|
www.tlab.it
Comparison between Pairs of Key Words
 N.B.: The pictures shown in this section have been obtained by
using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. Also: a) a new
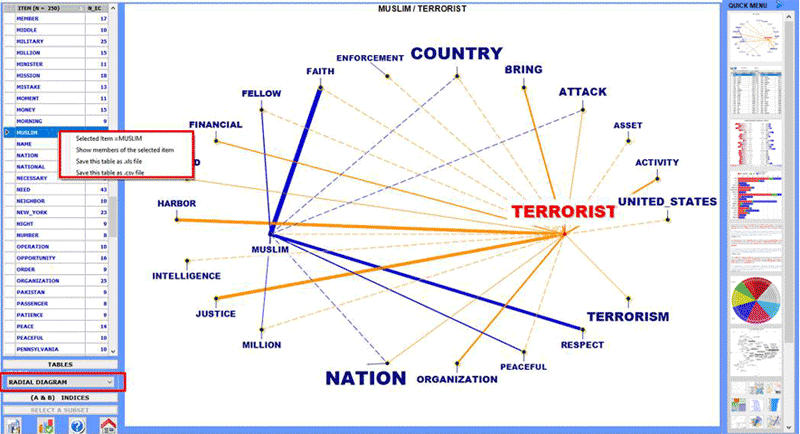
radial diagram is now available which
allows to quickly appreciate differences in word associations; b)
right clicking on the keyword tables
makes additional options available.
N.B.: The pictures shown in this section have been obtained by
using a previous version of T-LAB. These pictures look slightly different
in T-LAB 10. Also: a) a new
radial diagram is now available which
allows to quickly appreciate differences in word associations; b)
right clicking on the keyword tables
makes additional options available.
Some of these new features are highlighted in the below image; c) a
quick access gallery of pictures which works as an additional menu
allows one to switch between various outputs with a single
click.
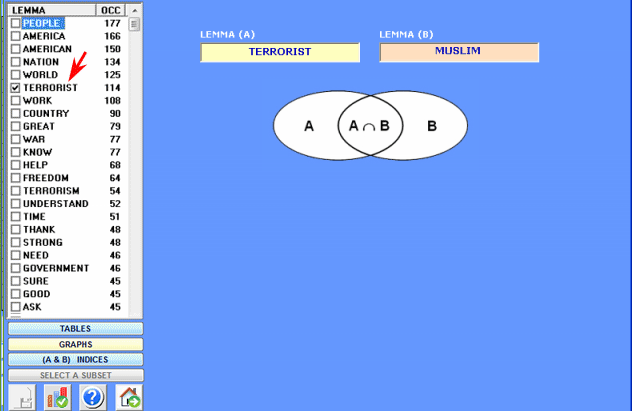
This T-LAB tool
allows us to compare sets of elementary
contexts (i.e. co-occurrence contexts) in which the elements of
a pair of key-words are present.
The table on the left shows the list of selected lemmas and their corresponding occurrence values within the whole corpus or a
subset of it.
The user is invited to select - one after the other - two of these
(a pair) with a single click (see below).
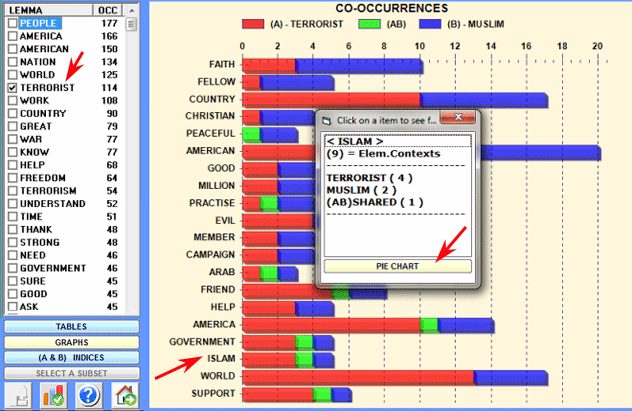
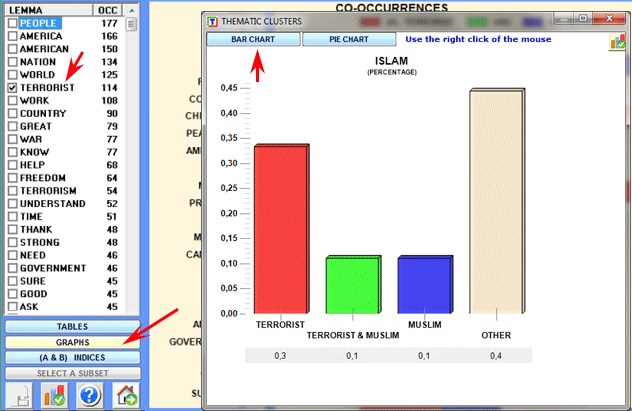
The bar chart (see below)
allows us to appreciate the number of elementary contexts in which
each lemma co-occurs with the "A" term (red colour), with the "B"
term (blue colour) and with both "A" and "B" (green colour).
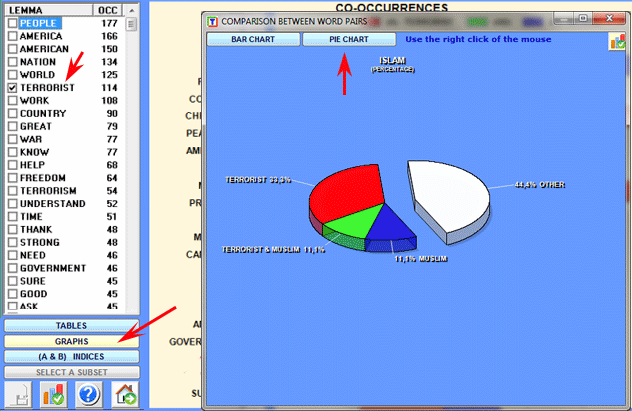
By double-clicking each label of the chart it is also possible to
check its corresponding co-occurrence values and obtain a pie chart
with the co-occurrences values concerning each selected word (see
below).
The comparisons provided by T-LAB involve the co-occurrences of the
elements in the "pair" and each of the words contained in the table
(see below).
Let:
A = set of elementary contexts
(TOT. E.C. = 86) in which the first word of the pair (e.g.
"Terrorist") is present;
B = set of elementary contexts (TOT. E.C. = 16) in which the second
word of the pair (e.g. "Muslim") is present.
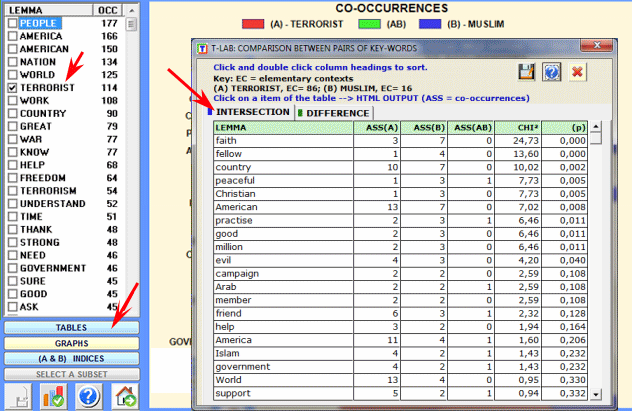
The first type of comparison concerns the shared associations (see the "intersection" button) and takes into account all
words which are present both in "A" and in "B".
In the output table (see above) every row shows the
values corresponding to the comparisons of each lemma.
The reading keys are as follows:
- ASS (A) = number of elementary contexts in which each
lemma is associated (i.e. co-occurrence) with (A);
- ASS (B) = number of elementary contexts in which each
lemma is associated with (B);
- ASS (AB) = number of elementary contexts in which each
lemma is associated with (A) and (B);
- CHI2 = Chi-square values;
- (p) = probability associated with the chi square value
(def=1).
In this case, for each key word (e.g. "country"),
T-LAB builds a table like the
one below and applies the Chi-square test
to it:
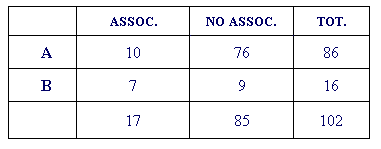
In this table:
- the (A) row shows the number of elementary contexts in which
"country" is present (10) or absent (76) in the set of contexts
(86) containing the first word of the pair ("Terrorist");
- the (B) row shows the number of elementary contexts in
which "country" is present (7) or absent (9) in the set of contexts
(16) containing the second word of the pair ("Muslim").
N.B.: In this case the Chi-square value is 10.02.
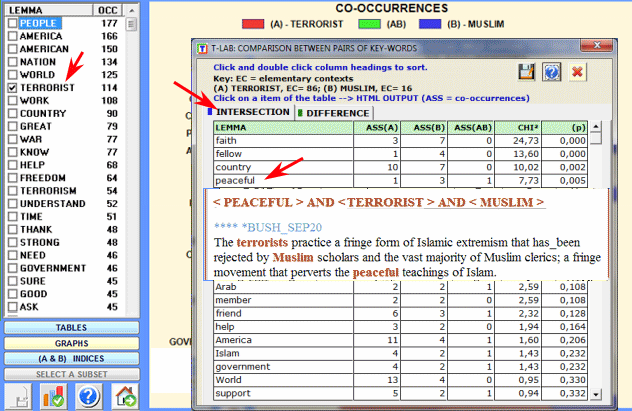
Moreover a double click on each item of the output table allows
us to save a HTML file with the number of elementary contexts in
the corresponding column.
The second type of comparison involves the differences between A and B (A-B and
B-A).
In this case T-LAB offers two
tables showing the key words which are exclusively associated with
the first (A) "or" second (B) word in the pair.
In both tables the "TOT" column shows the number of elementary
contexts in which each lemma is associated with only one of the two
terms of the pair.
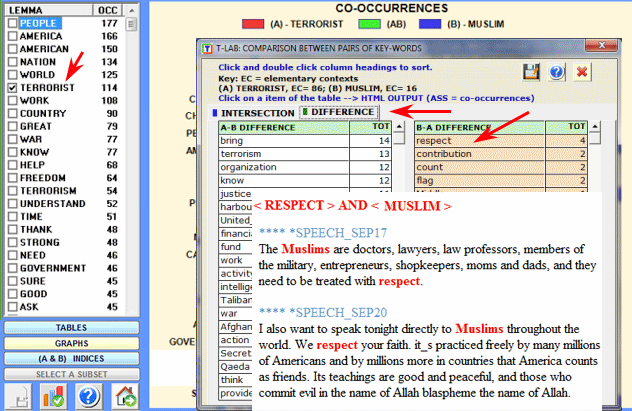
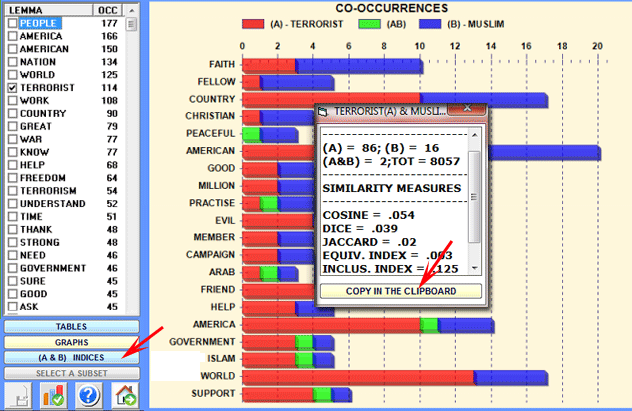
Eventually, by clicking the appropriate buttons (see the
picture below) it is possible to check and export all similarity
indexes concerning any word pair.
|


