|
www.tlab.it
Contextos
Elementales
Durante la fase de la importación, T-LAB lleva a
cabo una segmentación del corpus en contextos elementales, para facilitar
las exploraciones del usuario y, sobre todo, para efectuar los
análisis que requieren el cómputo de las co-ocurrencias.
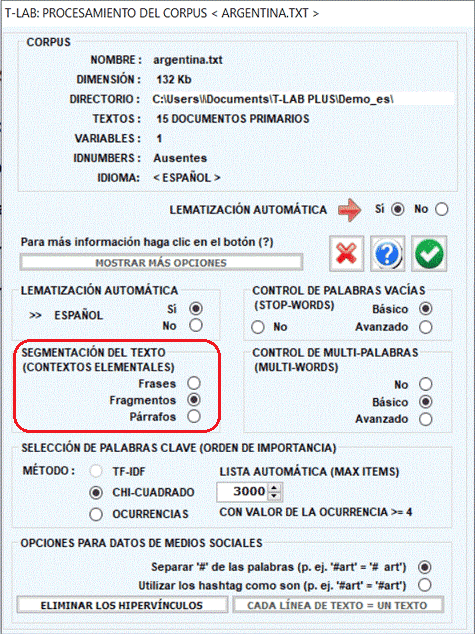
Según la elección del usuario, los contextos
elementales pueden ser:
1 - Frases
Contextos elementales que terminan con signos de
puntuación (.?!) y que no superan longitud máxima de 1.000
caracteres.
2 - Fragmentos
Contextos elementales de longitud comparable y compuestos
de uno o más enunciados.
En este caso, las reglas de segmentación usadas por
T-LAB son las
siguientes:
- considerar como contexto elemental cada
secuencia de palabras interrumpida por el punto y a parte y cuyas
dimensiones sean inferiores a la longitud de 400
caracteres;
- en el caso en el que, dentro de la longitud
máxima, no haya ningún punto y a parte, buscar, en el orden, otros
signos de puntuación (? ! ; : ,). Si no se encontraran, segmentar
en base a un criterio estadístico, pero sin truncar las unidades
lexicales.
3 - Párrafos
Contextos elementales que terminan con signos de
puntuación (.?!) y retorno del carro (longitud máxima: 2.000
caracteres).
4 - Textos
Breves
Esta opción se permite solamente cuando la longitud
máxima de textos no supera los 2.000 caracteres (por ejemplo, las
respuestas a preguntas abiertas).
NOTA:
- El fichero corpus_segments.dat contiene el resultado de
la segmentación del corpus;
- En T-LAB, la opción
concordancias permite verificar los
contextos elementales en los que está presente cada palabra (o
lema).
|


