|
www.tlab.it
Cluster Analysis
 NOTA: Las imagenes contenidas en este apartado hacen
referencia a una versión anterior de T-LAB, ya que el interfaz de
T-LAB 10
cambia ligeramente. Además: a) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; b) el botón
dendrograma ha sido sustituido por la
herramienta Graph Maker; c) una galería de imágenes de acceso
rápido que funciona como un menú adicional permite cambiar entre
varias salidas con un solo clic. NOTA: Las imagenes contenidas en este apartado hacen
referencia a una versión anterior de T-LAB, ya que el interfaz de
T-LAB 10
cambia ligeramente. Además: a) una nueva herramienta (Graph Maker) permite crear y exportar diferentes
tipos de gráficos dinámicos en formato HTML; b) el botón
dendrograma ha sido sustituido por la
herramienta Graph Maker; c) una galería de imágenes de acceso
rápido que funciona como un menú adicional permite cambiar entre
varias salidas con un solo clic.
La opción Cluster Análisis
pone en marcha un cómputo que utiliza los resultados de un
precedente análisis de correspondencias;
más concretamente, el cómputo utiliza las coordenadas de los
objetos ( unidades lexicales o unidades de contexto) en los
primeros ejes factoriales (hasta un máximo de 10).
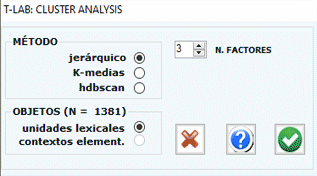
Según los casos, el usuario puede elegir entre tres
técnicas de cluster analysis:
a) jerárquica (método Ward);
b) K-means (método MacQueen);
c) hdbscan (hierarchical DBSCAN).
Las dos primeras (a, b) permiten explorar (tablas y
gráficos) soluciones de 3 a 20 cluster; mientras que la tercera
(c), que requiere un parámetro adicional (es decir, el número
mínimo de palabras dentro de un clúster), permite al usuario
explorar solo una solución.
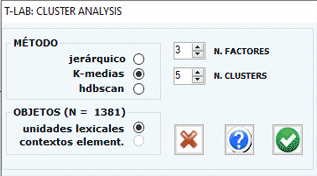
NOTA: Cuando se utilisa el método jerárquico
T-LAB hace disponible una
opción (véase el botón 'Refinar') que permite al usuario combinar
los métodos de Ward y K-means.
Una breve descripción de las tres técnicas está contenida
en el glosario de este manual.
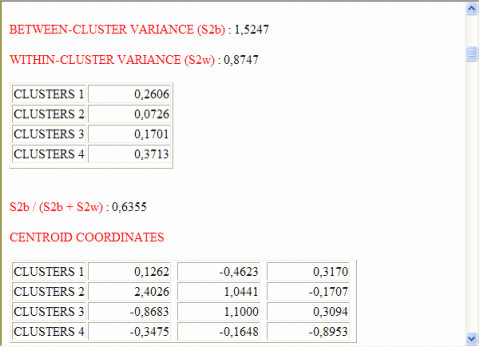
Al término de proceso, T-LAB muestra
gráficos y tablas.
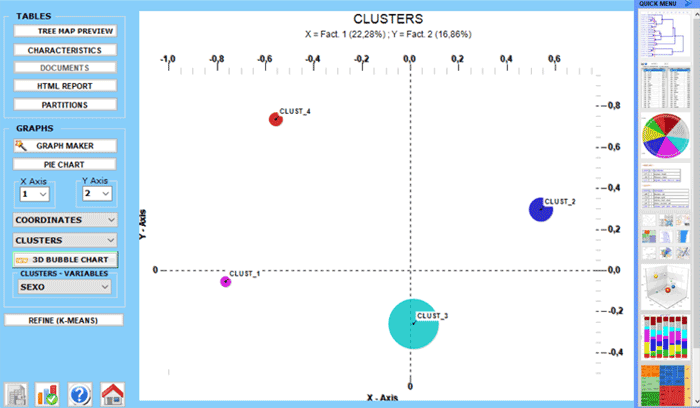
Los gráficos representan los clusters (racimos) en
el mismo espacio detectado por el análisis de correspondencias
(véase abajo).
NOTA: Para explorar las varias combinaciones de los
ejes factoriales, es suficiente seleccionarlos en los boxes
apropiados ("Eje X", "Eje Y").
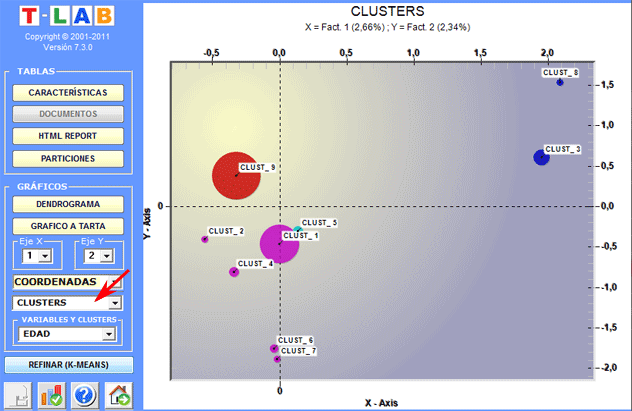
En el caso de clusterización jerárquica, el usuario
puede explorar fácilmente las particiones diferentes.
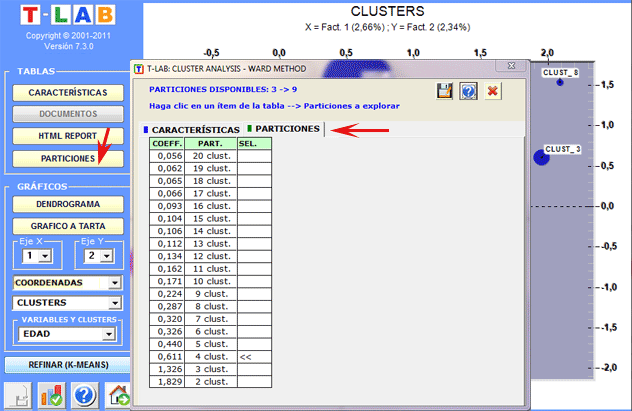
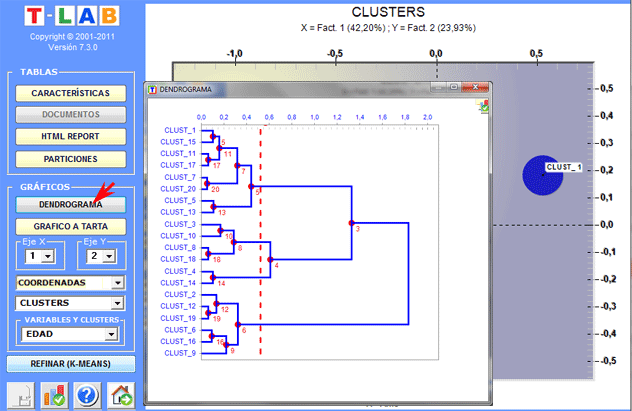
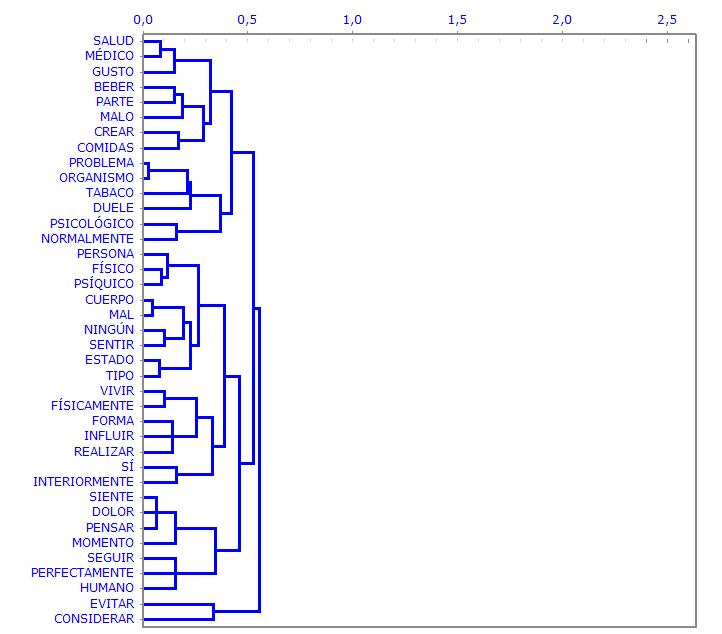
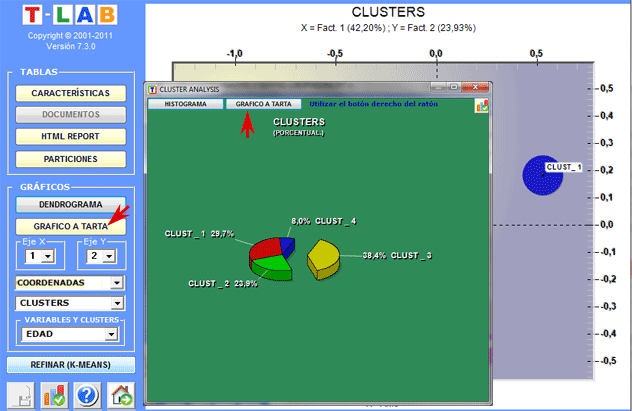
Dendrogramas, gráficos a tarta y histogramas permiten verificar las
características de cada partición.
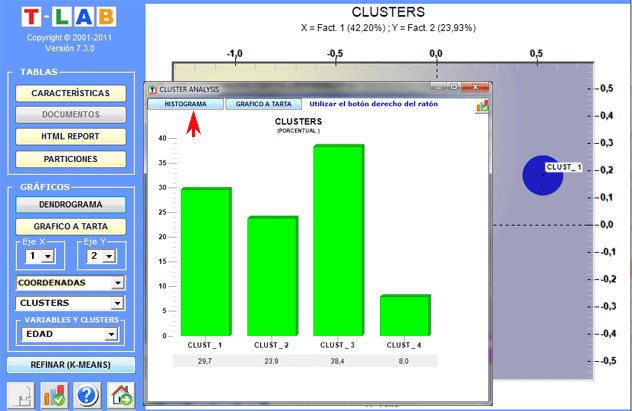
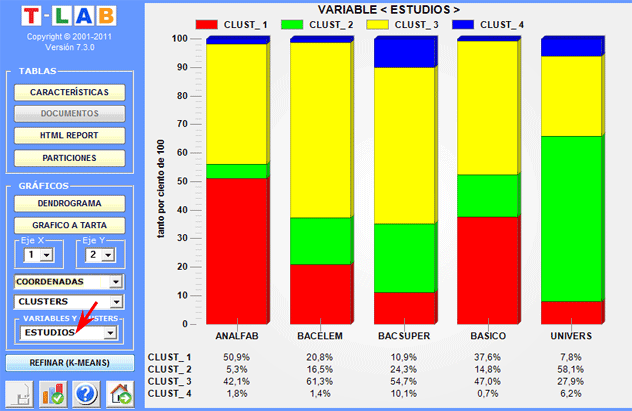
Algunos histogramas nos permiten verificar las
relaciones entre los clusters y las variables.
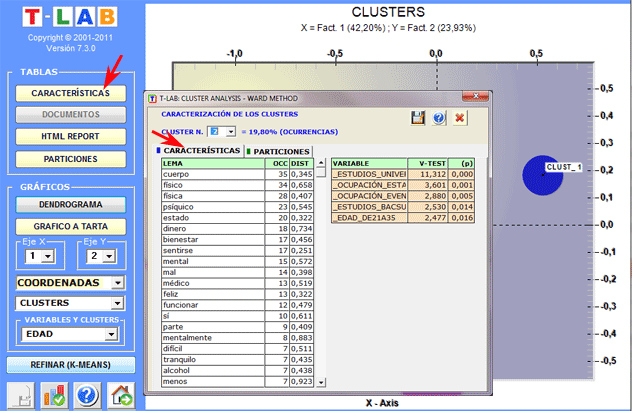
Las tablas son de dos tipos:
(A) si los objetos
arracimados son unidades
lexicales, por cada una de ellas (y por cada cluster) se exhiben
las ocurrencias respectivas ('OCC') y las distancias ('DIST')
respectivas de los centroides; también, por cada variable que se
asocie significativamente al cluster examinado, se exhibe el valor
respectivo del Valor
Test.
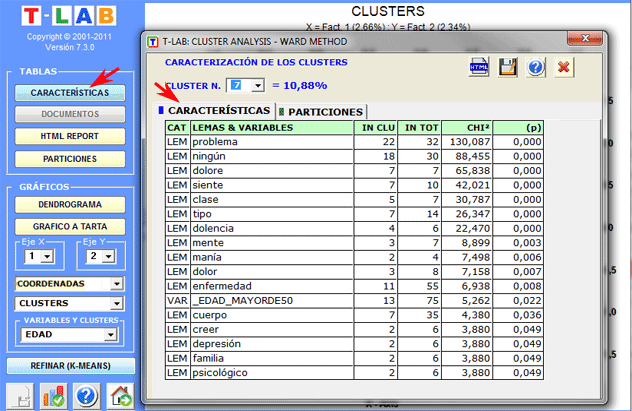
(B) si los
objetos arracimados son contextos elementales, las características
de cada cluster (las unidades lexicales y las
variables) se describen por medio del mismo método usado en
Análisis Temático de Contextos
Elementales (véase abajo).
En el caso de análisis realizados con métodos
jerárquicos o K-means T-LAB
permite visualizar y exportar un archivo (ver botón "Output HTML")
en el que se muestran las características de los cluster y algunas
medidas relativas a la calidad de la partición en estudio.
|