|
www.tlab.it
Export Custom
Tables
 N.B.: The pictures shown in this section have been obtained
by using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10, but the
functionalities of the software are the same. N.B.: The pictures shown in this section have been obtained
by using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10, but the
functionalities of the software are the same.
This option allows us to create, to explore and to
export three kinds of tables:
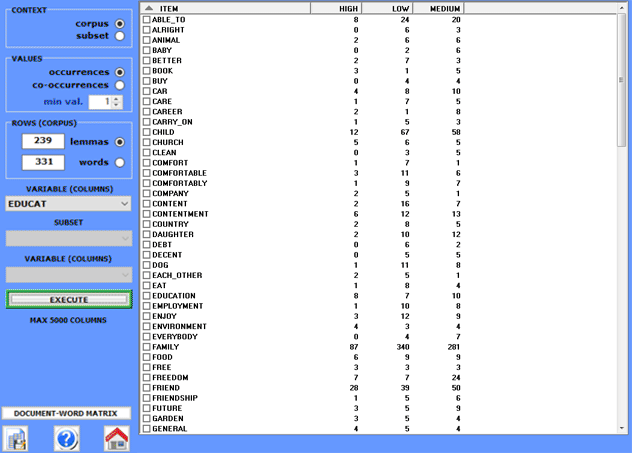
a) those with the occurrence
values of lexical units within the corpus subsets defined by a
categorical variable (rectangular matrices);
b) those with the co-occurrence values of lexical units (square
matrices) within the corpus or within the corpus subsets;
b) those with the co-occurrence values of lexical units within all
documents (sparse matrices using indexes).
The maximum sizes of such tables are respectively: a)
10,000 rows by 150 columns; b) 5,000 rows by 5,000 columns; c)
30,000 documents by 10,000 lexical units.
The use of this function is very intuitive.
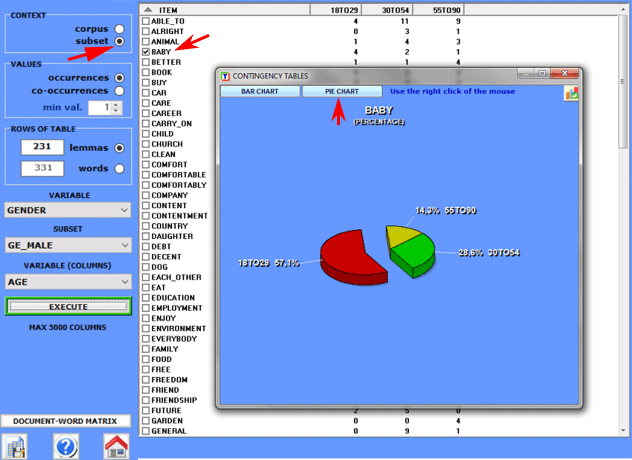
When dealing with simpler cases, you are asked to select
the variable one whose categories will constitute the columns of
the output table.
When dealing with more
complex cases, you are asked to select one variable and a
subset.
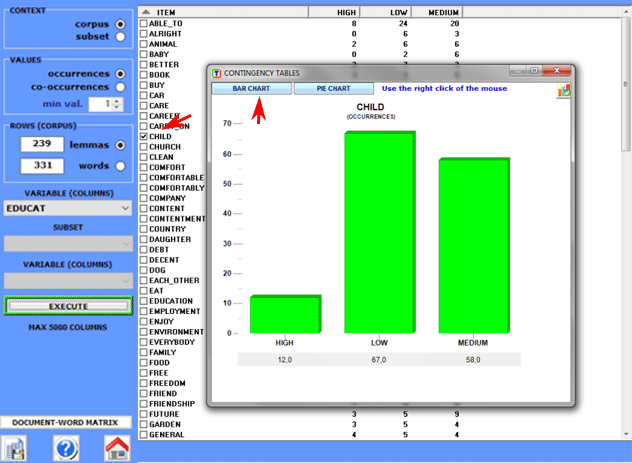
All contingency tables
allow us to create various charts.
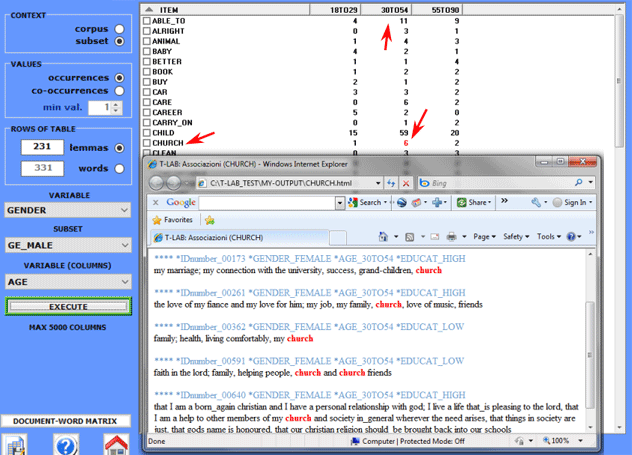
Moreover, by clicking on specific cells of a table, it is possible
to create a HTML file including all
elementary contexts where the word in row is present in the
corresponding subset (see below).
In order to export any sparse matrix document x word just click
the appropriate button (i.e. 'Document-Word Matrix').
In this case, the available outputs are two:
The first (Sparse_Matrix.csv) has the following format:
Doc_Index; Word_Index; Word_Occ
00001; 1; 12
00001; 2; 5
…..
The second (Word_Indexes.csv) has the following format:
Word_Index; Word_Label
1; abroad
2; accept
…..
|


