|
www.tlab.it
Clasificación Temática de
Documentos
Esta función sólo está habilitada cuando el corpus en
análisis incluye un número de documentos primarios comprendido
entre un mínimo de 20 hasta un máximo de 99.999.
El proceso de análisis puede ser ejecutado o con un
método de clustering 'no supervisado' (en el caso concreto, un
algoritmo de bisecting K-Means) o con una clasificación supervisada
(es decir, un enfoque top-down). Cuando se elige la segunda vía, es
decir, la clasificación supervisada, se requiere la importación de
un diccionario de las categorías, bien creado por un anterior
análisis T-LAB, o bien
construido por el usuario.
Su uso permite construir clusters de documentos y
explorar sus características por medio de operaciones/opciones
similares a las descritas en la sección de la ayuda dedicada al
Análisis Temático de Contextos
Elementales.
Su especificidad consiste en el hecho de que la tabla
analizada se compone de tantas líneas como contenga el documento
del corpus, cada una de las cuales se representa como un vector de
valores que indican la ocurrencia de la palabra presente en el
mismo.
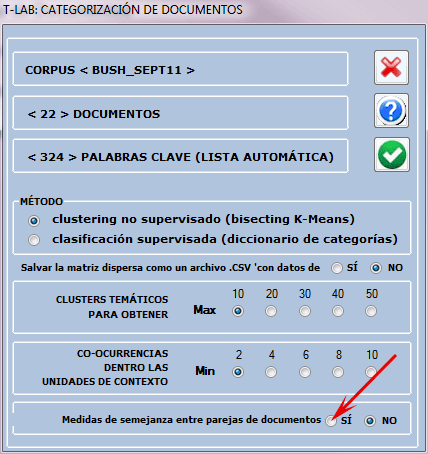
Además, cuando el número de documentos analizados no es
superior a 3000, es posible obtener medidas de semejanza (índice de
coseno) entre cada uno de ellos y todos los demás (véase abajo).
N.B.: En este caso el nivel mínimo de aceptación del índice de
semejanza está fijado en 0.05.
Consecuentemente, los resultados específicos de esta
función son los siguientes:
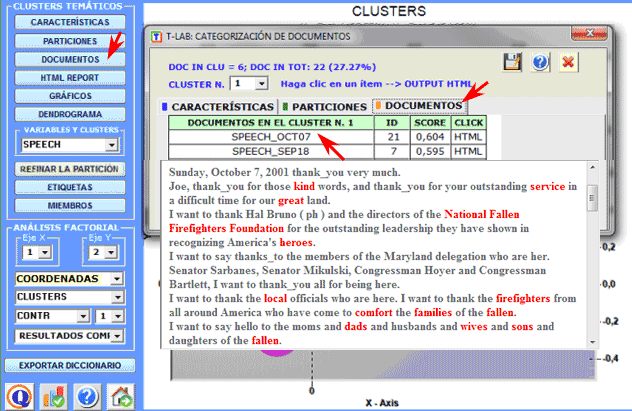
Los documentos que pertenecen a cada cluster son
ordenados por el valor decreciente de importancia y se pueden
examinar en formato HTML.
En este caso el valor de importancia
(score) asignado a cada documento (i) en el cluster (k) es obtenido
aplicando la fórmula siguiente:
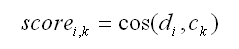
Donde:
i - se refiere al documento i;
k - se refiere al cluster k;
cos - es el símbolo del coseno;
di - es el vector normalizado de TFj, i IDFj, donde
j se refiere a una palabra del documento i;
ck- es el vector normalizado de TFj, k IDFj, donde
j se refiere a palabra del cluster k.
Usando los valores (scores) obtenidos por la fórmula
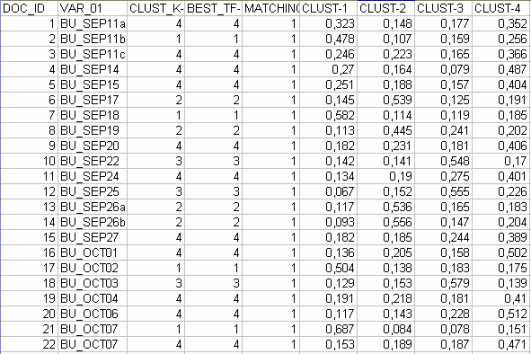
antedicha, que son transformados en porcentajes, T-LAB hace disponible el archivo "
Document_Membership_Degree.xls " (véase abajo) que contiene los
clusters a los cuales pertenecen los diferentes documentos, tanto
por el bisecting K-Means (donde cada documento pertenece
exclusivamente a un cluster) como por el TF-IDF (donde cada documento es caracterizado da
una pertenencia mezclada a varios clusters).
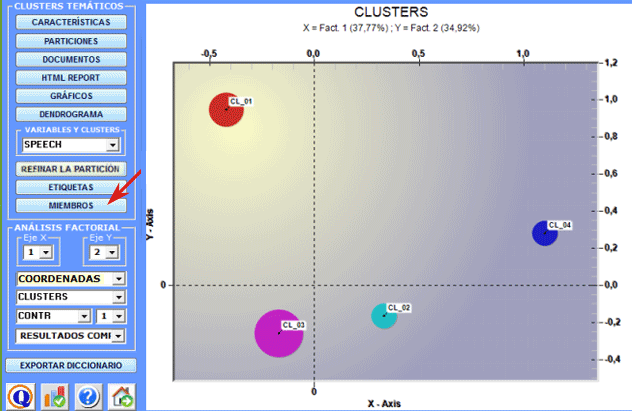
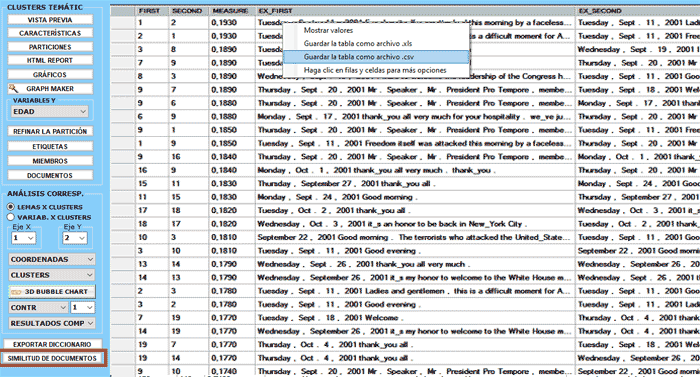
Cliqueando el botón Similitud de Documentos, tras haberlo habilitado,
se puede verificar en qué medida cada documento es similar a cada
uno de los demás. En este caso, la medida de semejanza es el
coeficiente de coseno, y su valor varía en función del número de
palabras utilizadas para la clasificación temática.
La imagen siguiente presenta las diferentes opciones
disponibles para este tipo de verificación.
A la salida de esta función, algunos mensajes recuerdan que es
posible explorar el cluster obtenido con otras herramientas
T-LAB.
Seleccionando la opción "GUARDAR", será posible utilizar
la variable < DOC_CLUST >
(cluster de documentos) en todos los sucesivos análisis del mismo
corpus realizados con otras herramientas T-LAB.
|



