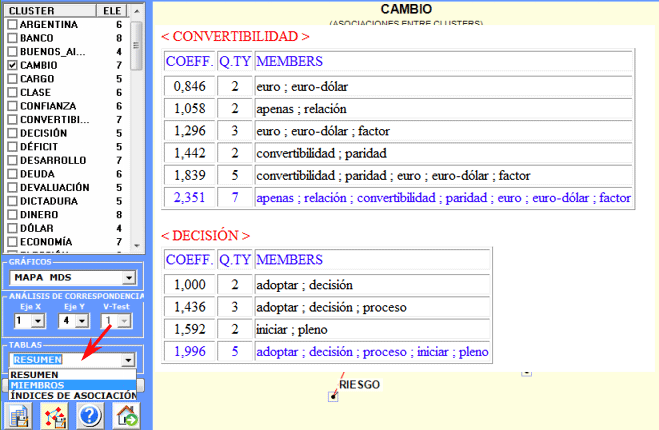
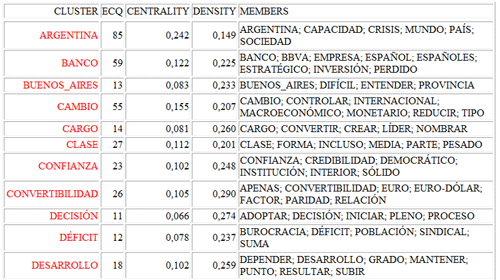
2 - la tabla "Resumen" (véase abajo) incluye
las medidas siguientes:
- ECQ = cantidad de contextos elementales en los
cuales dos o más palabras del cluster son co-ocurrentes;
- Centrality (Centralidad) = media de índices de asociación
referentes a las relaciones entre clusters;
- Density (Densidad) = media de índices de asociación de palabras
dentro de cada cluster.
3 - la tabla "Índices de asociación" (véase
abajo) incluye medidas de las relaciones de semejanza entre
(between) y dentro (within) los clusters.
N.B.:
- cuando un
cluster análisis no se ha hecho, la tabla "Miembros" no está
disponible, la tabla "Resumen" se simplifica y la tabla "Índices de
asociación" se refiere solamente a las co-ocurrencias de
palabras;
- al final del análisis, el diccionario de Núcleos
Temáticos (es decir la lista de las etiquetas asignadas a cada
cluster de las palabras) se puede exportar y, después de una
cuidadosa revisión, puede ser importado por medio de la función
Personalización del Diccionario.
De esta manera el usuario
podrá realizar algunos análisis de segundo orden (es decir análisis
concernientes "temas" o "conceptos").
|